台湾国立大学机器学习基石.听课笔记(第四讲): 机器学习的可行性
提纲
机器学习的可行性 & 訓練與測試内容如:
1. 引入计算橙球概率问题
2. 通过用Hoeffding's inequality解决上面的问题,并得出PAC的概念,证明采样数据学习到的h的错误率可以和全局一致是PAC的
3. 将得到的理论应用到机器学习,证明实际机器是可以学习
4. 二元分类的 Effective Number
5. 一般备选函数的 EffectiveNumber
6. break point
=======================
Learning is Impossible机器学习的可行性
假设有如下学习问题: 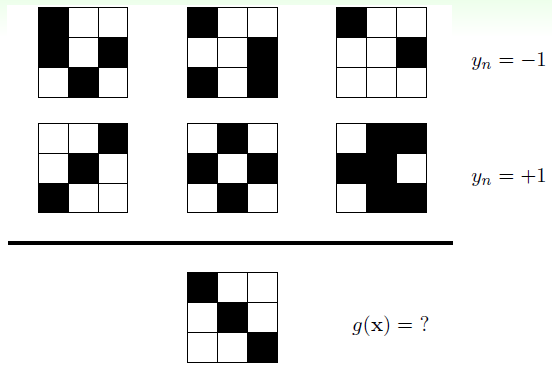
训练数据D包含了6张3*3的黑白图片,并给出了对应的输出,根据这些信息确定一个近似目标函数g,并用g计算最下方图片的输出。
甲认真看了下发现第一行三张图片左上角都是黑色色块,第二行三张图片左上角都是白色色块,最下面那张左上角是黑色,所以g(x)=-1;乙发现第一行三张图片都不是对称的,第二行三张图片总能找到一个对称轴,而最下面那张图也有一个对称轴,所以g(x)=+1。在这个例子中,你给出一个备选的g函数,总能找到另一个g'函数在D上成立,并且输出与g相反,也即,在D上正确的g,在D以外的数据上不一定正确!更苦逼的是,D以外的计算结果我们无法验证它的正确性!
再举一个相似的例子:
输入集{χ}={0,1}^3;
输出集{η}={○,x}
训练数据D ===>>

由于该问题比较简单,我们可以把所有在D上成立的备选函数 fi 枚举出来:
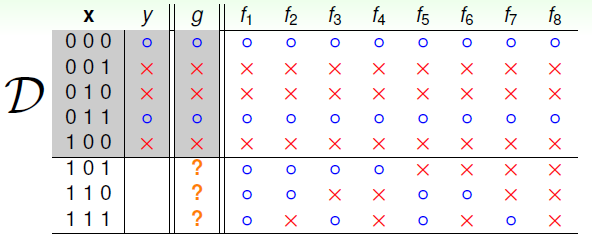
f1 ~ f8 都有可能是函数g,但是我们确定不了。在上面的两个例子中,在D的基础上都能得出不止一个备选函数 fi,并且无法确定这些备选函数的正确性。对于这样的问题,可以讲机器学习是无能为力的。
Probability to the Rescue概率方法
如果有一个装有很多(数量很大以至于无法通过数数解决)橙色球和绿色球的罐子,我们能不能推断橙色球的比例?根据上一节,用有限的数据D,去推测D超集上的目标函数f有可能会失败。这种用已知推测未知的问题在概率论中同样存在:

很明显的思路是利用统计中抽样的方法,既然我们无法穷尽数遍所有罐子中的球,不如随机取出几个球,算出其中两种颜色球的比例去近似得到我们要的答案,
在一个罐子里,放着很多小球,他们分两种颜色{橘色,绿色}。有什么办法能够推测橘色小球所占的比例?从罐中随机抓一把小球,有N个。假设:罐中橘色球的比例为μ(未知),抓出来的样本中橘色球的比例为ν(已知)。ν能代表μ吗?
根据概率论中的霍夫丁不等式(Hoeffding’s Inequality),若N足够大,ν就很可能接近μ。 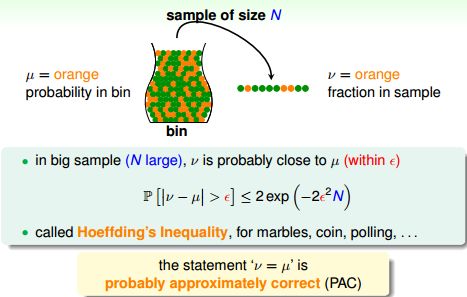
这里v 是样本概率;u 是总体概率。
Connection to Learning概率方法与学习问题的联系

