一文读懂GAN, pix2pix, CycleGAN和pix2pixHD
本文翻译、总结自朱俊彦的线上报告,主要讲了如何用机器学习生成图片。
来源:Games2018 Webinar 64期 :Siggraph 2018优秀博士论文报告
人员信息
主讲嘉宾
姓名:朱俊彦(Jun-Yan Zhu)
现状:麻省理工学院博士后(PostDoc at MIT),计算机科学与人工智能实验室(Computer Science and Artificial Intelligence Laboratory, CSAIL)
个人主页:http://people.csail.mit.edu/junyanz/
主持人
周晓巍
现状:浙江大学CAD&CG国家重点实验室
个人主页:http://www.cad.zju.edu.cn/home/xzhou/
报告内容
这是机器学习滴时代!
计算机视觉(Computer Vision, CV)领域近年来发生了巨大的变化。在2012年之前,CV的主要研究方法是使用**人工设计(hand-designed)**的特征完成各种任务(见下图)。

2012年使用深度神经网络(Deep Neural Network, DNN) 在ImageNet的分类任务上取得了巨大成功(见下图)。

从此**深度学习(Deep Learning)**的相关研究如火如荼地展开了,比如说下面这三个栗子:
- 物体识别(Object detection) [Redmon etal., 2018]
- 对人体的理解(Human understanding) [Guler et al., 2018]
- 自动驾驶(Autonomous driving) [Zhao et al., 2017]

图形学中的尝试:趁手的武器 or 白费功夫?
在传统的图形学管线(pipeline)中,输出图像需要经过建模、材质贴图、光照、渲染等一系列繁琐的步骤(见下图)。

现在大家看到了Deep Learning的潜力,那我们自然的就有个想法:有没有可能使用Deep Learning简化计算机图形学(Computer Graphics)的研究呢?
一个直接的想法是把DNN“倒过来用”。之前的DNN可能是输入一幅图像,输出一个标签(比如说猫),那我们能不能输入“猫”这个字,输出一张猫的照片呢?

很遗憾,答案是No!因为这种任务实在太复杂啦!我们很难让DNN凭空输出图像这样的高维数据(High dimensional data)(这里的“高维”可以理解成数据量大)。实际上,在很长一段时间里,DNN只能输出数字这种简单的、低分别率的小图像,就像下面这样:

而想要生成想游戏场景这类的图片,这种方法根本没用。所以,我们必须得想出更厉害滴东西完成这项任务(使命感爆棚)!
GAN就完了?Naive!
于是…在月黑风高的某一天(画风逐渐跑偏),一个叫做生成对抗网络(Generative Adversarial Network)——也就是大名鼎鼎的GAN——的东西横空出世。作者是下面这位小哥和他的小伙伴们:

那么,我们该怎么GAN出图像呢?且听我细细道来~
一般来说,GAN中包含两种类型的网络 G G G和 D D D。其中, G G G为Generator,它的作用是生成图片,也就是说,在输入一个随机编码(random code) z z z之后,它将输出一幅由神经网络自动生成的、假的图片 G ( z ) G(z) G(z)。
另外一个网络 D D D为Discriminator是用来判断的,它接受 G G G输出的图像作为输入,然后判断这幅图像的真假,真的输出1,假的输出0。

在两个网络互相博弈(金坷垃日本人:不邀哒架)的过程中,两个网络的能力都越来越高: G G G生成的图片越来越像真的图片, D D D也越来越会判断图片的真假。到了这一步,我们就能“卸磨杀驴”——丢掉 D D D不要了,把 G G G拿来用作图片生成器。
正式一点儿讲(上公式啦),我们就是要在最大化 D D D的能力的前提下,最小化 D D D对 G G G的判断能力,这是一个最小最大值问题,它的学习目标是:
min G max D E [ log D ( G ( z ) ) + log ( 1 − D ( x ) ) ] \min\limits_{G} \max\limits_D \mathbb{E} [\log D(G(z)) + \log (1- D(x))] GminDmaxE[logD(G(z))+log(1−D(x))]
为了增强 D D D的能力,我们分别考虑输入真的图像和假的图像的情况。上式中第一项的 D ( G ( z ) ) D(G(z)) D(G(z))处理的是假图像 G ( z ) G(z) G(z),这时候评分 D ( G ( z ) ) D(G(z)) D(G(z))需要尽力降低;第二项处理的是真图像 x x x,这时候的评分要高。
GAN的局限性
即便如此,传统的GAN也不是万能的,它有下面两个不足:
1. 没有**用户控制(user control)**能力
在传统的GAN里,输入一个随机噪声,就会输出一幅随机图像。

