从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
一.引入
推荐系统(主要是CF)是我在参加百度的电影推荐算法比赛的时候才临时学的,虽然没拿什么奖,但是知识却是到手了,一直想写一篇关于推荐系统的文章总结下,这次借着完善DML写一下,权当是总结了。不过真正的推荐系统当然不会这么简单,往往是很多算法交错在一起,本文只是入门水平的总结罢了。 (本文所用测试数据是movielens100k)
本文采用的评测标准是RMSE,数值越小算法越好,在movielens100k 的 u1数据上对每个要求预测的评分输出训练集总的平均分,其RMSE是:

二.Item Based and User Based
1.原理
Item-based和User-Based是CF算法中最基础的两个了,其算法思想很intuitive:
User-based就是把与你有相同爱好的用户所喜欢的物品(并且你还没有评过分)推荐给你
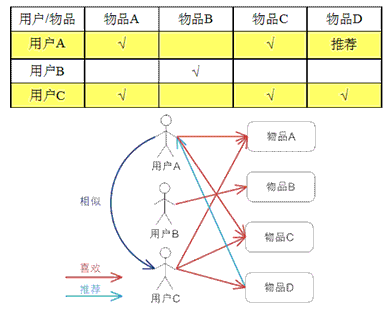 (图自【1】)
(图自【1】)
Item-based则与之相反,把和你之前喜欢的物品近似的物品推荐给你:
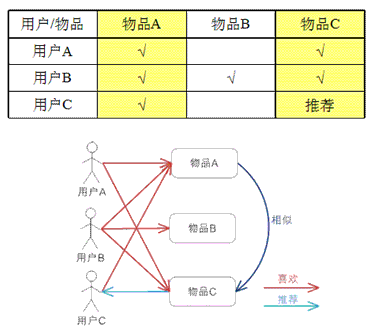 (图自【1】)
(图自【1】)
更一般的,我们此次使用的数据集是要求你预测某个用户对某个item的评分,以Item-based为例,使用上面提到的算法思想就是检测该用户评过的所有物品和待预测物品的相似度,而两个物品的相似度我们可以找出所有同时对两个物品进行评价的评分,然后计算其皮尔逊相似度,按照相似度计算加权平均值即可,具体过程可以看下面的实现(和《集体智慧编程》中的类似)
2.实现
- from __future__ import division
- import numpy as np
- import scipy as sp
- class Item_based_C:
- def __init__(self,X):
- self.X=np.array(X)
- print "the input data size is ",self.X.shape
- self.movie_user={}
- self.user_movie={}
- self.ave=np.mean(self.X[:,2])
- for i in range(self.X.shape[0]):
- uid=self.X[i][0]
- mid=self.X[i][1]
- rat=self.X[i][2]
- self.movie_user.setdefault(mid,{})
- self.user_movie.setdefault(uid,{})
- self.movie_user[mid][uid]=rat
- self.user_movie[uid][mid]=rat
- self.similarity={}
- pass
- def sim_cal(self,m1,m2):
- self.similarity.setdefault(m1,{})
- self.similarity.setdefault(m2,{})
- self.movie_user.setdefault(m1,{})
- self.movie_user.setdefault(m2,{})
- self.similarity[m1].setdefault(m2,-1)
- self.similarity[m2].setdefault(m1,-1)
- if self.similarity[m1][m2]!=-1:
- return self.similarity[m1][m2]
- si={}
- for user in self.movie_user[m1]:
- if user in self.movie_user[m2]:
- si[user]=1
- n=len(si)
- if (n==0):
- self.similarity[m1][m2]=1
- self.similarity[m2][m1]=1
- return 1
- s1=np.array([self.movie_user[m1][u] for u in si])
- s2=np.array([self.movie_user[m2][u] for u in si])
- sum1=np.sum(s1)
- sum2=np.sum(s2)
- sum1Sq=np.sum(s1**2)
- sum2Sq=np.sum(s2**2)
- pSum=np.sum(s1*s2)
- num=pSum-(sum1*sum2/n)
- den=np.sqrt((sum1Sq-sum1**2/n)*(sum2Sq-sum2**2/n))
- if den==0:
- self.similarity[m1][m2]=0
- self.similarity[m2][m1]=0
- return 0
- self.similarity[m1][m2]=num/den
- self.similarity[m2][m1]=num/den
- return num/den
- def pred(self,uid,mid):
- sim_accumulate=0.0
- rat_acc=0.0
- for item in self.user_movie[uid]:
- sim=self.sim_cal(item,mid)
- if sim<0:continue
- #print sim,self.user_movie[uid][item],sim*self.user_movie[uid][item]
- rat_acc+=sim*self.user_movie[uid][item]
- sim_accumulate+=sim
- #print rat_acc,sim_accumulate
