商业智能领域需要了解的数据库优化理论
由于数据仓库系统存储大量的历史数据和当前数据,并且数据量在不断增加,为了提高数据存储、检索的运行效率,建立一个优良的数据仓库系统,数据仓库设计人员和开发人员需要掌握Oracle优化理论方面的知识,这有助于设计、开发出高性能的数据仓库系统。
1 外部优化原则
CPU是直接影响数据库性能的外部因素,同时Oracle的内存大小也会影响SQL查询的
效率,大量的Net8通信同样会使SQL的性能变差。
下面介绍外部优化原则的具体调整方法。
1) 适当增加服务器CPU的数量,服务器的性能会受CPU的限制,最好的方法就是为服务器增加额外的CPU,或者关闭很多等待处理资源的各种组件,以减少CPU资源的浪费。
2) 当内存分页时,如果内存容量不足,最好的方法就是增加更多的内存,减小SGA的大小,或者关闭Oracle多线程服务器,以提高数据库系统的运行效率。
2 SQL优化基本规则
1) 在对大表进行全表搜索时,为了避免不必要的全表搜素而导致的大量I/O操作,最常见的调优方法是适量增加索引,加快查询的速度,以提高数据库运行的效率。
2) 保证最优的索引使用,对于改善查询的速度和提高数据库的性能是至关重要的。在某些情况下也可以选择多个索引进行查询,还包括位图索引和基于函数索引的使用。
3 SQL使用规范
1) 尽量避免使用游标。因为游标的效率较差,如果游标操作的数据超过1W行,那么就应该采用其他的方法:如果使用了游标,还要尽量避免在游标循环中再进行表连接的操作。
2) 不要在where子句中的”=”左边进行函数、算术运算或其他表达式运算,否则数据库系统可能无法正常使用索引。
3) 尽量使用exists代替select count(*)语句来判断表中是否存在满足条件的记录。Count函数只有统计表中所有行数时才使用,而且count(1)或count(‘X’)比count(*)更有效率。
4) 注意表之间关联字段的数据类型,避免使用不同类型的字段作为关联条件进行多表连接。
4 索引使用规范
1) 索引的创建要与实际应用情况结合考虑,建议大的联机事务处理系统(OLTP)表最好不要超过6个索引,以免系统增加不必要的负担。
2) 尽可能使用索引字段作为查询条件,以提高查询效率。
3) 尽量避免在大表查询时使用全表扫描的方式,必要时可以考虑重建索引。
4) 注意索引的定期维护,可以周期性地重建索引和重新编译存储过程。
例如使用:
SELECT ‘ALTER INDEX’||index_name||’REBUILD;’
FROM user_indexes
语句查询出当前用户下所有的索引重建语句,然后在SQL窗口下一条执行该重建索引语句。
5 临时表使用规范
1) 尽量避免在临时表中使用distinct、order by、group by、having、join,因为这些语句会加重临时表的负担。同时也尽量避免临时表的频繁创建和删除,以减少系统表资源的消耗。
2) 在新建临时表时,如果一次性插入数据量非常大,那么可以使用select into语句替代create table语句,避免对日志的大量操作,可以缩短运行的时间;如果数据量并不大,为了缓和系统表的资源消耗,建议先创建临时表,然后再进行插入操作。
3) 如果临时表的数据量较大,则需要为临时表建立相应的索引,同时保证数据库系统对该临时表索引的使用。
4) 如果存储过程中使用了临时表,在代码的结尾处,一定要将所有的临时表都删除,通常的做法是先执行truncate table语句,然后再执行drop table语句,这样就可以避免数据库系统较长时间锁定临时表与其他表的连接查询和关联,从而减轻数据库系统的负担。
6 索引创建原则
索引创建原则如图:
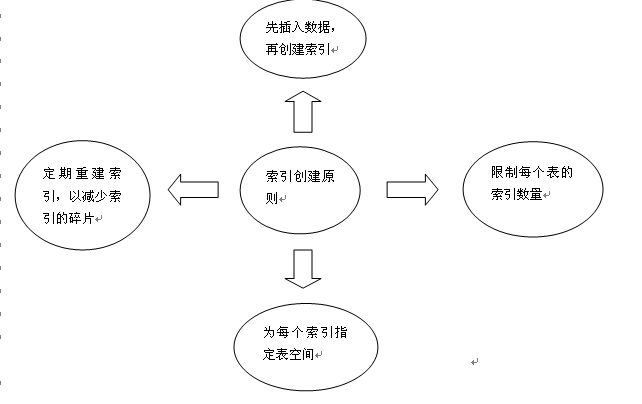
1) 先插入数据,再进行索引的创建工作。
2) 限制每个表的索引数量,避免大量的索引导致数据库系统的性能降低。
3) 为每个索引指定表空间,这样有利于避免发生I/0冲突。
