Apache Flink fault tolerance源码剖析(四)
上篇文章我们探讨了Zookeeper在Flink的fault tolerance中发挥的作用(存储/恢复已完成的检查点以及检查点编号生成器)。
这篇文章会谈论一种特殊的检查点,Flink将之命名为——Savepoint(保存点)。
因为保存点只不过是一种特殊的检查点,所以在Flink中并没有太多代码实现。但作为一个特性,值得花费一个篇幅来介绍。
检查点VS保存点
使用数据流API编写的程序可以从保存点来恢复执行。保存点允许你在更新程序的同时还能保证Flink集群不丢失任何状态。
保存点是人工触发的检查点,它会对应用程序做快照并将快照存入持久化存储(state backend)。保存点依赖于常规的检查点机制,在程序执行期间,Flink会周期性得在工作节点上执行快照并产生检查点。恢复机制仅仅需要最新的已完成的检查点,一旦有新的检查点完成,老的检查点就可以被安全地丢弃。
保存点跟那些周期性的检查点是相似的。不同点有两个:
- 它们是由用户触发的
- 当有新的已完成的检查点产生的时候,不会自动失效
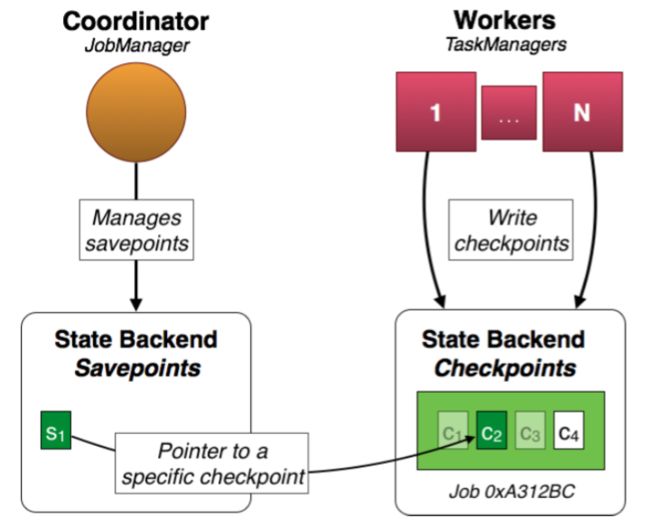
上图是两者区别的一个图示。在上面的例子中,job 0xA312Bc产生了检查点c1,c2,c3和c4。周期性的检查点c1和c2已经被丢弃了,c4是最新的检查点。而c2有些特别,它的状态关联着保存点s1,它已被用户触发了并且不会自动过期(图中可见c1和c3在新的检查点产生之后,已经自动过期了)。
需要注意的是,s1仅仅是一个指向检查点c2的指针。这意味着,真实的状态不会被拷贝给保存点,但是关联的检查点的状态会得到保存。
保存点的触发机制
上面我们说保存点跟检查点其中一个显著的区别是保存点是用户自行触发的。那么用户是通过什么手段触发的?答案是Flink提供的命令行客户端。
Flink有个独立的client模块flink-clients。触发代码所在的类位于该模块下的CliFrontend:
org.apache.flink.client.CliFrontend
代码位于方法triggerSavepoint中:
ActorGateway jobManager = getJobManagerGateway(options);
logAndSysout("Triggering savepoint for job " + jobId + ".");
Future<Object> response = jobManager.ask(new TriggerSavepoint(jobId),new FiniteDuration(1, TimeUnit.HOURS));基于Akka的actor的消息驱动机制,client会向jobManager发送一个TriggerSavepoint消息。来驱动jobManager响应触发保存点请求。
Flink定义了一系列跟client交互的消息:
org.apache.flink.runtime.messages.JobManagerMessages
/** * Triggers a savepoint for the specified job. * * This is not a subtype of [[AbstractCheckpointMessage]], because it is a * control-flow message, which is *not* part of the checkpointing mechanism * of triggering and acknowledging checkpoints. * * @param jobId The JobID of the job to trigger the savepoint for. */
case class TriggerSavepoint(jobId: JobID) extends RequiresLeaderSessionID
/** * Response after a successful savepoint trigger containing the savepoint path. * * @param jobId The job ID for which the savepoint was triggered. * @param savepointPath The path of the savepoint. */
case class TriggerSavepointSuccess(jobId: JobID, savepointPath: String)
/** * Response after a failed savepoint trigger containing the failure cause. * * @param jobId The job ID for which the savepoint was triggered. * @param cause The cause of the failure. */
case class TriggerSavepointFailure(jobId: JobID, cause: Throwable)
/** * Disposes a savepoint. * * @param savepointPath The path of the savepoint to dispose. */
case class DisposeSavepoint(savepointPath: String) extends RequiresLeaderSessionID
/** Response after a successful savepoint dispose. */
case object DisposeSavepointSuccess
/** * Response after a failed savepoint dispose containing the failure cause. * * @param cause The cause of the failure. */
case class DisposeSavepointFailure(cause: Throwable)那么JobManager是如何响应TriggerSavepoint消息的呢?
future {
try {
// Do this async, because checkpoint coordinator operations can
// contain blocking calls to the state backend or ZooKeeper.