但用户是有想法滴,我们想输出的图像是我们想要的那种图像,和我们的输入是对应的、有关联的。比如输入一只喵的草图,输出同一形态的喵的真实图片(这里对形态的要求就是一种用户控制)。

2. 低分辨率(Low resolution)和低质量(Low quality)问题
尽管生成的图片看起来很不错,但如果你放大看,就会发现细节相当模糊。

怎样改善?
前面说过传统的GAN的种种局限,那么现在,我们相应的目标就是:
- 提高GAN的用户控制能力
- 提高GAN生成图片的分辨率和质量
为了达到这样的目标,和把大象装到冰箱里一样,总共分三步:
- pix2pix:有条件地使用用户输入,它使用**成对的数据(paired data)**进行训练。
- CycleGAN:使用**不成对的数据(unpaired data)**的就能训练。
- pix2pixHD:生成高分辨率、高质量的图像。
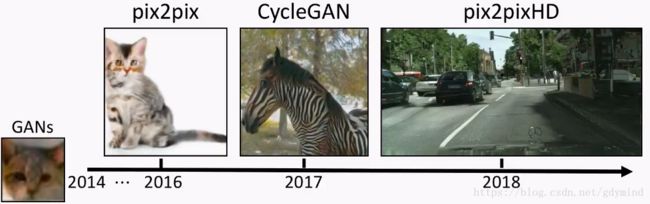
下面分别进行详细叙述~
pix2pix
pix2pix对传统的GAN做了个小改动,它不再输入随机噪声,而是输入用户给的图片:
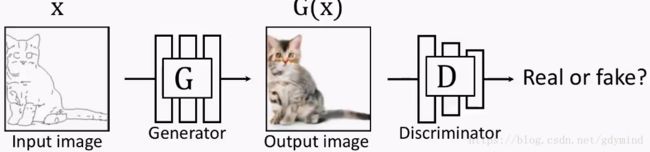
但这也就产生了新的问题:我们怎样建立输入和输出的对应关系。此时 G G G的输出如果是下面这样, D D D会判断是真图:

但如果 G G G的输出是下面这样的, D D D拿来一看,也会认为是真的图片QAQ…也就是说,这样做并不能训练出输入和输出对应的网络 G G G,因为是否对应根本不影响 D D D的判断。

为了体现这种对应关系,解决方案也很简单,你可以也已经想到了:我们把** G G G的输入和输出一起作为 D D D的输入**不就好了?于是现在的优化目标变成了这样:
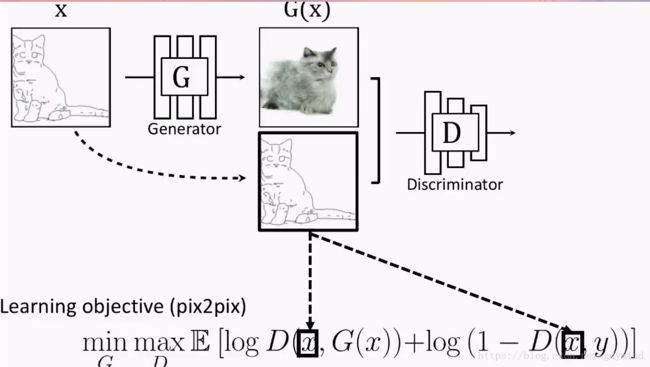
这项研究还是挺成功的,大家可以去这里在线体验一下demo,把草图(sketch)变成图片。
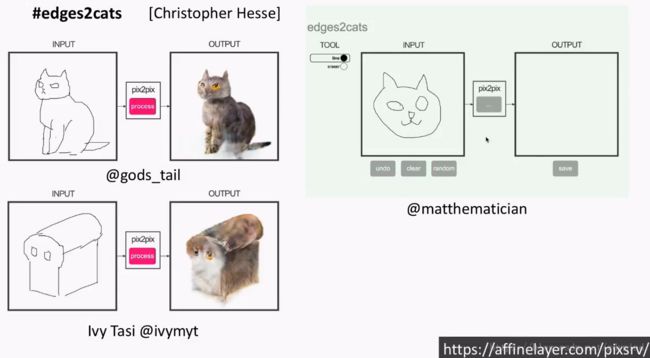
当然,有些比较皮的用户输入了奇形怪状的草图,然后画风就变成了这样:

