Amazon Aurora 深度探索

作者简介:李海翔,腾讯金融云数据库技术专家。网名那海蓝蓝,熟悉PostgreSQL、MySQL、Informix等。数据库内核技术。腾讯金融云数据库技术专家。著有《数据库查询优化器的艺术》,即将出版新书《数据库事务处理的艺术》。
导语:Amazon的Aurora自从问世,就备受关注,其性能和实现架构是被关注的热点。2017年,Amazon发表了一篇论文,披露其实现的一些技术细节。本文在此背景下,对Aurora系统的实现从整体架构、存储、事务处理三个方面进行深入探讨,基于其论文和相关资料讨论具体实现细节,又跳出其外、从数据库内核技术实现的角度对Aurora做了一定的推测。接着对Aurora用技术构建起的强大云数据库服务能力进行探索。最后总结了一些问题,以期有更多的讨论和思考,一起来探索云数据库的技术未来。
目录
Amazon Aurora深度探索
1 Aurora的整体架构
1.1 物理设施与架构
1.2 核心技术与架构
1.3 其他组件
2 Aurora的存储架构
2.1 存储层的工作
2.2 储存层的设计讨论
2.3 Aurora设计的优点
3 Aurora的事务处理
3.1 持久性
3.2 事务与数据分布
3.3 事务处理
3.4 锁管理
4 云服务能力
4.1 强化的云服务能力
4.2 万能数据库
5 小结
附录
Amazon Aurora深度探索
2017年,Amazon在SIGMOD上发表了论文《Amazon Aurora: Design Considerations for High Throughput CloudNative Relational Databases》。
这篇论文,描述了Amazon的云数据库Aurora的架构。基于MySQL的Aurora对于单点写多点读的主从架构做了进一步的发展,使得事务和存储引擎分离,为数据库架构的发展提供了具有实战意义的已实践用例。其主要特点如下:
实践了“日志即数据库”[①]的理念。
事务引擎和存储引擎分离。
数据缓冲区提前预热。
REDO日志从事务引擎中剥离,归并到存储引擎中。
储存层可以有6个副本,多个副本之间通过Gossip协议可以保障数据的“自愈”能力。
主备服务的备机可达15份,提供强大的读服务能力。
持续可靠的云数据库的服务能力。
数据存储跨多个区:提供了多级别容灾能力。
数据容灾能力:数据冗余、备份、实时恢复等多种能力集成到云服务,提高的数据的保障能力。
万能数据库的概念呼之欲出。之所以有这样的设计,是因为Amazon认为:网络IO已经成为数据库最大的瓶颈[②]。
1. Aurora的整体架构
认识Aurora的整体架构,需要先理解AWS的物理设施,而论文中对Aurora基于的物理设施着墨不多,所以我们先来掌握物理设施与整体架构的关系。
1.1 物理设施与架构
Aurora的计算节点和存储节点分离,分别位于不同的VPC(Virtual Private Cloud)中。这是Aurora架构最亮眼之处。
如图1-1,用户的应用,通过Customer VPC接入,然后可以读写位于不同AZ(Availability Zone)的数据库。而不同的AZ分布于全球的不同的Region中(如图1-2[③],截止到2017年初,AWS全球有16个区域即Region,有42个可用区即AZ,每个Region至少有2个AZ。而每个AZ由两到多个数据中心组成,数据中心不跨AZ,每个AZ内部的数据延迟低于0.25ms[④]。AWS文档称,AZ之间的延迟低于2ms通常小于1ms)。
数据库的部署,是一主多从的集群架构,图1-1的Primary RW DB是写数据的节点,只能有一个(这点说明Aurora还是传统的数据库架构,不是真正的对等分布式架构,这点也是一些批评者认为Aurora缺乏真正创新之处)。而Secondary RO DB是只读的从节点,由零到多个备节点组成,最多可以有15个。主从节点可以位于不同的AZ(最多位于3个VPC,需要3个AZ)但需要位于同一个Region内,节点通过RDS (Relational Database Service)来交互。
RDS是由位于每个节点上的称为HM(HostManager)的agent来提供主从集群的状态监控、以应对主节点fail over的问题以便进行HA调度、以及某个从节点fail over需要被替换等问题。这样的监控服务,称为control plane。
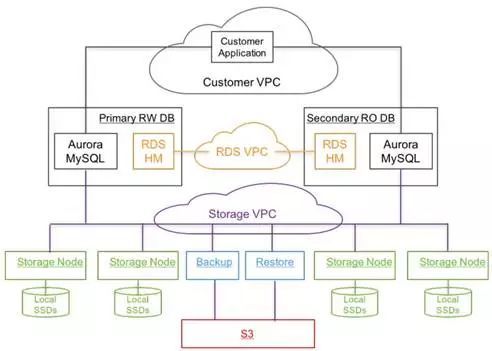
图1-1 Aurora整体架构
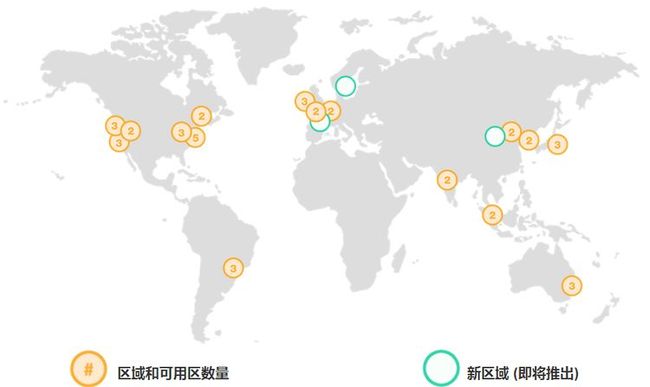
![]()
图1-2 Aurora的Region分布图
数据库的计算服务和存储分离,数据缓冲区和持久化的“数据”(对于Aurora实则是日志和由日志转化来的以page为单位的数据,而不是直接由数据缓冲区刷出的page存储的数据)位于Storage VPC中,这样和计算节点在物理层面隔离。一个主从实例,其物理存储需要位于同一个Region中,这样的存储称为EC2 VMs集群,其是由一个个使用了SSD的Storage Node组成。
1.2 核心技术与架构
Aurora提倡“the log is the database”,这是其设计的核心。围绕这个观点,传统数据库的组件架构,发生了一些变化。
对于Aurora,每一个存储节点,如图1-3,由两部分构成。
第一部分:Caching
第一部分是“Caching”,这是一个重要的关键点,可惜论文没有描述其细节。
