读书笔记 机器学习(周志华)第四章 决策树
读书笔记 机器学习(周志华)第四章 决策树
- 4.1 基本流程
- 4.2 划分选择
- 4.2.1 信息增益
- 4.2.2 增益率
- 4.2.3 基尼系数
- 4.3 剪枝处理
- 4.3.1 预剪枝
- 4.4 连续与缺失值
- 4.4.1 连续值处理
4.1 基本流程
“决策树”(decision tree):基于树结构进行决策。一般的,一颗决策树包含一个根节点、若干个内部节点和若干个叶节点。根结点包含样本全集,叶节点对应决策结果,其他每个节点对应一个属性测试。从根结点到每个叶结点的路径对应一个判定测试序列。
4.2 划分选择
随着划分过程的进行,我们希望决策树分支结点所包含的样本尽可能同属一类,即结点的“纯度”尽可能高。
4.2.1 信息增益
“信息熵”(information entropy):度量样本纯度最常用的指标。
假定样本D中第k类样本所占比例为 p k p_k pk,则D的信息熵定义为
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent(D)=-\sum_{k=1}^{|y|}{p_klog_2p_k} Ent(D)=−k=1∑∣y∣pklog2pk
E n t ( D ) Ent(D) Ent(D)的值越小,则D的纯度越高;反之,纯度越低。
“信息增益”(information gain):用属性a进行划分时所获得的“信息增益”表达式为
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ C v ∣ ∣ D ∣ E n t ( C v ) Gain(D,a)=Ent(D)-\sum_{v=1}^{V}\frac{|C_v|}{|D|}{Ent(C_v)} Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Cv∣Ent(Cv)
其中, V V V为以 a a a属性划分的节点数, ∣ C v ∣ |C_v| ∣Cv∣为第 v v v个节点中的样本总数, ∣ D ∣ |D| ∣D∣为划分前节点的样本总数。
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的的“纯度提升”越大。
因此,我们可以根据信息增益(Gain)来选择结点,一般选择信息增益最大的属性作为划分结点。
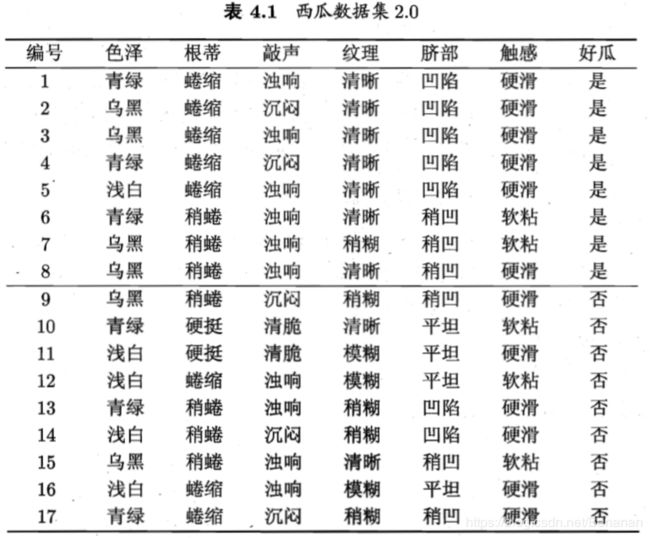
以 西瓜数据集2.0 为例,该数据集D包含17个训练样本。根结点包含D中多有样本,共8个正例,9个反例,即正例 p 1 = 8 17 p_1=\frac{8}{17} p1=178,反例 p 2 = 9 17 p_2=\frac{9}{17} p2=179,根据信息熵计算公式得
E n t ( D ) = − ∑ k = 1 2 p k l o g 2 p k = − ( 8 17 l o g 2 8 17 + 9 17 l o g 2 9 17 ) = 0.998 Ent(D) = -\sum_{k=1}^2{p_klog_2{p_k}}=-(\frac{8}{17}log_2{\frac{8}{17}}+\frac{9}{17}log_2{\frac{9}{17}})=0.998 Ent(D)=−k=1∑2pklog2pk=−(178log2178+179log2179)=0.998
对D按属性a进行分类,a是{色泽、根蒂、敲声、纹理、脐部、触感}中的某一个属性。以色泽为例,色泽包含3个可能值{乌青、乌黑、浅白},即按色泽属性分类,D可得到3个子集,标记为: C 1 C_1 C1(色泽=乌青), C 2 C_2 C2(色泽=乌黑), C 3 C_3 C3(色泽=浅白)。
C 1 C_1 C1包含{1、4、6、10、13、17},正例 p 1 = 1 2 p_1=\frac{1}{2} p1=21,反例 p 2 = 1 2 p_2=\frac{1}{2} p2=21;
C 2 C_2 C2包含{2、3、7、8、9、15},正例 p 1 = 2 3 p_1=\frac{2}{3} p1=32,反例 p 2 = 1 3 p_2=\frac{1}{3} p2=31;
C 2 C_2 C2包含{5、11、12、14、16},正例 p 1 = 1 5 p_1=\frac{1}{5} p1=51,反例 p 2 = 4 5 p_2=\frac{4}{5} p2=54。
三个支点的信息熵为:
E n t ( C 1 ) = − ∑ k = 1 2 p k l o g 2 p k = − ( 1 2 l o g 2 1 2 + 1 2 l o g 2 1 2 ) = 1 E n t ( C 2 ) = − ∑ k = 1 2 p k l o g 2 p k = − ( 2 3 l o g 2 2 3 + 1 3 l o g 2 1 3 ) = 0.918 E n t ( C 3 ) = − ∑ k = 1 2 p k l o g 2 p k = − ( 1 5 l o g 2 1 5 + 4 5 l o g 2 4 5 ) = 0.722 Ent(C_1) = -\sum_{k=1}^2{p_klog_2{p_k}}=-(\frac{1}{2}log_2{\frac{1}{2}}+\frac{1}{2}log_2\frac{1}{2})=1\\ Ent(C_2) = -\sum_{k=1}^2{p_klog_2{p_k}}=-(\frac{2}{3}log_2{\frac{2}{3}}+\frac{1}{3}log_2\frac{1}{3})=0.918\\ Ent(C_3) = -\sum_{k=1}^2{p_klog_2{p_k}}=-(\frac{1}{5}log_2{\frac{1}{5}}+\frac{4}{5}log_2\frac{4}{5})=0.722 Ent(C1)=−k=1∑2pklog2pk=−(21log221+21log221)=1Ent(C2)=−k=1∑2pklog2pk=−(32log232+31log231)=0.918Ent(C3)=−k=1∑2pklog2pk=−(51log251+54log254)=0.722
根据信息增益计算公式得出属性“色泽”的信息增益为
G a i n ( D , 色 泽 ) = E n t ( D ) − ∑ v = 1 3 ∣ C v ∣ ∣ D ∣ E n t ( C v ) = 0.998 − ( 6 17 × 1 + 6 17 × 0.918 + 5 17 × 0.722 ) = 0.109 Gain(D,色泽)=Ent(D)-\sum_{v=1}^{3}\frac{|C_v|}{|D|}{Ent(C_v)}\\ =0.998-(\frac{6}{17}\times1+\frac{6}{17}\times0.918+\frac{5}{17}\times0.722)\\=0.109 Gain(D,色泽)=Ent(D)−v=1∑3∣D∣∣Cv∣Ent(Cv)=0.998−(176×1+176×0.918+175×0.722)=0.109
同理,我们可以得出其他属性的信息增益:
G a i n ( D , 根 蒂 ) = 0.143 ; G a i n ( D , 敲 声 ) = 0.141 ; G a i n ( D , 纹 理 ) = 0.381 ; G a i n ( D , 脐 部 ) = 0.289 ; G a i n ( D , 触 感 ) = 0.006. Gain(D,根蒂)=0.143; \\Gain(D,敲声)=0.141; \\Gain(D,纹理)=0.381; \\Gain(D,脐部)=0.289; \\Gain(D,触感)=0.006. Gain(D,根蒂)=0.143;Gain(D,敲声)=0.141;Gain(D,纹理)=0.381;Gain(D,脐部)=0.289;Gain(D,触感)=0.006.
显然,“纹理”的信息增益最大,因此它应该别选为划分属性。
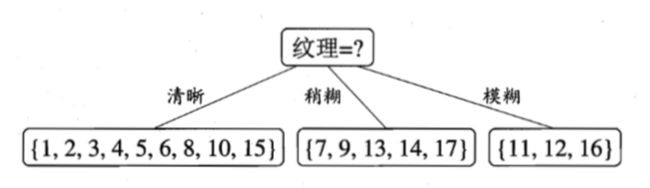
决策树继续对每个分支进行划分。以上图第一个分支点(纹理=清晰)为例,该节点包含{1,2,3,4,5,6,8,10,15}9个样本,可供选择属性有{色泽、根蒂、敲声、脐部、触感}5个属性。同理计算出各个属性的信息增益:
G a i n ( C 1 , 色 泽 ) = 0.043 ; G a i n ( C 1 , 根 蒂 ) = 0.458 ; G a i n ( C 1 , 敲 声 ) = 0.331 ; G a i n ( C 1 , 脐 部 ) = 0.458 ; G a i n ( C 1 , 触 感 ) = 0.458. Gain(C_1,色泽)=0.043;\\ Gain(C_1,根蒂)=0.458;\\ Gain(C_1,敲声)=0.331;\\ Gain(C_1,脐部)=0.458;\\ Gain(C_1,触感)=0.458. Gain(C1,色泽)=0.043;Gain(C1,根蒂)=0.458;Gain(C1,敲声)=0.331;Gain(C1,脐部)=0.458;Gain(C1,触感)=0.458.
