简介
storm1.0版本的重要功能都在1.0.0版本中发布,1.0.1版本中以fixed bug为主,调研使用1.0.1版本.
storm1.0.0 :http://storm.apache.org/2016/04/12/storm100-released.html
Pacemaker
默认情况下使用zookeeper来存储心跳信息,需要修改配置。
storm.cluster.state.store "org.apache.storm.pacemaker.pacemaker_state_factory"
参考资料: https://storm.apache.org/releases/1.0.1/Pacemaker.html
官方性能指标
1、max 270 supervisor
2、2000-3000 nodes (max:6000nodes)
3、70% CPU、1G RAM (4core、24GRAM)
容错
1、pacemaker 挂掉:worker继续运行
2、网络分区(脑裂):与nimbus+pacemaker在同一侧的worker继续运行,另一侧重新分配。
测试Case
1、直接关闭Pacemaker,180分钟后重新启动pacemaker
结果:任务继续运行,期间没有发生飘移,一直尝试重试。
现场分析:
Nimbus与Worker一直尝试连接pacemaker。
重试策略采用:PacemakerClient.StormBoundedExponentialBackoffRetry【有限指数退避重试策略】
2、将其中一台机器的网卡数据拦截(脑裂),持续5-10分钟
HA Nimbus
HA 机制
1、Leader选举:通过curator提供的分布式锁来实现,谁获取锁谁是Leader。com.netflix.curator.framework.recipes.locks.InterProcessMutex
2、Topology codes:异步线程(Timer)检测本地不存在的任务代码,通过RPC向当前Leader下载任务代码。
3、Nimbus Leader:StormSubmitter,Supervisor,Non-leader Nimbus and Storm UI 角色通过zookeeper获取Nimbus Leader地址。
参考资料: https://github.com/apache/storm/pull/61
测试Case
1、直接停掉Nimbus Leader
结果:正在运行的任务没有飘移情况。
2、启动任务后,立刻停掉Nimbus Leader
结果:任务启动失败
3、storm kill 任务后,立刻停掉Nimbus Leader
结果:任务关闭失败,任务一直处于KILLED状态【僵尸任务,不执行】。
重启全部nimbus任务停止。
4、storm kill 任务后,过30秒[延迟任务关闭时间,可以配置,建议保持30],立刻停掉Nimbus Leader
结果:任务关闭成功。
5、关闭worker所在机器的supervisor进程(默认3秒检测一次worker进程)--> Kill -9 $workerPid ---> 关闭Nimbus Leader --->worker没有重新启动/飘走-->1分钟后启动supervisor --->worker飘移走
结果:worker成功飘移。
Automatic Backpressure
反压机制
1、worker executor的接收队列大于高水位,通知反压线程
2、worker反压线程通知zookeeper,executor繁忙事件
3、所有worker监听zookeeper executor繁忙的事件
4、worker spouts降低发送tuple速度
参考资料: https://github.com/apache/storm/pull/700
https://issues.apache.org/jira/browse/STORM-886
测试Case
1、基数分钟,前8秒,bolt处理消息逻辑sleep(1ms), spout一直全力发送数据。
backpressure.disruptor.high.watermark 0.9
backpressure.disruptor.low.watermark 0.4
topology.max.spout.pending null
结果:触发高水位,执行反压,经过几次反压,任务永久组塞,可以确认[bolt消息处理量==spout消息发送量]
2、bolt的TickTuple TOPOLOGY_TICK_TUPLE_FREQ_SECS设置为10秒,bolt处理逻辑为Utils.sleep(100ms),spout一直全力发送数据。
backpressure.disruptor.high.watermark 0.9
backpressure.disruptor.low.watermark 0.4
topology.max.spout.pending 1000
结果:触发高水位,执行反压,反复执行反压,任务正常。
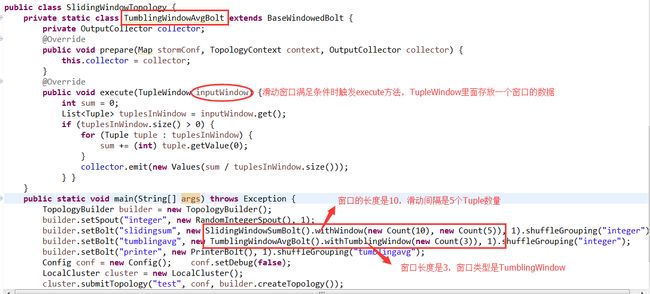
Native Streaming Window API
storm 1.0.X支持在窗口里处理一组tuple,窗口需要给定两个参数:窗口长度和滑动间隔。窗口计算的典型例子是可用于计算过去一小时最热门的Twitter话题
storm提供两种类型的窗口:
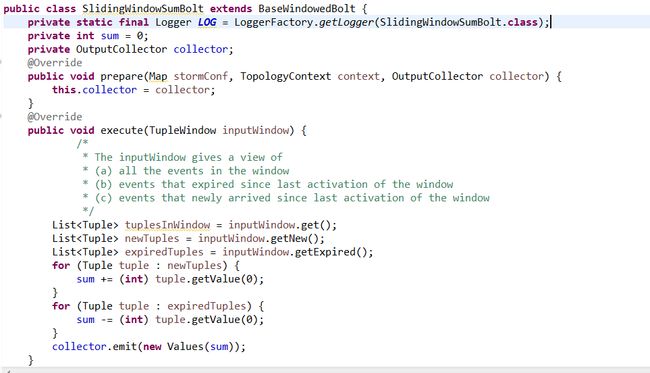
Sliding Window:一组Tuple被包含在一个窗口里,随着滑动间隔窗口不断滑动。一个tuple可能属于多个窗口。
Tumbling Window:一组Tuple被包含在单独一个基于时间或Tuple个数的窗口里,任意一个Tuple仅属于一个窗口。
用户使用窗口计算时需要继承BaseWindowedBolt类。
测试case
滑动窗口main方法
滑动窗口slide类
滑动窗口
Dynamic Log Levels