如同传统数据库架构的数据缓冲区,向事务层提供数据。传统数据库架构的数据缓冲区,向上起着消耗存储IO的I加载数据到内存供计算层读写数据的作用、向下起着消耗IO的O写出脏数据到存储层以实现数据持久存储的作用。对于一个写密集的OLTP系统,大量随机写花费了很多时间,系统的性能因此经常表现为存储层的IO瓶颈。尽管checkpoint技术缓解了每个写操作刷出脏数据的冲动,尽管SSD的使用缓解了存储层的瓶颈,但是,毕竟存储层的I与O的时间消耗还是巨大的,尤其是对于随机写密集的OLTP系统。
Aurora的设计,消除了脏数据刷出的过程,数据缓冲区的作用,只是加载数据供上层使用,而脏数据不必从数据缓冲区刷出到物理存储上,这对于随机写密集的OLTP系统而言,是一个福音,性能的瓶颈点被去掉了一个(如图1-3,在“Caching”和“Logging+Storage”之间,竖线的箭头,应该是指向“Caching”的,以表示数据只是加载到Caching中,不存在脏数据的刷出操作)。
但是,观察图1-3,“Caching”是位于了存储层内还是计算层内?论文没有明示。
从图1-3观察,似乎“Caching”是存储层和计算层所共用的一个组件,那么就可能存在这样的一个两层设计:位于存储层和计算层各有一部分“Caching”,这两部分“Caching”组合成为一个逻辑上的“Caching”,而逻辑意义上的“Caching”似乎在AWS认为,其更像是属于计算层的。如下文引自论文原文:
Althougheach instance still includes most of the components of a traditional kernel(query processor, transactions, locking, buffercache, access methods and undo management) several functions (redologging, durable storage, crash recovery,and backup/restore) are off-loaded tothe storage service.
位于存储层内的“Caching”,更像是一个分布式的共享文件系统,为了提高性能也许是一个分布式内存型的共享文件系统,为主从架构的数据库提供高速读服务,此点妙处,论文没有点出,这里权做推测。存储层如果能为所有的主备节点提供一致的缓冲数据,则有更为积极的意义,可以对比参考的如Oracle的RAC。
而位于计算层内的“Caching”,是单个数据库实例读数据的场所,独立使用。
Aurora提供了一个“自动恢复”缓冲预热的功能,其官方宣称如下:
“自动恢复”缓存预热
当数据库在关闭后启动或在发生故障后重启时,Aurora 将对缓冲池缓存进行“预热”。即,Aurora 会用内存页面缓存中存储的已知常用查询页面预加载缓冲池。这样,缓冲池便无需从正常的数据库使用“预热”,从而提高性能。
Aurora 页面缓存将通过数据库中的单独过程进行管理,这将允许页面缓存独立于数据库进行“自动恢复”。在出现极少发生的数据库故障时,页面缓存将保留在内存中,这将确保在数据库重新启动时,使用最新状态预热缓冲池。
源自:
http://docs.amazonaws.cn/AmazonRDS/latest/UserGuide/Aurora.Overview.html
“在出现极少发生的数据库故障时,页面缓存将保留在内存中”,这句话很重要,一是其表明数据不用很耗时地重新加载了,二是数据库实例崩溃前的数据内存状态被保留着,三是数据库崩溃重启不必再执行“故障恢复”的过程即使用REDO日志重新回放以保障数据的一致性了(事务的ACID中的C特性)。
那么,页面缓冲是一直保留在哪个节点的内存中?是存储节点还是计算节点?如果是位于计算节点,那么备机节点发生数据库故障时,这样的机制不会对备机节点起到保护作用。如果是位于存储节点,则存储作为一个服务,服务了一主多备的多个节点,则能更好的发挥“自动恢复”缓冲预热的功效(存储节点的caching一直存在,向上层计算节点的caching提供数据批量加载服务,但也许不是这样,而是提供一个接口,能够向计算层的caching提供高速读数据的服务,论文没有更多的重要细节披露,权做推测)。由此看来,“Caching”层的两层设计,当是有价值的(价值点是“自动恢复”缓冲预热,由存储层提供此项服务),与预写日志功能从事务层剥离是关联的设计。
这就又回到前面引用的论文中的那段英文,其表明:Aurora的设计,把REDO日志、持久化存储、系统故障恢复、物理备份与物理恢复这些功能模块,归属到了存储层。由此就引出了Aurora的另外一个重要话题---存储层的设计(如下的第二部分和下一节内容)。
对于计算层的“Caching”,其实现将被大为简化。脏数据不再被写出,脏页面不再需要复杂的淘汰策略进行管理,消除了后台的写任务线程,同时也消除了checkpoint线程的工作,数据缓冲区的管理大为简化,即降低了系统的复杂度又减少了时间的消耗、还避免了因执行后台写等任务带来的性能抖动,解耦带来的功效确实宜人。Aurora额外需要做的一项新工作是:only pages with a long chain of modifications need to berematerialized。而计算层的“Caching”变成单向的读入,此时需要解决的,仅仅是什么样的数据可以(从存储层的Caching)被读入的问题,而论文原文描述:
Theguarantee is implemented by evicting a page from the cache only if its “pageLSN” (identifying the log record associated with the latest change to the page)is greater than or equal tothe VDL.