应用
pix2pix的核心是有了对应关系,这种网络的应用范围还是比较广泛的,比如:
- 草图变图片[Isola, Zhu, Zhou, Efros, 2016]:
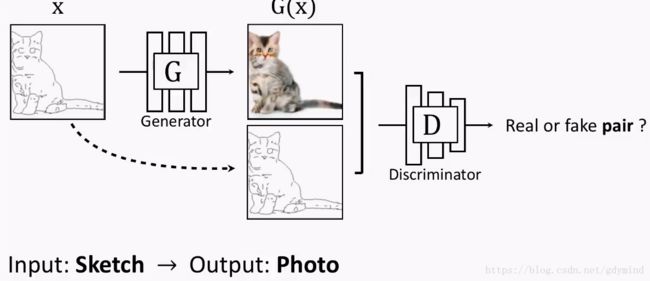
- 灰度图变彩色图[Isola, Zhu, Zhou, Efros, 2016]:
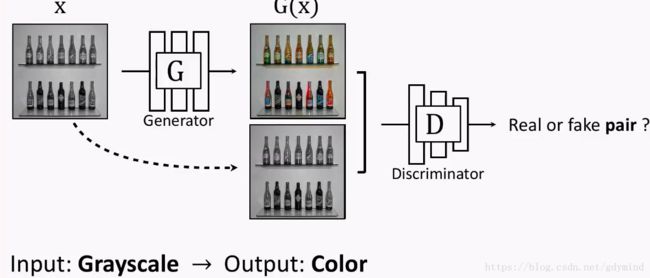
- 自动着色 Data from [Russakovsky et al. 2015]:

- 交互式着色[Zhang*, Zhu*, Isola, Geng, Lin, Yu, Efros, 2017]:

CycleGAN
pix2pix必须使用成对的数据进行训练。

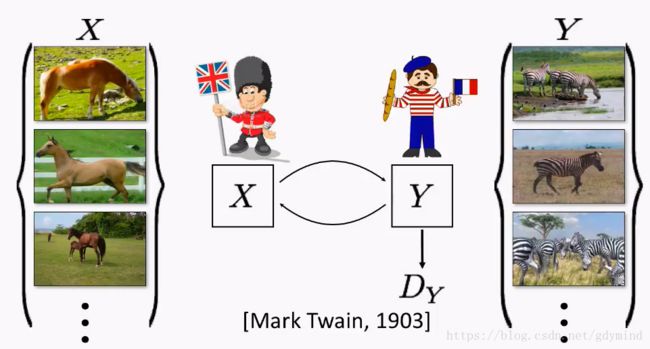
但很多情况下成对数据是很难获取到的,比如说,我们想把马变成斑马,现实生活中是不存在对应的真实照片的:

现在我们就用Cycle-constraint Adversarial Network也就是CycleGAN解决这个问题。这种网络不需要成对的数据,只需要输入数据的一个集合(比如一堆马的照片)和输出数据的一个集合(比如一堆斑马的照片)就可以了。