映射中最关键的点是讲抽样中橙球的概率理解为样本数据集D上h(x)错误的概率,以此推算出在所有数据上h(x)错误的概率,这也是机器学习能够工作的本质,即我们为啥在采样数据上得到了一个假设,就可以推到全局呢?因为两者的错误率是PAC的,只要我们保证前者小,后者也就小了。
橘色球的比例μ --》备选函数h(x)的正确性(是否接近f(x)),h∈H
罐子中的小球 --》 输入集{χ}
作为样本的N个小球 --》 训练集D={ xi, yi } ( i=1, ... ,N) D∈{χ}
橘色小球 --》h(xi)错误,或h(xi)≠f(xi)
绿色小球 --》h(xi)正确,或h(xi)=f(xi)
这里假设小球与数据x都是独立同分布的。
显然,N足够大的时候可以用D上的 [h(x)≠f(x)] 来推测{χ}上的 [h(x)≠f(x)]。就是说,如果样本足够大,那么备选函数h在D上犯错误的比例接近其在{χ}上犯错误的比例。
设某一备选函数h在D上的犯错比例为E-in(h),在整个输入集上的犯错比例为E-out(h),则有:
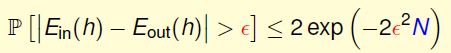
这意味着我们可以根据备选函数h在D上的表现来衡量它的正确性,并最终从备选函数集H中选出最优的那个h作为g,且g≈f

请注意,以上都是对某个特定的假设,其在全局的表现可以和其在DataSet的表现PAC,保证DataSet表现好,就能够推断其能泛化。可是我们往往有很多假设,我们实际上是从很多假设中挑一个表现最好(Ein最小)的作为最终的假设,那么这样挑的过程中,最小的Ein其泛化能力一定是最好么?肯定不是。
对于一个固定的假设h, 我们需要验证它的错误率;然后根据验证的结果选择最好的h。
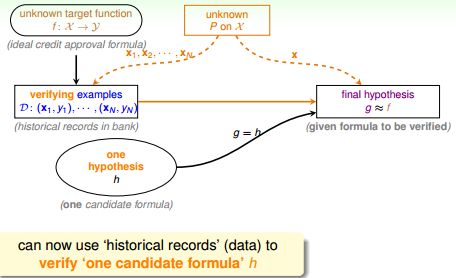
Connection to Real Learning真实的机器学习
到此为止万无一失了吗?No,因为概率论喜欢与人开玩笑。举个例子,150个人,每人抛一个硬币5次,至少有一个人5次皆为人头向上的概率为:
所以一个小概率事件如果重复多次,他发生的概率就会变得很大。
同理,如下情形是有可能的:
学习算法A在备选函数集H中(含有很多h)孜孜不倦地挑选着h,突然找到一个hi,发现它在D上没犯错误或只犯了很少错误,A高兴大喊:我找到g了,就是这个hi!但实际上这个hi在{χ}上却犯了很多错误(E-in(hi)与E-out(hi)差很远)。对于这个hi来说,D是一个坏样本(Bad Sample)。

H中可能提取若干样本Di,{ i= 1, 2,3 . . . },对于某一个h来说,其中一些样本是Bad Sample。那么对于任意样本D和给定的h,有:
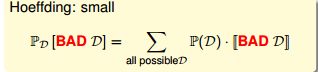
面对多个h 做选择时,容易出现问题。比如,某个不好的h 刚好最初的”准确“ 的假象。在整个备选函数集H(有M个元素)上,以下4个命题等价:
- ---》D是H的Bad Sample
- ---》D是某些h的Bad Sample
- ---》学习算法A不能在H中做自由筛选
- ---》存在某些h使得E-in(h)与E-out(h)差很远
随着h 的增加,出现这种假象的概率会增加。发生这种现象的原因是训练数据质量太差。
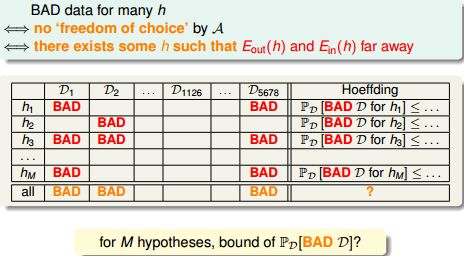
所以,D-1126这样的训练数据集是比较优质的。对于某个假设h, 当训练数据对于h 是BAD sample 时, 就可能出现问题。因此,我们希望对于我们面对的假设空间,训练数据对于其中的任何假设h 都不是BAD sample。给定任意D,它是某些H的Bad Sample的概率为:
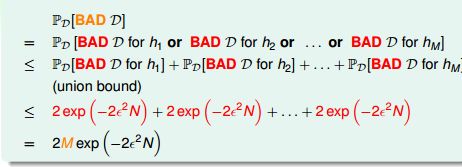
所以,当假设空间有限时(大小为M)时, 当N 足够大,发生BAD sample 的概率非常小。此时学习是有效的。当假设空间无穷大时,例如感知机空间. 即H中备选函数的数量M越少,样本数据量N越大,则样本成为坏样本的概率越小。在一个可接受的概率水平上,学习算法A只需要挑选那个表现最好的h作为g就行了。
以上推论成立的必要条件是M有限,当M→∞时怎么办? 接下来我们讨论。