VDL是存储层的最小一致点(参见3.1节),标识了可用日志的最低范围,比VDL还老的数据页不再可用,所以显然如上的论文原文是错误的。如果有比当前数据页还新的数据页被从日志中恢复,则其LSN一定更大,所以页面换入的条件是:存储层Caching中存在页面的LSN值更大的;页面被换出的条件是:Caching中的页面的LSN小于等于VDL。而且,这一定是发生在备机需要更新其计算层的Caching时刻,而不是主机需要更新其计算层的Caching时刻。存在此种情况,其原因已经很明显,主机修改数据,形成脏页,这样的脏页(数据的后像)才能作为REDO日志的一部分被主机刷出;而主机不会刷出脏页,所以被修改后的数据页应该一直在内存中,而被修改过的数据页如果反复被修改,则意味着主机Caching中的相应脏页数据一定是最新的,没有必要从存储层的Caching中读入“绕道恢复后的数据页”。如果以上猜想不成立,除非Aurora生成REDO日志时,存于REDO日志中的数据页部分采取先复制然后其上的数据项被修改这样的方式。可是多做一次复制,又有何必要呢?
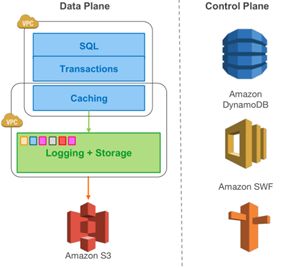
图1-3 存储结构图
另外,如果“Caching”确实存在两层(另外一个证据,参加图1-4[⑤]),而如2.1节所述,存储层也在处理日志、并依据日志生成页数据,则存储节点也存在处理数据的能力,就类似于Oracle的ExaData。这样导致的一个可能是,两层的“Caching”还是可能存在差别的。存储层的“Caching”能够帮助做谓词下推的工作,然后把较少的数据传回计算层的“Caching”,由此实现类似Oracle的ExaData的智能扫描(Smart Scan)的功能。是否如此,或者Aorora的体系结构和功能模块在未来继续演变的时候,是否会在存储层内的“Caching”做足文章,可以拭目以待。不过,目前制约存储层内的“Caching”起更大作用的因素,主要在于分布式事务的机制的选取和InnoDB自身的事务实现机制。详细讨论参见3.2节。
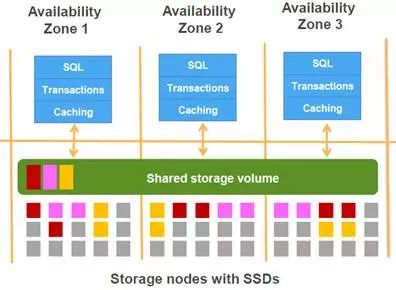
图1-4 存储层的“Shared storage column”与计算层的“Caching”构成的两层数据缓冲结构
第二部分:Logging+Storage
第二部分是“Logging+Storage”,日志和持久化存储。日志与传统数据库对于预写日志(WAL)的利用方式与MySQL不同,这点是Aurora实现计算与存储分离的核心(下一节详述存储层实现细节)。
如图1-5所示,对于日志数据,从Primary RW DB写出到一个存储节点,每个AZ至少有2份数据,写出的日志数据会自动复制到3个AZ中的6个存储节点,当其中的多数节点回应写日志成功,则向上层返回写成功的ACK。这表明写日志信息采用了多数派协议(quorum)。
MySQL的事务模型符合SS2PL协议[⑥],当日志成功写出,就可以在内存中标识事务提交成功[⑦],而写日志信息是一个批量的、有序的IO操作,再加上Aurora去除了大量的缓冲区脏数据的随机写操作,因此Aurora的整体性能得到大幅提升。
借用官方论文的一组对比数据,可以感性认识存储和计算分离的所带来的巨大好处,如图1-6所示,MySQL的每个事务的IO花费是Aurora的7.79倍,而事务处理量Aurora是MySQL的35倍,相差明显。
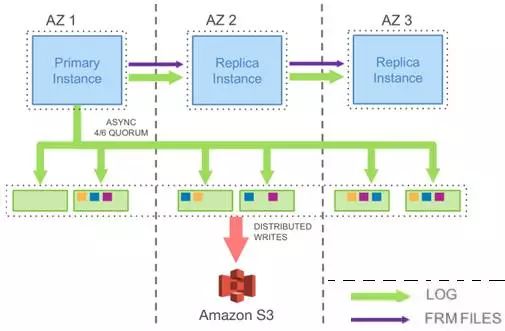
图1-5 主从复制日志存储图
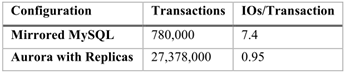
图1-6 Aurora与MySQL主从复制架构性能数据对比图
对于主备系统之间,如图1-5所示,主备之间有事务日志(LOG)和元数据(FRM FILES)的传递。也就是说备机的数据是源自主机的。如图1-5所示的主备之间的紫色箭头,表示主机向备机传输的是更新了的元数据,绿色箭头表示日志作为数据流被发送给了备机(这个复制,应该是异步的,相关内容请参考2.1节)。所以备机的数据更新,应该是应用了主机传输来的事务日志所致。这是论文中表述的内容,原文如下:
In this model,the primary only writes log records to the storage service and streams those logrecords as well as metadata updates to the replica instances.