但是(没错我又要说但是了),直接使用不成对的数据是不奏效的。网络会直接忽略输入,随机产生输出!所以,我们还得对网络增加**限制(constraint)**才行。
那怎么加限制呢?我们来思考一个现实问题。马克吐温认为,如果一把一段话从英文翻译成法文,再从法文翻译回英文,那么你应该得到跟之前原始输入的英文一样的内容。这里也是一样,如果我们把马变成斑马,然后再变回马,那么最后的马和开始输入的马应该是一样的。
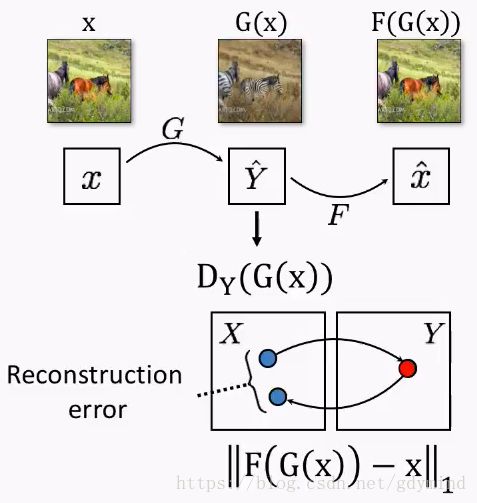
下面讲一下具体技术细节。除了之前提到的把马变成斑马的网络 G G G,我们还需要一个把斑马变回马的网络 F F F。
那么,一匹马 x x x用 G G G变成斑马 s = G ( x ) s = G(x) s=G(x),然后再用 F F F把它变回马 F ( s ) F(s) F(s),得到的马和一开始的马应该是一样的,也就是 x = F ( G ( x ) ) x = F(G(x)) x=F(G(x))。
反过来,斑马变马再变回斑马也要满足要求,注意这一步最好不要省略。虽然理论上只用一个条件是可以的,但是现实实现中,有很多因素,比如计算的准备度,优化的问题,应用中都是把所有约束都加上。比如说 a = b = c a=b=c a=b=c,理论上我们只要要求$(a-b)2+(a-c)2=0 , 但 现 实 中 我 们 都 是 做 ,但现实中我们都是做 ,但现实中我们都是做(a-b)2+(a-c)2+(b-c)^2=0$。
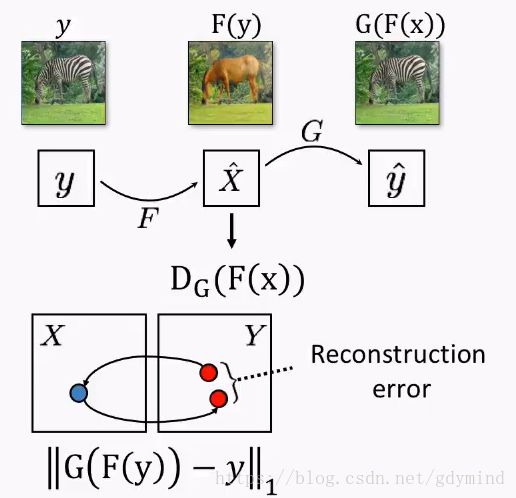
我们同时优化 G G G和 F F F,最后就能拿到一个想要的网络 G G G。
CycleGAN为什么有效
CycleGAN成功的原因在于它分离了风格(Style)和内容(content)。人工设计这种分离的算法是很难的,但有了神经网络,我们很容易让它学习者去自动保持内容而改变风格。
效果展示
下面是效果展示环节~
马变斑马
两张图片分别是原来的马和 G G G duang的一下变出的斑马:


橘子变苹果:


可以看到,CycleGAN能够比较准确的找到橘子的位置,并把它变成苹果。
图像风格的迁移:


游戏场景替换
这个应用就很酷了,它以一些德国城市的照片作为输入,成功替换了游戏GTA5中的场景!