- if sim_accumulate==0: #no same user rated,return average rates of the data
- return self.ave
- return rat_acc/sim_accumulate
- def test(self,test_X):
- test_X=np.array(test_X)
- output=[]
- sums=0
- print "the test data size is ",test_X.shape
- for i in range(test_X.shape[0]):
- pre=self.pred(test_X[i][0],test_X[i][1])
- output.append(pre)
- #print pre,test_X[i][2]
- sums+=(pre-test_X[i][2])**2
- rmse=np.sqrt(sums/test_X.shape[0])
- print "the rmse on test data is ",rmse
- return output

可以看到与全部输出平均值比较有一定的提升,但是效果似乎并不好,因为这个算法确实有些简单,但是这个算法的思想对CF算法都很有指导意义
三.matrix factorization model 和 Baseline Predictors
1.matrix factorization model
把我们的用户评分想象成一个表:
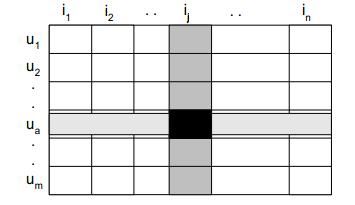 (图忘了是哪的了....)
(图忘了是哪的了....)
每一行代表一个用户,每一列代表一个物品,这其实就是一个矩形,只是我们拥有的这个矩形可能是非常稀疏的,也就是我们知道的评分占总量很少,,但现在我们知道它是一个矩形,一个矩形自然可以表示为另两个矩形的乘积:
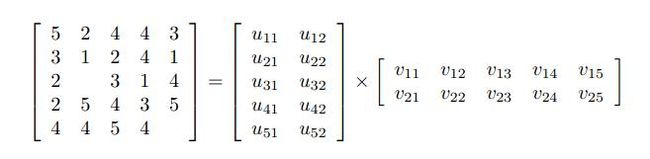
这也就是matrix factorization model的原理了,我们需要做的就是通过已有数据来学习右边的两个矩形,更intuitive的你可以把总的矩形里的每个评分看成是该用户的特征向量与物品特征向量的内积:(这里符号变得有些多,你理解了意思就成)
![]()
2.Baseline Predictors

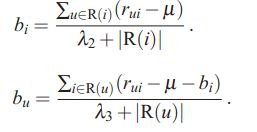
四.SVD and ++ and so on
(图来自【2】)
1.SVD及其衍生算法的原理
SVD算法其实就是上面介绍的matrix factorization的一种,加上baseline predictor算是一种优化而已,最简单的SVD是优化下面的Loss function:

采用随机梯度下降进行优化:
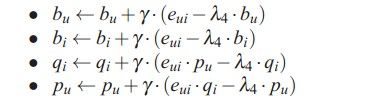
虽然看起来比较简单,但实际上对预测的效果已经超出Item-based很多了,而从SVD衍生出很多其它的算法,利用了更多的信息,我们在这里只予以介绍而不加实践。
SVD++
可以看到,SVD中并没有利用好一个用户评价了哪些电影这种信息,这代表无论评分高低,在看电影之前这些电影对他来说是有吸引力的,更一般的,如果你有用户查看过电影介绍的数据,同样也可以加以利用,SVD++就是加入了这些信息:
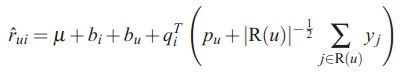
R(u)表示用户rate过的电影,这样加入参数后使模型更加复杂了,但其效果也就更好了,具体的优化过程就不贴了,反正还是那样,对Loss function求导而已。
timeSVD++
无论是netflix还是movielens的数据,它的最后一列是用户作出该评价的时间,timeSVD++就是将时间这个信息加以了利用,比较直观的理解就是影片的受欢迎程度可能是随着时间的变化而变化的,某些电影可能还具有周期性,如何加入这个信息呢?:
是pu成为一个随着时间变化而变化的参数:
![]()
![]()

2.SVD的实现
说了那么多高大上的衍生算法,我们还是来实现一下最基础的SVD吧:
- from __future__ import division
- import numpy as np
- import scipy as sp
- from numpy.random import random
- class SVD_C:
- def __init__(self,X,k=20):
- '''''
- k is the length of vector
- '''
- self.X=np.array(X)
- self.k=k
- self.ave=np.mean(self.X[:,2])
- print "the input data size is ",self.X.shape
- self.bi={}
- self.bu={}
- self.qi={}
- self.pu={}
- self.movie_user={}
- self.user_movie={}
- for i in range(self.X.shape[0]):
- uid=self.X[i][0]
- mid=self.X[i][1]
- rat=self.X[i][2]
- self.movie_user.setdefault(mid,{})
- self.user_movie.setdefault(uid,{})
- self.movie_user[mid][uid]=rat
- self.user_movie[uid][mid]=rat
- self.bi.setdefault(mid,0)
- self.bu.setdefault(uid,0)
- self.qi.setdefault(mid,random((self.k,1))/10*(np.sqrt(self.k)))
- self.pu.setdefault(uid,random((self.k,1))/10*(np.sqrt(self.k)))