但是,日志的应用功能是被放到了存储层实现的,如原文描述:
Instead,the log applicator is pushed to thestorage tier where it can be used to generate database pages inbackground or on demand.
而官方的网站[⑧]用图1-7描述了备机的数据,是从存储节点读入的。
鉴于以上几点,备机数据获取和更新的这个细节,算是个谜。
“Caching”如果确实分为两层,在存储层提供从日志中恢复成为数据页的形式而被缓冲,则主备系统之间应该没有必要再传输日志数据,对于备机而言,直接从统一的存储层的“Caching”中获取数据即可。
与此相关的一个问题是:为什么备机节点,可以多达15个呢?难道仅仅是应对读负载吗?或者,作为故障转移的目标,需要这么多备机做备选吗?这又是一个谜。
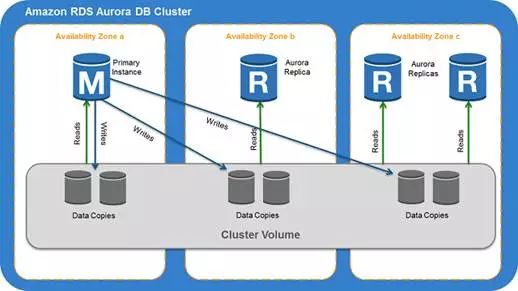
图1-7 Aurora主备机数据流图
1.3 其他组件
从图1-1中可以看到,物理备份和恢复的数据,是直接存储在Amazon S3,即Simple Storage Service上。物理备份和恢复的模块功能被从事务引擎中剥离到了存储层。
从图1-3和1-4中可以看到,日志信息的持久化存储,也是落在了S3上。
S3是AWS提供的对象存储服务。S3提供了高耐久性、高可扩展性以及安全的解决方案来备份和归档用户的关键数据。在云服务中,数据库提供商业逻辑的支撑,S3提供了数据的持久存储支撑。其作用不可小视。
另外,论文提及了heat management、OS and security patching 、software upgrades等特性,对于创造极高的云数据库服务能力很有帮助,本文不再展开讨论,请参阅论文和相关资料。
2 .Aurora的存储架构
存储层的设计和实现,体现了“the log is the database”,其含义是日志中包含了数据的信息,可以从日志中恢复出用户的数据,所以数据不一定必须再独立存储一份。而数据库的核心不仅是数据,保障数据的拥有ACID特性的事务和提供便捷查询的SQL语句、对以数据为基础提供商业的交易服务更是必不可缺失,所以更精确的说,“the log is the data”,日志就是数据也许更为合适。在笔者看来,数据库的价值不仅在数据,还在数据库的相关技术,尤其在现代巨量数据下、完备的数据库理论下,对以分布为要求的数据库架构提出新的工程实践挑战。Aurora就是走在这样的实践道路上的楷模。
2.1 存储层的工作
如图1-8所示,主机Primary RW DB写出的REDO日志(MySQL生成的日志带有LSN,Log Sequence Number,单调递增的日志顺序号)信息发送到六个Sotrage Node中的每一个Sotrage Node上的时候,只存在一个同步瓶颈点,就是图中标识为❶之处,这是Aurora的一个核心设计点,尽量最小化主节点写请求的延时。在存储节点,传输来的日志进入一个队列等待被处理。
之后日志被快速持久化到物理存储设备,并立刻给主机一个回应。这是标识为❷的处理过程,这个过程极其简单,没有额外的操作,因而速度会很快,这样能够满足如上所说的“尽量最小化主节点写请求的延时”的设计理念。❶和❷之后的其他操作,都是异步操作,不影响系统的整体性能。这样当主机Primary RW DB收到六个Sotrage Node中的四个节点的ACK后,就认为日志成功写出,可以继续其他工作了
❸所做的工作,是对持久化了日志做处理,如排序/分组等操作作用在日志上,以便找出日志数据中的间隙,存在间隙的原因是多数派写日志的机制下,少数派可能丢失日志从而导致日志不连贯。
❹所做的工作,就是从其他存储节点(6个存储节点构成一个PG ,即Protection Group,每个节点是一个segment,存储单位是10G,位于一个数据中心中。6个存储节点每2个位于一个AZ,共分布于3个AZ)中,通过Gossip协议,来拉取本节点丢失的日志数据,以填充满所❸发现的日志间隙。在❸和❹的过程中,能发现所有的副本中:相同的、连续的日志段是哪一部分,其中最大的LSN被称为VCL(Volume Complete LSN)。
❺所做的工作,就是从持久化的日志数据中,产生数据,就如同系统故障时使用REDO日志做恢复的过程:解析REDO日志,获取其中保存的数据页的修改后像,恢复到类似于传统数据库的数据缓冲区中(这也是存储层需要存在“Caching”的一个明证)。
之后,第六步,周期性地把修复后的日志数据和由日志生成的以页为单位的数据刷出到S3做为备份。第七步,周期性地收集垃圾版本(PGMRPL,即Protection Group Min Read Point LSN),参考表1-2[⑨],可以看到,垃圾收集,是以VDL为判断依据的,当日志的LSN小于VDL,则可以被作为垃圾回收;第八步,周期性地用CRC做数据校验。
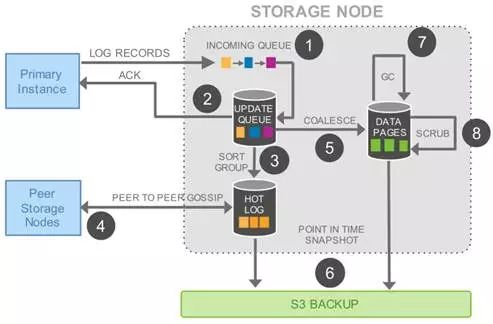
图1-8 日志数据在存储节点的处理过程图
2.2 储存层的设计讨论
现在再来反观Aurora的整体设计:
数据不再从数据缓冲区刷出,消除了随机写操作,减少了IO。
计算和存储分离,日志跨AZ写到多份存储节点,存在网络IO。
主备节点间传输日志和元数据,存在网络IO。