失败例子
在输入骑马的普京大帝照片时,输出图像里把普京也变成了斑马。

这是因为,训练图像里并没有骑马的人,所以网络就傻掉了。
目前暂且的解决办法是先用Mask R-CNN做图像分割之后再针对马进行变化,不过这个效果也不好,因为人和马在图像上有重叠的部分。这个问题需要未来解决。
源代码
这里给出CycleGAN和pix2pix的github项目。
这是2017年github最受欢迎的项目之一,截止到本文写作时间(2018年9月),已经有5000+ Star了:

课程
CycleGAN现在非常火,以致于很多大学和在线平台都开设了它的课程:

用户的结果
下面是这些课程里的一些学生作业:
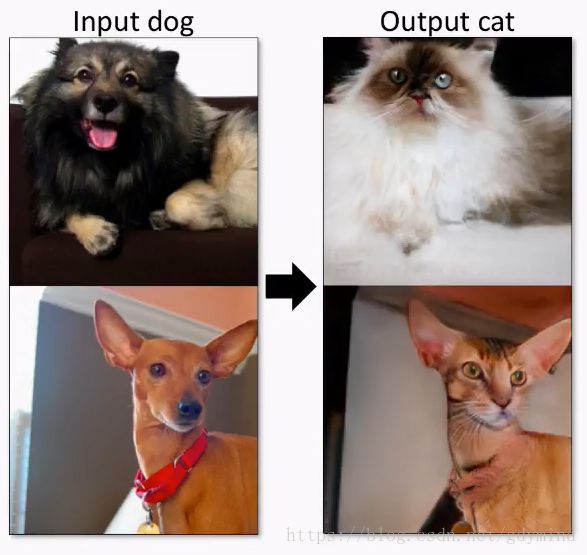
Twitter上也有一些很有趣的应用,比如把狗变成猫@itok_msi:
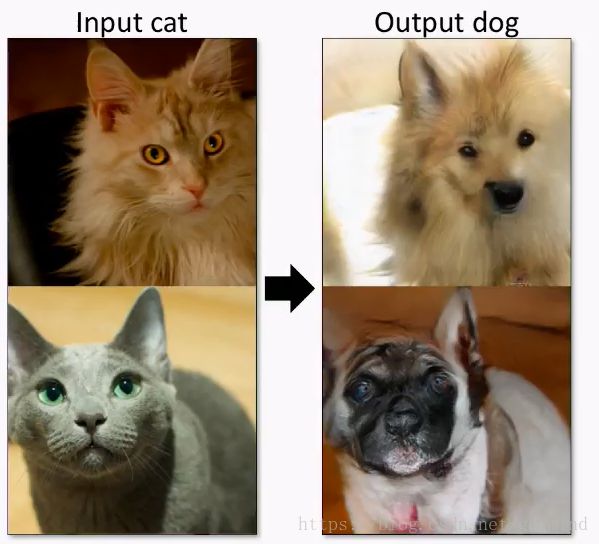
或者把猫变成狗:
再比如“吃鸡”游戏的风格转换@Cahintan Trivedi:
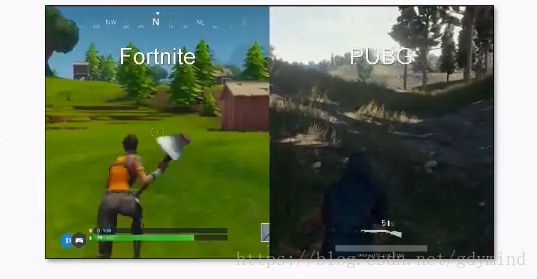
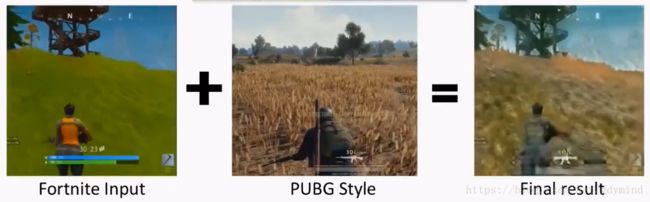
不过这里存在一个严重的问题:CycleGAN只能输出256p/512p的低分辨率图像。
pix2pixHD
是的,我们还剩一个悬而未决的问题:分辨率和图像质量。pix2pixHD就是用来解决这个问题的!
假设我们输入一张高分辨率的草图:

使用pix2pix,结果很差(之前说过,让网络产生高维数据输出很难):

pix2pixHD采取了金字塔式的方法:
- 先输出低分辨率的图片。
- 将之前输出的低分辨率图片作为另一个网络的输入,然后生成分辨率更高的图片。
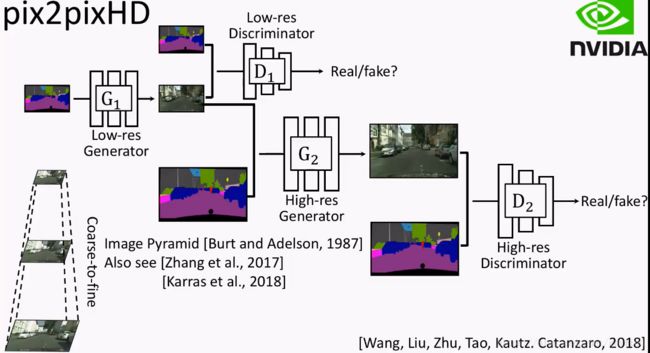
这样,就把一个困难的问题拆分成了两个相对简单的问题~
最终的效果是,给定下面的高分辨率草图:

pix2pixHD可以**实时(real time)**产生这样的效果:

pix2pixHD也支持用户交互,比如加一辆车、添几棵树之类的:
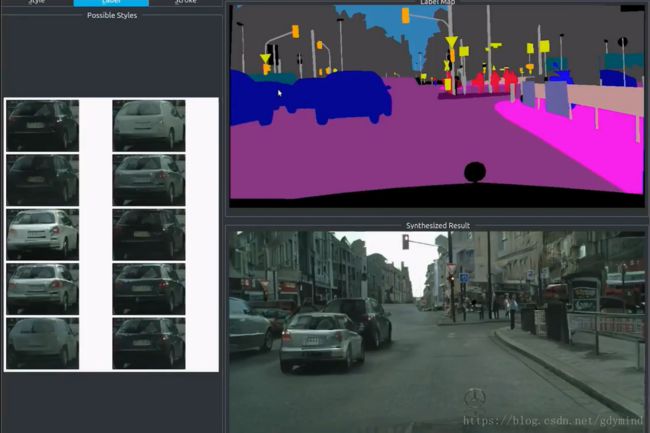
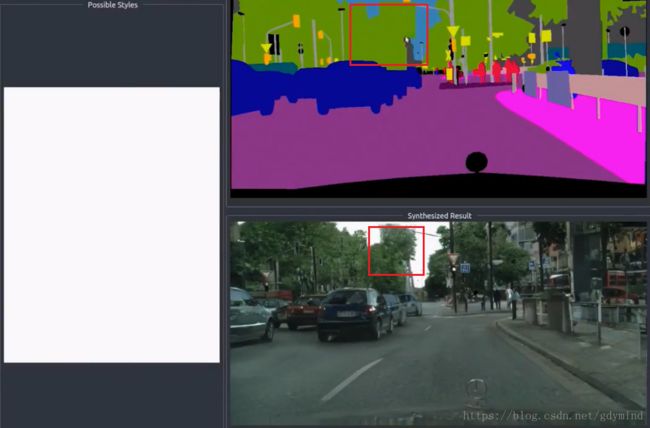
pix2pixHD还有许多有趣的应用。
比如用草图生成高分辨率人脸:


再比如:
- 图像增强(Image Enhancement)
- 图像去雾(Image Dehazing)
- 非监督动作重定向Neural Kinematic Networks for Unsupervised Motion Retargetting
其他问题
目前生成的斑马视频帧与帧之间的纹理变化较大,为了解决帧之间的连续性问题,新的研究工作应运而生:Video-to-Video Synthesis。
它主要的解决思路有下面三个:
- 输入一段视频中的几帧,检查真假
- 把前面的帧当做后面帧的输入
- 使用“optical flow”,具体请看paper
总结
本文介绍了怎样用神经网络生成图片,我们使用pix2pix完成了基本任务,使用CycleGAN解决了输入数据不成对的问题,最后用pix2pixHD解决了图像分辨率和图像质量的问题。