- def pred(self,uid,mid):
- self.bi.setdefault(mid,0)
- self.bu.setdefault(uid,0)
- self.qi.setdefault(mid,np.zeros((self.k,1)))
- self.pu.setdefault(uid,np.zeros((self.k,1)))
- if (self.qi[mid]==None):
- self.qi[mid]=np.zeros((self.k,1))
- if (self.pu[uid]==None):
- self.pu[uid]=np.zeros((self.k,1))
- ans=self.ave+self.bi[mid]+self.bu[uid]+np.sum(self.qi[mid]*self.pu[uid])
- if ans>5:
- return 5
- elif ans<1:
- return 1
- return ans
- def train(self,steps=20,gamma=0.04,Lambda=0.15):
- for step in range(steps):
- print 'the ',step,'-th step is running'
- rmse_sum=0.0
- kk=np.random.permutation(self.X.shape[0])
- for j in range(self.X.shape[0]):
- i=kk[j]
- uid=self.X[i][0]
- mid=self.X[i][1]
- rat=self.X[i][2]
- eui=rat-self.pred(uid,mid)
- rmse_sum+=eui**2
- self.bu[uid]+=gamma*(eui-Lambda*self.bu[uid])
- self.bi[mid]+=gamma*(eui-Lambda*self.bi[mid])
- temp=self.qi[mid]
- self.qi[mid]+=gamma*(eui*self.pu[uid]-Lambda*self.qi[mid])
- self.pu[uid]+=gamma*(eui*temp-Lambda*self.pu[uid])
- gamma=gamma*0.93
- print "the rmse of this step on train data is ",np.sqrt(rmse_sum/self.X.shape[0])
- #self.test(test_data)
- def test(self,test_X):
- output=[]
- sums=0
- test_X=np.array(test_X)
- #print "the test data size is ",test_X.shape
- for i in range(test_X.shape[0]):
- pre=self.pred(test_X[i][0],test_X[i][1])
- output.append(pre)
- #print pre,test_X[i][2]
- sums+=(pre-test_X[i][2])**2
- rmse=np.sqrt(sums/test_X.shape[0])
- print "the rmse on test data is ",rmse
- return output
行数各种少有木有,我们测试一下:在向量长度k=30,执行轮数steps=25,参数gamma=0.04,Lambda=0.15
- a=SVD_C(train_X,30)
- a.train()
- a.test(test_X)

可以达到0.927左右,比之前的提高已经很多了,事实上如果你对参数进一步优化,并且增加向量大小和迭代步数,在movielens1M的数据上可以到到0.87左右的rmse,这就是最烦人的调参了,我就不在这里详述这种痛苦的经历了.......
五.CF with RBM
又到了相当的蛋疼RBM了,RBM的CF,单模型效果和SVD相似,只是error在不同的地方,所以结合起来可以提升效果,总觉得RBM不够intuitive,这次实现也遇到很多困难,所以这一节的质量不高,见谅
1.原理
首先……你得了解一下RBM……一个能量模型,Hinton的招牌作品,DeepLearning就是由这个火起来的(DBN)
这里我就不细讲RBM了,有兴趣大家找下面的ref看,直接看看CF FOR RBM这个模型吧:

严格来说这是condional RBM,基本思路是把V用softmax的形式表示成一个向量,然后去掉改用户没有评价的部分,作为RBM的V层,共用一个Hidden层,主要参数有:Vik,Wikj,Dij,vb(bias of visual layer), hb(bias of hidden)。
这是主要的学习过程,其中的公式参见【3】:

看着是有点烦,但如果你看懂了这个结构,还是很简单明了的,与普通的RBM比较,只是在visible层的sample和update有一定的变化,主要体现在:a)sample一个v[item]的时候按随机值向上累计v[item][1...5],超过随机值的那个值设置为1,其它为0;b)update的时候按照softmax的格式来处理每一组v[item]。
2.实现
- from __future__ import division
- import numpy as np
- import scipy as sp
- from numpy.random import normal,random,uniform
- '''''
- this code still have some problem,I can only get 0.98 rmse on movielens data
- If you can figure it out,PLEASE!!! tell me .