如上是三条核心点,似乎网络IO占了三分之二条,属于多数。但是网络IO都是批量数据顺序写,可极大地抵消很多次的随机写的网络IO消耗,而且通过数据冗余,极大地保障了可用性和云数据的弹性,从测试数据看,整体性能得到了可观的提升。因此这样的设计是一个优秀的架构设计。
数据冗余且有效,是使用数据库系统的基本要求。逻辑备份与还原、物理备份与恢复、主从复制、两地三中心等灾备技术方案等都是数据冗余的相关技术。数据库走向对等分布式架构,除了应对巨量数据的存储和计算的需要,也要靠数据冗余来保证数据的可用性。所以数据冗余是数据系统架构设计的一个必须考虑点。
Aurora自然也要实现数据冗余。如图1-5所示,数据至少在3个AZ中存6份。如果不采用“the log is the database”的理念,而使用传统数据库的技术,在跨节点写出多份数据时,势必需要采用2PC/3PC等多阶段的方式来保证提交数据的正确性,这样网络交互的次数就会很多,而且大量的随机写操作会在网络蔓延。所以“the log is the database”的理念客观上避免了传统的、耗时昂贵的分布式事务的处理机制,而又达到了数据分布的目的,这又是一个亮点。
数据至少在3个AZ中存6份,其目的是要保证数据库服务的持续可用。那么,什么算是可用呢?无论是数据中心内部的局部故障还是跨数据中心甚至跨AZ出现故障,AWS也要在某些情况下提供数据服务的可用。这就要分两种情况确定,这两种情况基于6个副本的前提[⑩](3个副本能满足多数派的读写规则,但是一旦其中一个副本不可用,则其余2个就不能保证读写一致,基于3个副本的分布式设计是脆弱的,不能切实可用地起到依靠数据冗余来换取数据可用的保障):
第1种: 读写均可用。
如图1-9,当一个AZ出现问题,即2个副本不可用,Aurora仍然能够保证读写可用,保障数据一致。设置V=6,读多数派为Vr = 3,写多数派为Vw = 4,所以一个AZ出现故障,或者3个AZ中的两个数据中心出现故障,Aurora依然能够向外提供服务。
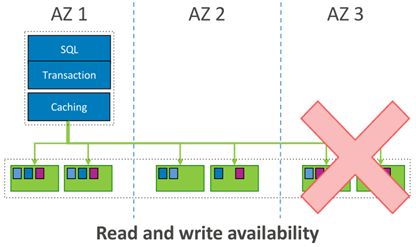
图1-9 Aurora保障读写可用图
第2种: 至少读可用。
当写服务不可用,至少还可以提供读服务。设置V=6,读多数派为Vr = 3,写多数派为Vw = 4时,一个AZ出现故障依旧能够提供读服务,如图1-10甚至跨不同AZ的3个数据中心出现故障(概率非常小),读服务依旧能够提供。
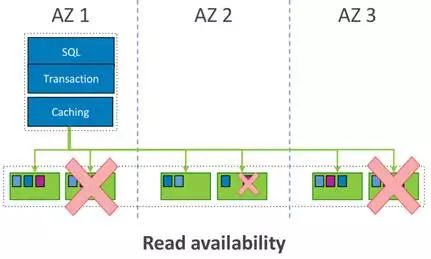
图1-10 Aurora保障读可用图
在1.1节,曾经说过“主从节点可以位于不同的AZ(最多位于3个VPC,需要3个AZ)但需要位于同一个Region内”。如表1-1所示,AWS在全球提供的AZ个数尚有限,按其自身的说法部署一个Aurora需要三个AZ,那么诸如只有2个AZ的Region如北京,尚不能得到较可靠的数据可用保障。
表1-1 至2017年6月AWS的Region和AZ部署表

2.3 Aurora设计的优点
首先,存储层与事务管理分离,即ACID的D特性独立,使得存储有机会成为独立的服务而存在,便于跨数据中心时实现数据的容错(fault-tolerant)、自愈(self-healing service)[11]和快速迁移。一旦存储层具备了容错、自愈和可快速迁移特性,则对外提供服务就不用再担心数据的短暂或长久的不可用性。在数据为王的时代,此举能保护好最核心的财产,确保云数据库服务能持续不断地对外提供服务,这使得Aurora具备了云服务的弹性。此点在AWS看来,十分重要。有了这种需求,推动技术架构发生变化便水到渠成。
服务的过程中,局部数据修复的能力,速度很快。数据库宕机后的恢复,速度也很快。
Once thedatabase starts up it performs volume recovery in collaboration with thestorage service and as a result, an Aurora database can recover very quickly (generally under 10 seconds) even ifit crashed while processing over 100,000write statements per second.
服务中断后,最后的招数就是数据迁移加数据库引擎重新部署,而AWS的整个云系统具备了快速迁移数据的能力,这使得以存储为核心的云数据库有了超强的持久服务能力。
Wemonitor and automatically repair faults as part of our service. A 10GB segment can be repaired in 10 seconds on a10Gbps network link. We would need to see two such failures in thesame 10 second window plus a failure of an AZ not containing either of thesetwo independent failures to lose quorum. At our observed failure rates, that’ssufficiently unlikely, even for the number of databases we manage for ourcustomers.
