基于ISODATA算法的RFM聚类
1. ISODATA算法即迭代自组织数据分析方法。是在k-means算法的基础上增加对聚类结果的“合并”和“分裂”两个操作,并设定算法运行控制参数的一种聚类算法。
2. “合并”操作:当聚类结果某一类中样本数太少,或两个类间的距离太近时,进行合并。
3. “分裂”操作:当聚类结果某一类中样本某个特征类内方差太大,将该类进行分裂。迭代次数会影响最终结果,迭代参数选择很重要。
4. 优势:解决了K-means算法事先选定好的固定k值,也解决了在运行效率上的不足。
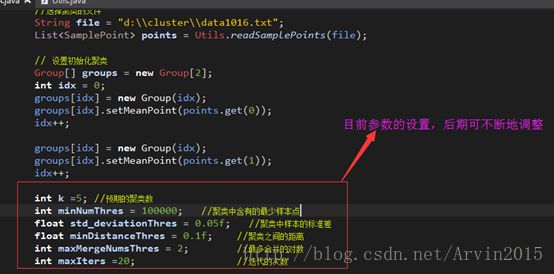
5. ISODATA参数的设置
| 参数 |
说明 |
| K |
预期的聚类数 |
| minNumThres |
一个簇中至少包含的样本点 |
| std_deviationThres |
簇中样本的标准差阈值 |
| minDistanceThres |
簇与簇之间的距离 |
| maxMergeNumsThres |
再一次迭代中可以合并的最多对数 |
| maxIters |
迭代的次数 |
6. 基于ISODATA算法的客户价值分析步骤:
①数据集准备:(采用R语言导出结果集)
library(RJDBC)
library(fpc)
drv=JDBC("oracle.jdbc.OracleDriver","C:\\ProgramFiles\\R\\ojdbc6.jar",identifier.quote="\"")
conn=dbConnect(drv,"jdbc:oracle:thin:@//ip地址/数据库","用户名","密码")
tt=dbGetQuery(conn,"selectrownum,rfmdate,custid,r,f,m from (SELECT t.rfm_date as rfmdate,t.cust_id ascustid,t.r_value as r,t.f_value as f,t.m_value as m FROM yg_tb_rfm_cust_detailt where t.rfm_date>='201701' order by custid)")
r=tt$R
f=tt$F
m=tt$M
datafile<-data.frame(r,f,m)
data<-scale(datafile) #由于数据减差值较大因此数据规范化处理
write.table(data,”d:\\cluster\\data.txt”,row.names=FALSE,col.names=FALSE) #导出txt文本,对于一次加载到内存中分析较快
②加载data.txt数据,采用ISODATA进行数据分析。
③结果集输出:

结果集格式:

④将结果集导入到数据库进行分析:
select t.*, r.cluster_num
from (select rownum as row_id,rfmdate, custid, r, f, m
from (SELECT t.rfm_date asrfmdate,
t.cust_id as custid,
t.r_value as r,
t.f_value as f,
t.m_value as m
FROMyg_tb_rfm_cust_detail t
where t.rfm_date ='201701'
order by custid)) t,
yg_tb_rfm_cust_result r
where t.row_id = r.cluster_id

⑤统计分析:



根据RFM规则:
第一类用户(001):重要挽留客户。最近消费时间较远、消费频次不高,但消费金额高的用户,可能是将要流失或者已经要流失的用户,应该采取挽留措施。
第二类用户(011):重要保持客户。最近消费时间较远,但消费频次和金额都很高,说明这是个一段时间没来的忠诚客户,应该和客户继续保持联系。
第三类用户(101):重要发展客户。最近消费时间较近、消费金额高,但频次不高,很有潜力的用户,应该重点发展。
第四类用户(111):重要价值用户。最近消费时间近、消费频次和消费金额都很高。应给予vip条件对待。
ISODATA 算法的java代码下载 见 http://download.csdn.net/download/arvin2015/10243550