4) 定期重建索引,以减少索引的碎片,提高数据库系统的性能,一般来说,枚举类型的字段可以考虑使用位图索引,而非二叉树类索引。
7 大数据量表的维护原则
1) 如果是超大数据量的表,并且经常进行增加、删除、修改、查询等操作,最好的办法就是定期收集统计信息传递给Oracle优化器,以提高数据库系统的性能。
2) 如果是大数据量的表,可以考虑使用按照时间或者哈希的分区技术,并且将不同的分区放入到规定的表空间中,以提高数据库查询的效率。
8 视图创建原则
1) 绝对禁止在视图的基础上再创建视图,这样会严重影响数据库的性能。
2) 推荐使用物化视图技术,以提高数据库表查询的效率,但是物化视图刷新的频率不能过高,因为这样也会影响整个数据库系统的性能。
3) 为保证数据的一致性和安全性,推荐将普通视图设置成只读类型,不能做任何删除操作。
9 代码程序中使用索引的原则
1) 尽量少用in操作符。使用exists替代in操作符,使查询的子表能够使用索引,提高数据库表查询的效率。
2) 在where条件的后面尽量不用<>或!=。例如,条件count<0可以修改成count>0 or count<0,这样可以发挥索引的作用,提高数据库表查询的效率。
3) Like语句尽量不要使用通配符“%”或者“_”作为查询条件的第一个字符。例如,count like ‘%100%’,这个条件会对数据库表进行全表扫描,严重影响了数据库表查询的性能,可以修改成count like ‘2100%’ or count like ‘3100%’,这样count字段会利用该字段上的索引进行不同范围的查询,大大提高了数据库表的查询效率。
4) 因为运算的字段不能进行任何索引,所以where子句应该尽量避免在索引字段上做任何计算。例如,substr(count,1,3)=’100’可以修改成count like ‘100%’。
5) 在where条件的后面,一般将表连接语句写在最前面,将可以滤掉大量记录的条件写在最后。因为Oracle进行多表查询时,是从后往前执行SQ代码的。
10 代码程序中的一些建议
1) 尽量不使用select *语句,最好的办法是将要查询的字段全部列出,以提高SQL运行的效率。因为Oracle在解析的过程中,会将“*”依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间和数据库资源。
2) 尽量多使用execute immediate语句,可以提高SQL执行的效率。
3) 在使用游标时,如果将大量的数据集合赋给游标,运行时一般会出现内存溢出的报错信息。这时需要调整缓冲区的大小,所以使用游标时要注意内存大小的问题。
4) 对于超大数据量的表应该每隔一段时间执行一次收集统计信息的操作。例如,执行dbms_stats.gather_table_stats命令,将统计信息传递给Oracle优化器,以提高数据库系统的性能。
5) 面向对象的最佳实践方法是为每个属性都定义一个get方法,但是不能把面向对象的实现方法应用于关系型数据库中。关系型数据库中的表不能等同于面向对象中的类,表中的字段同样不能等同于类的属性,因此查询数据表中的字段时,应该一次性全部取出。
6) 谨慎使用自定义的函数。自定义函数通常会影响优化器对查询的优化作用。
7) 检查满足某个条件的记录是否存在,绝对不要使用select count(*)语句去判断,可以考虑使用merge语句判断该记录是否存在。
总之,编写SQL代码程序的基本原则是尽可能减少数据库的连接,尽量减少表之间的关联(在表的设计过程中可以将第三范式的表转化成第二范式),少用临时表,避免将大批量的数据分割成小块的数据去处理。
此外,建议在表设计过程中尽量避免使用BLOB、CLOB等大字段,因为这样做可能会对数据库的迁移备份等造成不必要的麻烦。
elvis
2012.12.23
知识共享~共同进步
转载请注明:
http://blog.csdn.net/elvis_dataguru/article/details/8393933