其次,存储层从高度耦合的数据库引擎中分离,降低了数据库引擎的复杂度,数据库组件的分离使得数据库部署适应巨量数据的分布式处理需求。这将进一步带动数据库引擎上层的语法分析、查询优化、SQL执行、事务处理等组件进一步的解耦。
笔者认为,这是Aurora用实践为数据库架构技术的发展指出的可行方向。一个具有实践意义的分布式发展架构,总是最亮眼的,也总是具有指导意义的。存储与计算解耦,各种组件互相解耦,不断解耦...在此种思路下,AWS已经走在发展万能数据库引擎的道路上(参见4.2节)。
3.Aurora的事务处理
Aurora基于MySQL和InnoDB,实现的是单点写的一主多从架构,所以在事务处理方面,没有大的变动,事务处理技术得到继承。整体上是依据SS2PL和MVCC技术实现了事务模型(参见《数据库事务处理的艺术 事务管理与并发控制》一书的10.3.3、10.3.4节)和并发控制(参见《数据库事务处理的艺术事务管理与并发控制》一书的第11、12章)。
3.1 持久性
对于Aurora,事务的ACID特性,只有D特性与MySQL和InnoDB有很大的不同。Aurora利用MySQL的Mini-transaction和LSN在存储节点构造数据页(基本过程参见2.1节)。
如前所述,Aurora的存储层与计算层分离。存储层其功能在2.1节讨论,其设计思想在2.2节讨论。本节从事务的角度来讨论与存储层紧密相关的持久性,如表1-2所示存储层是表中的“存储节点S1、S2、S3、S4、S5、S6”。
在存储层,日志被写到持久化的存储设备后,主节点收到应答则不被阻塞,上层工作能够继续进行,且存储层的日志落盘操作保证了整个Aorora的日志持久化。然后存储层的利用日志做实时恢复,这样使得日志数据转变为了“Caching”中存储的页面格式的数据。这些工作完成,才相当于传统架构的数据库持久化完成。
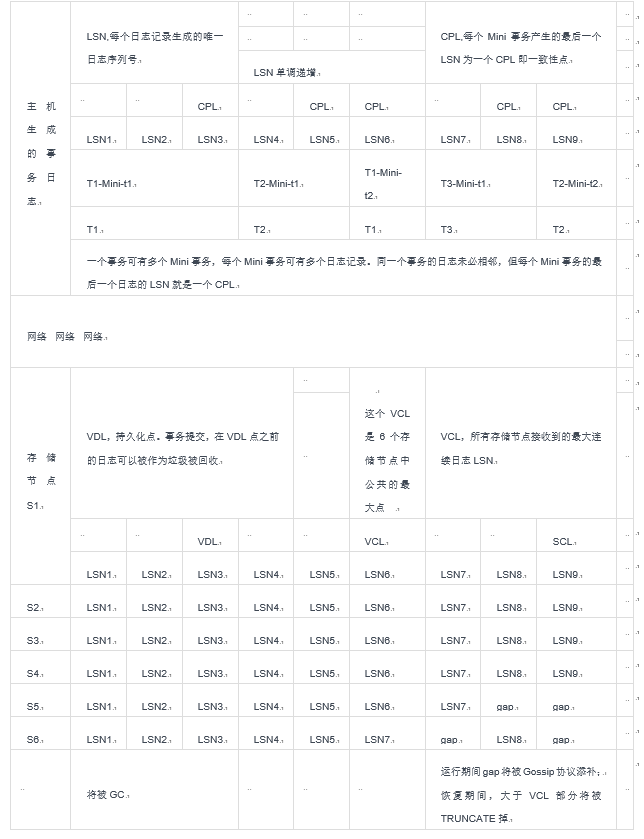
但是,因为存储层不再是单点而是分布式结构,故存在故障的种类变多,如多节点的数据在实时运行过程中的一致性问题、在系统故障后的数据恢复时多节点的数据一致性问题。Aurora使用如表1-2的几个概念来表示关键的一些日志点信息,然后凭借这些点来解决“日志数据的不一致”问题,这几个概念,分别是:
LSN, Log Sequence Number,日志序列号:单调递增,唯一标识每一条日志记录。如表1-2所示,LSN1到LSN9表示共有9条日志记录,每条有独立的LSN值。
CPL, Consistency Point LSN,一致性点:MySQL的每个Mini事务产生的最后一个LSN为一个CPL即一致性点(一个事务包括多个Mini事务,一个Mini事务包括一到多个日志记录。这是在描述以Mini事务为基本单位的一个局部一致,尚不能达到事务一致)。如表1-2所示,“T1-Mini-t1”T1事务的第一个Mini事务的一致性点,是LSN3,如果此时系统故障,之后做恢复,事务T1不会被恢复成功;如果事务T1在主节点被标识为了提交(InnoDB的事务提交标志,是在内存标识为事务已经提交,然后才刷出日志,这点不符合预写日志的要求),事务日志尚没有持久化到存储层,这意味着数据可能会丢失。但是,InnoDB对这种先标识事务提交后刷日志的方式给出了不丢失数据的解决方式,而Aurora改变了日志的刷出机制,可能会改变或不改变InnoDB原有的数据一致性保障机制[12],如果改变了原有机制,论文对这一个重要点没有加以描述,只能存疑待问。
SCL,Segment CompleteLSN,段完整LSN:每一个存储节点对应的最大连续LSN,在系统存活期间,可以利用SCN与其它节点交互,采用Gossip协议,填补丢失的日志记录。如表1-2所示,只标识出了S1节点的SCL是LSN9,而对于S5节点,其SCL是LSN7。
VCL,Volume Complete LSN,卷完整LSN:每个存储节点接收到的最大连续日志ID,因为多数派协议的使用,每个存储节点的VCL会不不同。如表1-2所示,没有表示出S1到S6各个存储节点的VCL,而是只标识出了六个节点中所有VCL中的公共最大点,这个点,是系统故障后恢复所能恢复到的一致点。注意依旧不是事务一致而是Mini事务一致,存疑的是,不能达到事务一致,其意义何在?还有什么重要的细节没有公开吗?留意到下面这段话,我们可以看出一点端倪(存储层的恢复不需要保证事务一致,存储层恢复之后,计算层还会继续恢复工作,这样才能达到事务一致):
However,upon restart, before the database is allowed to access the storage volume, the storage service does its own recovery whichis focused not on user-level transactions, but on making sure thatthe database sees a uniform view of storage despite its distributed nature.