- '''
- class TEMP:
- def __init__(self):
- self.AccVH=None
- self.CountVH=None
- self.AccV=None
- self.temp.CountV=None
- self.temp.AccH=None
- class CF_RMB_C:
- def __init__(self,X,UserNum=943,HiddenNum=30,ItemNum=1682,Rate=5):
- self.X=np.array(X)
- self.HiddenNum=HiddenNum
- self.ItemNum=ItemNum
- self.UserNum=UserNum
- self.Rate=Rate
- self.movie_user={}
- self.user_movie={}
- self.bik=np.zeros((self.ItemNum,self.Rate))
- self.Momentum={}
- self.Momentum['bik']=np.zeros((self.ItemNum,self.Rate))
- self.UMatrix=np.zeros((self.UserNum,self.ItemNum))
- self.V=np.zeros((self.ItemNum,self.Rate))
- for i in range(self.X.shape[0]):
- uid=self.X[i][0]-1
- mid=self.X[i][1]-1
- rat=self.X[i][2]-1
- self.UMatrix[uid][mid]=1
- self.bik[mid][rat]+=1
- self.movie_user.setdefault(mid,{})
- self.user_movie.setdefault(uid,{})
- self.movie_user[mid][uid]=rat
- self.user_movie[uid][mid]=rat
- pass
- self.W=normal(0,0.01,(self.ItemNum,self.Rate,HiddenNum))
- self.Momentum['W']=np.zeros(self.W.shape)
- self.initialize_bik()
- self.bj=np.zeros((HiddenNum,1)).flatten(1)
- self.Momentum['bj']=np.zeros(self.bj.shape)
- self.Dij=np.zeros((self.ItemNum,self.HiddenNum))
- self.Momentum['Dij']=np.zeros((self.ItemNum,self.HiddenNum))
- def initialize_bik(self):
- for i in range(self.ItemNum):
- total=np.sum(self.bik[i])
- if total>0:
- for k in range(self.Rate):
- if self.bik[i][k]==0:
- self.bik[i][k]=-10
- else:
- self.bik[i][k]=np.log(self.bik[i][k]/total)
- def test(self,test_X):
- output=[]
- sums=0
- test_X=np.array(test_X)
- #print "the test data size is ",test_X.shape
- for i in range(test_X.shape[0]):
- pre=self.pred(test_X[i][0]-1,test_X[i][1]-1)
- #print test_X[i][2],pre
- output.append(pre)
- #print pre,test_X[i][2]
- sums+=(pre-test_X[i][2])**2
- rmse=np.sqrt(sums/test_X.shape[0])
- print "the rmse on test data is ",rmse
- return output
- def pred(self,uid,mid):
- V=self.clamp_user(uid)
- pj=self.update_hidden(V,uid)
- vp=self.update_visible(pj,uid,mid)
- ans=0
- for i in range(self.Rate):
- ans+=vp[i]*(i+1)
- return ans
- def clamp_user(self,uid):
- V=np.zeros(self.V.shape)
- for i in self.user_movie[uid]:
- V[i][self.user_movie[uid][i]]=1
- return V
- def train(self,para,test_X,cd_steps=3,batch_size=30,numEpoch=100,Err=0.00001):
- for epo in range(numEpoch):
- print 'the ',epo,'-th epoch is running'
- kk=np.random.permutation(range(self.UserNum))
- bt_count=0
- while bt_count<=self.UserNum:
- btend=min(self.UserNum,bt_count+batch_size)
- users=kk[bt_count:btend]
- temp=TEMP
- temp.AccVH=np.zeros(self.W.shape)
- temp.CountVH=np.zeros(self.W.shape)
- temp.AccV=np.zeros(self.V.shape)
- temp.CountV=np.zeros(self.V.shape)
- temp.AccH=np.zeros(self.bj.shape)
- watched=np.zeros(self.UMatrix[0].shape)
- for user in users:
- watched[self.UMatrix[user]==1]=1
- sv=self.clamp_user(user)
- pj=self.update_hidden(sv,user)
- temp=self.accum_temp(sv,pj,temp,user)
- #AccVH+=pj*