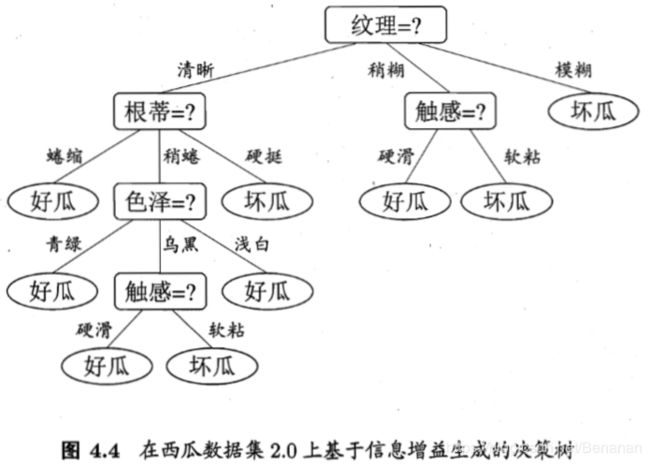
“根蒂”,“脐部”,“触感”3个属性同时取得了最大信息增益,可任选其中之一作为划分属性。同理,继续进行节点划分,最终可得如下决策树。
4.2.2 增益率
“增益率”(gain ratio):C4.5决策树算法,使用增益率来选择最优划分属性。
G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) Gain\_ratio(D,a)=\frac{Gain(D,a)}{IV(a)} Gain_ratio(D,a)=IV(a)Gain(D,a)
其中
I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ l o g 2 ∣ D v ∣ D IV(a)=-\sum_{v=1}^V\frac{|D^v|}{|D|}log_2\frac{|D^v|}{D} IV(a)=−v=1∑V∣D∣∣Dv∣log2D∣Dv∣
称为属性a的“固有值”。属性a的可能取值越多(V越大),则IV(a)通常也越大。西瓜数据集2.0 中,
I V ( 触 感 ) = 0.874 ( V = 2 ) , I V ( 色 泽 ) = 1.58 ( V = 3 ) , I V ( 编 号 ) = 4.088 ( V = 17 ) . IV(触感)=0.874(V=2),\\ IV(色泽)=1.58(V=3), \\IV(编号)=4.088(V=17). IV(触感)=0.874(V=2),IV(色泽)=1.58(V=3),IV(编号)=4.088(V=17).
C4.5算法不直接选择增益率最大的候选划分属性,而是先从候选划分属性中找出信息增益高于平均水平的属性,在从中选择增益率最高的。
4.2.3 基尼系数
“基尼系数”(Gini index):
G i n i ( D ) = ∑ k = 1 ∣ y ∣ ∑ k ′ ≠ k p k p k ′ = 1 − ∑ k = 1 ∣ y ∣ p k 2 Gini(D) =\sum_{k=1}^{|y|}\sum_{k'\ne k}p_{k}p_{k'}=1-\sum_{k=1}^{|y|}{p_k^2} Gini(D)=k=1∑∣y∣k′̸=k∑pkpk′=1−k=1∑∣y∣pk2
一般来说,Gini(D)反映从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此Gini(D)越小,则D纯度约高。
4.3 剪枝处理
“剪枝”(pruning)是决策树算法对付“过拟合”的主要手段。
通过主动去掉一些分支来降低过拟合的风险。基本策略有“预剪枝”(prepruning)和“后剪枝”(post-pruning)。
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点不能带来泛化能力的提升,则停止划分并将该结点标记为叶结点。
后剪枝就是先从训练集中生成一颗完整的决策树,然后自下向上对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化能力的提升,则将该子树替换为叶结点。
如何验证决策树泛化性能是否提升,采用“留出法”,预留一部分数据作“验证集”进行性能评估。
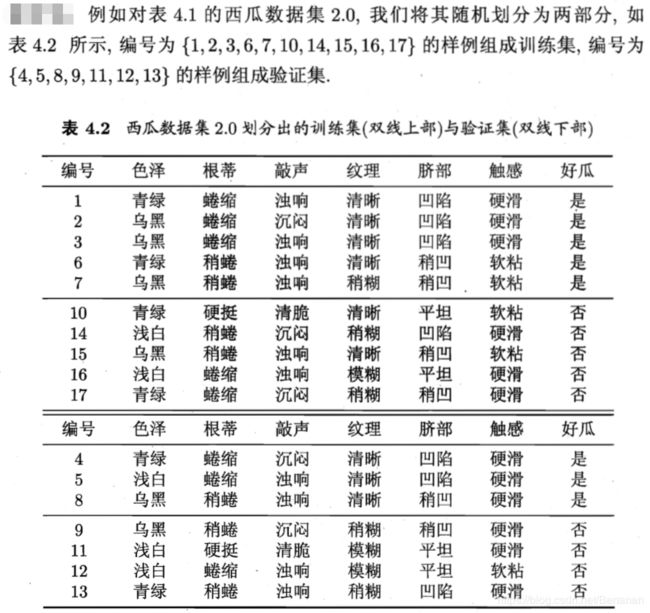
采用信息增益的标准进行划分。
4.3.1 预剪枝
对每一个结点进行划分前与划分后对比。
4.4 连续与缺失值
4.4.1 连续值处理
“二分法”对连续属性进行处理