val savepointFuture = savepointCoordinator.triggerSavepoint(
System.currentTimeMillis())
savepointFuture.onComplete {
// Success, respond with the savepoint path
case scala.util.Success(savepointPath) =>
senderRef ! TriggerSavepointSuccess(jobId, savepointPath)
// Failure, respond with the cause
case scala.util.Failure(t) =>
senderRef ! TriggerSavepointFailure(
jobId,
new Exception("Failed to complete savepoint", t))
}(context.dispatcher)
} catch {
case e: Exception =>
senderRef ! TriggerSavepointFailure(jobId, new Exception(
"Failed to trigger savepoint", e))
}
}(context.dispatcher)从代码中可见,它调用了SavepointCoordinator#triggerSavepoint方法来完成触发保存点的逻辑,并返回一个Future对象,然后为其注册了一个callback。在触发的检查点转变为已完成的检查点之后,该callback将会被触发调用,如果成功将给client回复TriggerSavepointSuccess消息。
具体的触发保存点的逻辑是在类SavepointCoordinator中实现的。我们在分析检查点触发机制时,谈论了CheckpointCoordinator。SavepointCoordinator是CheckpointCoordinator的子类。
在SavepointCoordinator的triggerSavepoint中,其具体的触发逻辑又间接调用了父类CheckpointCoordinator的实例方法triggerCheckpoint:
try {
// All good. The future will be completed as soon as the
// triggered checkpoint is done.
success = triggerCheckpoint(timestamp, checkpointId);
}
finally {
if (!success) {
savepointPromises.remove(checkpointId);
promise.failure(new Exception("Failed to trigger savepoint"));
}
}这里需要注意的是,CheckpointCoordinator的triggerCheckpoint产生的只是PendingCheckpoint,即并未完成的检查点。这时,保存点并未建立跟当前检查点的关系(因为PendingCheckpoint并不一定会成功地转化成CompletedCheckpoint,这个时候建立对应关系没有意义),直到该检查点变成已完成的检查点。
在一个检查点变成已完成的检查点CompletedCheckpoint后会触发一个回调onFullyAcknowledgedCheckpoint,此时才是保存点跟该检查点建立关系的时机:
protected void onFullyAcknowledgedCheckpoint(CompletedCheckpoint checkpoint) {
// Sanity check
Promise<String> promise = checkNotNull(savepointPromises
.remove(checkpoint.getCheckpointID()));
// Sanity check
if (promise.isCompleted()) {
throw new IllegalStateException("Savepoint promise completed");
}
try {
// Save the checkpoint
String savepointPath = savepointStore.putState(checkpoint);
promise.success(savepointPath);
}
catch (Exception e) {
LOG.warn("Failed to store savepoint.", e);
promise.failure(e);
}
}也正是在调用了
promise.success(savepointPath);之后,JobManager才会真正回复client消息(即触发savepointFuture.onComplete回调)。
与此同时,从上面的代码段中我们也看到了保存点跟检查点是如何建立关系的。它就是savepointStore,也就是之前提到的指针。savepointStore类型是StateStore,这是我们下面要分析的内容——保存点状态的存取。
保存点状态
在Flink中提供了一个接口:StateStore来支持保存点状态的存取。它对外提供了存取保存点状态的方法:
- putState
- getState
- disposeState
不管,最终的存储介质是什么,他们都是基于逻辑路径(logic path)的存取方式。
目前该接口有三个实现:
- FileSystemStateStore:基于文件系统的状态存储
- HeapStateStore:基于Java堆内存的状态存储
- SavepointStore:对保存点的状态存取,是装饰器模式的实现并且将泛型类型具体化为
CompletedCheckpoint。
这三个接口中前两个接口真正是基于不同存储介质的状态保存机制的实现。并且它们在Flink中也分别对应了两种存储机制:FileSystemStateStore对应filesystem;HeapStateStore对应jobmanager。
JobManager
这是保存点机制的默认实现。保存点被存储在job manager的堆内存中。它们在job manager关闭后会丢失。这种模式只在同一集群运行中你关闭以及恢复程序时才有用。不推荐在生产环境中使用这种模式。并且这种模式,保存点也不是job manager高可用保证的一部分。
配置如下:
savepoints.state.backend: jobmanagerFile system
保存点存储在文件系统基于配置的文件夹中。它们对集群的每个节点的实例都可见,并且允许你的程序在不同的集群之间进行迁移。
配置:
savepoints.state.backend: filesystem
savepoints.state.backend.fs.dir: hdfs:///flink/savepoints需要注意的是,一个保存点是一个指向已完成的检查点的指针。那意味着保存点的状态不仅仅指保存点文件本身所存储的内容,而且需要包含检查点数据(可能被存储在另一个文件集合中)。因此,如果你使用filesystem作为保存点的持久化方式而使用jobmanager作为检查点的持久化方式,那么这种情况下Flink将无法实现fault tolerance,因为在job manager重启之后检查点的数据将无法被访问。所以最好保证两个机制的一致性。
Flink通过SavepointStoreFactory#createFromConfig结合配置文件来创建具体的StateStore的实现。
小结
本篇我们主要围绕了Flink的保存点进行展开,分析了保存点跟检查点的联系与区别,结合代码分析了保存点的触发机制以及保存点状态的存储。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