- for step in range(cd_steps):
- sh=self.sample_hidden(pj)
- vp=self.update_visible(sh,user)
- sv=self.sample_visible(vp,user)
- pj=self.update_hidden(sv,user)
- deaccum_temp=self.deaccum_temp(sv,pj,temp,user)
- self.updateall(temp,batch_size,para,watched)
- #updateall============================================
- bt_count+=batch_size
- self.test(test_X)
- def accum_temp(self,V,pj,temp,uid):
- for i in self.user_movie[uid]:
- temp.AccVH[i]+=np.dot(V[i].reshape(-1,1),pj.reshape(1,-1))
- temp.CountVH[i]+=1
- temp.AccV[i]+=V[i]
- temp.CountV[i]+=1
- temp.AccH+=pj
- return temp
- def deaccum_temp(self,V,pj,temp,uid):
- for i in self.user_movie[uid]:
- temp.AccVH[i]-=np.dot(V[i].reshape(-1,1),pj.reshape(1,-1))
- temp.AccV[i]-=V[i]
- temp.AccH-=pj
- return temp
- def updateall(self,temp,batch_size,para,watched):
- delatW=np.zeros(temp.CountVH.shape)
- delatBik=np.zeros(temp.CountV.shape)
- delatW[temp.CountVH!=0]=temp.AccVH[temp.CountVH!=0]/temp.CountVH[temp.CountVH!=0]
- delatBik[temp.CountV!=0]=temp.AccV[temp.CountV!=0]/temp.CountV[temp.CountV!=0]
- delataBj=temp.AccH/batch_size
- self.Momentum['W'][temp.CountVH!=0]=self.Momentum['W'][temp.CountVH!=0]*para['Momentum']
- self.Momentum['W'][temp.CountVH!=0]+=para['W']*(delatW[temp.CountVH!=0]-para['weight_cost']*self.W[temp.CountVH!=0])
- self.W[temp.CountVH!=0]+=self.Momentum['W'][temp.CountVH!=0]
- self.Momentum['bik'][temp.CountV!=0]=self.Momentum['bik'][temp.CountV!=0]*para['Momentum']
- self.Momentum['bik'][temp.CountV!=0]+=para['bik']*delatBik[temp.CountV!=0]
- self.bik[temp.CountV!=0]+=self.Momentum['bik'][temp.CountV!=0]
- self.Momentum['bj']=self.Momentum['bj']*para['Momentum']
- self.Momentum['bj']+=para['bj']*delataBj
- self.bj+=self.Momentum['bj']
- for i in range(self.ItemNum):
- if watched[i]==1:
- self.Momentum['Dij'][i]=self.Momentum['Dij'][i]*para['Momentum']
- self.Momentum['Dij'][i]+=para['D']*temp.AccH/batch_size
- self.Dij[i]+=self.Momentum['Dij'][i]
- np.seterr(all='raise')
- def update_hidden(self,V,uid):
- r=self.UMatrix[uid]
- hp=None
- for i in self.user_movie[uid]:
- if hp==None:
- hp=np.dot(V[i],self.W[i]).flatten(1)
- else:
- hp+=np.dot(V[i],self.W[i]).flatten(1)
- pj=1/(1+np.exp(-self.bj-hp+np.dot(r,self.Dij).flatten(1)))
- #pj=1/(1+np.exp(-self.bj-hp))
- return pj
- def sample_hidden(self,pj):
- sh=uniform(size=pj.shape)
- for i in range(sh.shape[0]):
- if sh[i]<pj[i]:
- sh[i]=1.0
- else:
- sh[i]=0.0
- return sh
- def update_visible(self,sh,uid,mid=None):
- if mid==None:
- vp=np.zeros(self.V.shape)
- for i in self.user_movie[uid]:
- vp[i]=np.exp(self.bik[i]+np.dot(self.W[i],sh))
- vp[i]=vp[i]/np.sum(vp[i])
- return vp
- vp=np.exp(self.bik[mid]+np.dot(self.W[mid],sh))
- vp=vp/np.sum(vp)
- return vp
- def sample_visible(self,vp,uid):
- sv=np.zeros(self.V.shape)
- for i in self.user_movie[uid]:
- r=uniform()
- k=0
- for k in range(self.Rate):
- r-=vp[i][k]
- if r<=0:break
- sv[i][k]=1
- return sv