VDL,Volumn Durable LSN,卷持久点:传统的数据库提供CheckPoint功能,在日志中加入一个CheckPoint点,作为故障恢复时的起始点。VDL就是存储层的“CheckPoint点”,在VDL之前的日志,已经无用可以被GC,但因存储层的日志一直在持续不断地被用于“恢复”日志为“Caching”中的数据页,所以其作用和原始的“CheckPoint点”相反。注意VDL是所有存储节点上的日志比较后得到的一个共同点,不是一个Segment级的点,这和VCL相似,都是PG(ProtectionGroup)级别的。其定义如下:
VDL or the Volume Durable LSN as thehighest CPL that is smaller than or equal to VCL and truncate all log recordswith LSN greater than the VDL.
表1-2 日志在主节点和存储层的作用表(持久化实现表)
3.2 事务与数据分布
在1.2节,我们曾说,目前制约存储层内的“Caching”起更大作用的因素,主要在于分布式事务的机制的选取和InnoDB自身的事务实现机制。
这有两层含义。一是InnoDB自身的事务实现机制制约了存储层内的“Caching”起更大作用。二是分布式事务的机制的选取关联着存储层内的“Caching”是否有机会起更大作用。
首先:InnoDB的事务信息,几乎不在数据上(除了元组头上有个事务ID用于版本可见性判断外再无其他信息),而是位于内存中。这其实是在说,InnoDB的行级锁即索引项的记录锁,其锁表位于内存,不能随着Aurora的数据分布而“分布”。而Oracle的RAC可是在数据页上存储了足够多的事务信息(参见《数据库事务处理的艺术事务管理与并发控制》一书的第六章),所以RAC中的其他节点,就能够随着被分布的数据而获取事务相关的信息从而在分布的各节点上处理事务的ACID特性。此点是MySQL能否走向分布式事务的一个关键点(当然选用不同的分布式事务实现机制会反过来影响这点结论)。
其次:分布式事务的机制的选取为什么会影响着Aurora的存储层内的“Caching”是否有机会起更大作用呢?
有的分布式事务架构,采取的是集中式架构,即中央点总控事务管理。事务的决策判断,都要经过中央点进行,多个子节点需要和中央节点多次交互。比如PostgreSQL-XC提供了全局事务管理器。如果MySQL/InnoDB或者Aurora的分布式架构向这个方向发展,则存储层内的“Caching”就没有多少机会起更大的作用了。
而有的分布式事务架构,采取的是事务信息随同存储分布。这样不同的节点就可以进行“分布式”的事务处理。比如基于BigTable的Percolator系统,其核心不在于两阶段提交,而是在于分布的数据项上,有着丰富的事务信息,这些信息足以被任何节点用于做ACID的实现判断(参考《Large-scale Incremental Processing Using Distributed Transactionsand Notifications》)。如果MySQL/InnoDB或者Aurora的分布式架构向这个方向发展,则存储层内的“Caching”就有很大的机会起更大的作用。
走向哪条路,或走向另外的路,需看Aurora的雄心有多大。目前的Aurora告诉我们的是,其分布式架构的选择,仅是用户数据分布。事务数据的分布,其实是更大的一个话题。
3.3 事务处理
MySQL和InnoDB的事务处理技术,采用了SS2PL,把强严格两阶段锁融合到平板事务模型中,以提交和回滚机制实现A特性,并进一步在读数据时加锁确保C特性,通过MVCC实现了I特性中的RR和RC隔离级别以提高并发度。这些技术,在目前的Aurora中没有大的改变。如前所述,Aurora改变的是依据事务日志做持久化处理(D特性)和系统故障后的恢复的一部分流程处理(A、C特性的一部分),从整体上看,没有革命性的变化。但是,Aurora的事务提交却是异步的且和VDL相关(确保持久化),这点在论文中描述很细致如下:
In Aurora, transaction commits arecompleted asynchronously. When a client commits a transaction, the threadhandling the commit request sets the transaction aside by recording its “commit LSN” as part of aseparate list of transactions waiting on commit and moves on to performother work. The equivalent to the WAL protocol is based on completing a commit,if and only if, the latest VDL is greater than or equal to the transaction’scommit LSN. As the VDL advances, the database identifies qualifyingtransactions that are waiting to be committed and uses a dedicated thread tosend commit acknowledgements to waiting clients. Worker threads do not pausefor commits, they simply pull other pending requests and continueprocessing.