Storm 1.0允许用户和管理员通过Storm UI和命令行来更改运行中的Topology的日志级别的设置。用户可以指定一个可选的超时时间,超时时间过后,这些更改将被自动恢复。生成的日志文件也可以通过Storm UI和logviewer服务很容易的被搜索到。
测试Case
1.配置/Storm_home/log4j2/worker.xml,用户可以自定义Logger,
<RollingFile name="CUSTOM" immediateFlush="false"
fileName="${sys:storm.log.dir}/custom.log"
filePattern="${sys:storm.log.dir}/custom.log.%i.gz">
<PatternLayout>
<pattern>${pattern}</pattern>
</PatternLayout>
</RollingFile>
<Logger name="custom" level="warn" additivity="false"> /*自定义一个名为“custom”、warn级别的Logger,输出日志到custom.log文件中*/
<AppenderRef ref="CUSTOM"/>
</Logger>
2.Topology业务类中测试代码如下:
Logger logger=LoggerFactory.getLogger("custom");
logger.trace("trace........");
logger.debug("debug........");
logger.info("info..........");
logger.warn("warn..........");
logger.error("error........");
3.在Topology UI界面进行操作
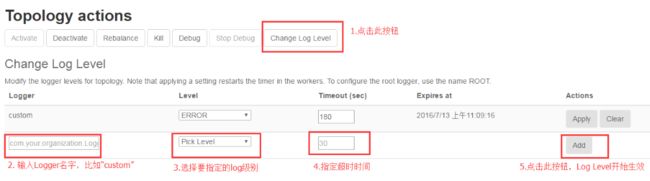
这里对Log Level作如下说明:
| Level | 描述 |
| ALL | 各级包括自定义级别 |
| TRACE | 指定细粒度比DEBUG更低的信息事件 |
| DEBUG | 指定细粒度信息事件是最有用的应用程序调试 |
| INFO | 指定能够突出在粗粒度级别的应用程序运行情况的信息的消息 |
| WARN | 指定具有潜在危害的情况 |
| ERROR | 错误事件可能仍然允许应用程序继续运行 |
| FATAL | 指定非常严重的错误事件,这可能导致应用程序中止 |
| OFF | 这是最高等级,为了关闭日志记录 |
它们的级别关系是All<Trace<Debug<Info<Warn<Error<Fatal<Off。
4.测试结果分析
事例中未使用动态Level时,custom.log中只打印出warn级别以上的信息,设置Level为info、Timeout为60时,打印出info、warn、error级别的信息,60秒后回归到原始级别状态。
UI界面上的“clear”按钮则用于清除这个Logger,不再打印日志信息。
Tuple Sampling and Debugging
在调试Topology的过程中,很多Strom用户添加了“debug”Bolt或者Trident功能,以记录流经Topology的数据信息,在生产部署的时候移除或者禁用它们。如今Storm UI包含这一功能,可以使你直接通过Storm UI对流经Topology或者单个组件的数据进行取样。被取样的事件可以通过Storm UI直接观察到,并被保存到磁盘。
使用说明
1.由于轻微的性能消耗,Storm默认没有开启这项功能,可以在cronf/storm.yaml中进行参数配置。
| Parameter | Meaning | When to use |
| topology.eventlogger.executors: 0 | No event logger tasks are created (default). | |If you don’t intend to inspect tuples and don’t want the slight performance hit. |
| topology.eventlogger.executors: 1 | One event logger task for the topology. | If you want to sample a low percentage of tuples from a specific spout or a bolt. This could be the most common use case. |
| topology.eventlogger.executors: nil | One event logger task per worker. | If you want to sample entire topology (all spouts and bolt) at a very high sampling percentage and the tuple rate is very high. |
Distributed Log Search
这是一个分布式日志搜索功能,用户通过Storm UI界面可以在指定Topology的所有日志文件中进行搜索,包括存档日志。搜索结果包含来自所有Supervisor节点的匹配。
在Storm UI首页点击指定的Topology Name后,在页面上方搜索框中输入关键词搜索即可。或者点击首页右上角的搜索图标,输入Topology ID和关键词后即可搜索。
Dynamic Worker Profiling
Storm 1.0最后一个改进是动态worker剖析。这个新功能可以让用户直接从Storm UI获取worker剖析数据,包括:
Heap Dumps
JStack Output
JProfile Recordings
生成的文件,可以下载,使用各种调试工具离线分析,storm1.0.x可以通过Storm UI重启worker。