在1.2节我们提到“鉴于以上几点,备机数据获取和更新的这个细节,算是个谜”,即备机的数据获取,是从存储层而来还是从主节点而来?我们不妨做个论文没有提及的猜想:备机的数据,源自存储层和主节点,存储层统一向上层提供数据页的缓冲服务,用以不断响应计算层的数据缺页请求,这起到了传统的数据缓冲区的作用。而主节点传输日志给备节点,备节点可以从中解析出UNDO日志信息(UNDO也是受到REDO的保护的),从而能够构造出主节点在某个时刻的完整的计算环境状态(数据缓冲区+UNDO信息),这样,备机就可以为接到的读请求构造一致的“ReadView”,为读操作提供了事务读数据的一致性状态。如为此点,则是一个巧妙的设计。更进一步,主机直接传输给备机的,可以只是准备写入REDO的UNDO信息。
3.4 锁管理
基于MySQL的Aurora同样使用了基于封锁的并发访问控制技术。但是,Aurora改造了MySQL的锁管理器,这点论文没有提及,而在2017年的Percona技术大会上,Aurora的一个分享展示了如图1-11的内容。图中显示,在MySQL的锁表管理器上,对于Scan、Delete、Insert三种操作,把lock互斥了三种类型的并发,而Aurora分别按操作类型加锁“lock manager”,提高了并发度,这样的锁,看起来是一个系统锁,把一个粗粒度的系统锁拆分为三个细粒度的系统锁。但是,较为奇怪的是,如图1-12,Aurora展示了其效果却十分的惊人(图1-13是测试环境的配置)。
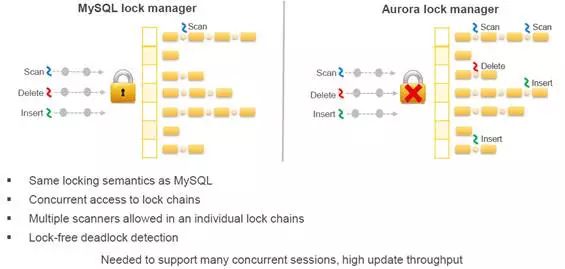
图1-11 Aurora锁管理器改进图
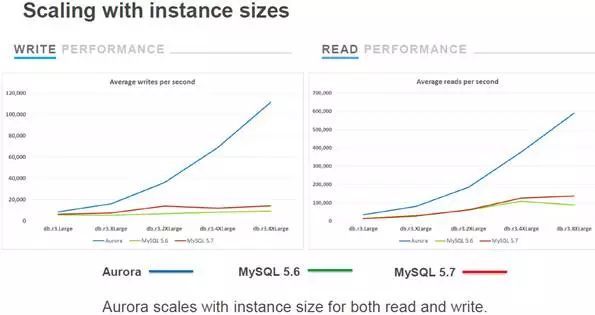
图1-12 Aurora锁管理器改进后的性能测试对比图
图1-13 测试环境配置图[13]
4 .云服务能力
4.1 强化的云服务能力
除了通过更多的数据冗余(跨3个AZ的 6个副本)提高高可用性外,Aurora还有着其他强大的云服务能力,这是云数据库需要重点建设的能力。
存储方面,存储的单位是段(segment),每个段的大小为10G,单实例数据库存储最大限是64 TB。
处理系统故障方面:
10秒内完成一个 10G的Segment的网络迁移。30秒完成故障转移。
以Segment为单位周期性并行备份。
以REDO日志为单位周期性并行备份。
通过日志实时地持续恢复,提供了更快的crashrecovery。
性能方面:
更快的索引构建。采用自底向上的索引构建方式,比MySQL快2倍到4倍。
无锁并发Read-View算法。构造ReadView采用无锁算法减少竞争提高性能。
无锁队列提高审计功能的速度。
其他如热行竞争、批量数据插入等性能提升明显。
其他云服务:
提供快速 provisioning 和部署。
自动安装补丁和软件升级。
备份和 point-in-time 恢复。
计算和存储的扩展性支持。
如图1-3所示,存储系统的元数据存于Amazon DynamoDB中,使用Amazon SWF提供的工作流实现对Aurora的自动化管理,这也是云中规模化服务的重要能力。
万能数据库
AWS的Aurora不只是MySQL的一个分支版本,更像是一个万能的数据库系统,这样的系统,通过兼容各种主流数据库的SQL语法、功能,也许能在云上一统数据库的服务,把各种数据库的用户应用接入,通过统一的一个分布式的数据库引擎,提供各种数据库的数据服务能力。
AWS的官网,声明了“兼容 PostgreSQL的Amazon Aurora”如下:
AmazonRelational Database Service (Amazon RDS) 正在提供 Aurora(PostgreSQL) 预览版,即兼容 PostgreSQL 的 Amazon Aurora。Aurora 是一种完全托管的、兼容 PostgreSQL 和 MySQL 的关系数据库引擎。
单从字面看,Aurora不再是MySQL,而是MySQL+PostgreSQL,所以将来将会是 “MySQL+PostgreSQL+...+...”,各种数据库都将融于Aurora当中。这样提供强大无比的云数据库服务,此点非常重要,用户基于任何数据库的应用均不用修改应用的代码,无缝接入Aurora。
从技术的层面看,实现这样的目标,有多种方式。简单的方式,就是利用相同的云基础设施和云服务概念,把各个数据库单独云化,然后用Aurora统一命名。但如果进一步把计算层分离,如把语法解析、查询器、执行器拆分,不同种类的数据库使用各自的语法解析和查询优化,然后统一执行计划交给统一的执行器去执行,事务处理和数据存储则可以独自研发独立于上层的计算。如此,想象空间得以打开......
5. 小结
本文探讨了Aurora的实现方面的技术内容,由于作者水平有限,错漏之处,请不吝指正。Aurora在实现方面的诸多细节,论文并没有提及,期待以此文抛砖引玉,期待多方指点讨论,共同进步。
附录
参考资料:
1. 《Amazon Aurora: Design Considerations for High Throughput CloudNative Relational Databases》
2. https://aws.amazon.com/
3. 《数据库事务处理的艺术事务管理与并发控制》,机械工业出版社,2017年10月出版
4. Aurora deep dive - Percona Live 2017
5. https://aws.amazon.com/tw/blogs/database/category/aurora/?nc1=h_l
6. 《High performance transactions in deuteronomy》
转载声明:文章为2017年7月《程序员》原创,本公众号已获转载授权。
