一文看明白什么是AI芯片:架构、分类及关键技术!

人工智能芯片目前有两种发展路径:一种是延续传统计算架构,加速硬件计算能力,主要以 3 种类型的芯片为代表,即 GPU、 FPGA、 ASIC,但CPU依旧发挥着不可替代的作用;另一种是颠覆经典的冯·诺依曼计算架构,采用类脑神经结构来提升计算能力,以IBM TrueNorth 芯片为代表。
传统 CPU
计算机工业从1960年代早期开始使用CPU这个术语。迄今为止,CPU从形态、设计到实现都已发生了巨大的变化,但是其基本工作原理却一直没有大的改变。 通常 CPU 由控制器和运算器这两个主要部件组成。 传统的 CPU 内部结构图如图所示:

传统CPU内部结构图(ALU计算模块)
从图中我们可以看到:实质上仅单独的ALU模块(逻辑运算单元)是用来完成数据计算的,其他各个模块的存在都是为了保证指令能够一条接一条的有序执行。这种通用性结构对于传统的编程计算模式非常适合,同时可以通过提升CPU主频(提升单位时间内执行指令的条数)来提升计算速度。 但对于深度学习中的并不需要太多的程序指令、 却需要海量数据运算的计算需求, 这种结构就显得有些力不从心。尤其是在功耗限制下, 无法通过无限制的提升 CPU 和内存的工作频率来加快指令执行速度, 这种情况导致 CPU 系统的发展遇到不可逾越的瓶颈。
并行加速计算的GPU
GPU 作为最早从事并行加速计算的处理器,相比 CPU 速度快, 同时比其他加速器芯片编程灵活简单。
传统的 CPU 之所以不适合人工智能算法的执行,主要原因在于其计算指令遵循串行执行的方式,没能发挥出芯片的全部潜力。与之不同的是, GPU 具有高并行结构,在处理图形数据和复杂算法方面拥有比 CPU 更高的效率。对比 GPU 和 CPU 在结构上的差异, CPU大部分面积为控制器和寄存器,而 GPU 拥有更ALU(逻辑运算单元)用于数据处理,这样的结构适合对密集型数据进行并行处理, CPU 与 GPU 的结构对比如图 所示。
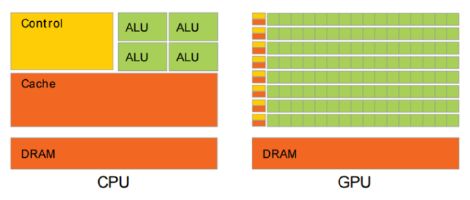
CPU及GPU结构对比图
程序在 GPU系统上的运行速度相较于单核 CPU往往提升几十倍乃至上千倍。随着英伟达、 AMD 等公司不断推进其对 GPU 大规模并行架构的支持,面向通用计算的 GPU(即GPGPU,通用计算图形处理器)已成为加速可并行应用程序的重要手段,GPU 的发展历程可分为 3 个阶段:
第一代GPU(1999年以前),部分功能从CPU分离 , 实现硬件加速 , 以GE(GEOMETRY ENGINE)为代表,只能起到 3D 图像处理的加速作用,不具有软件编程特性。
第二代 GPU(1999-2005 年), 实现进一步的硬件加速和有限的编程性。 1999年,英伟达发布了“专为执行复杂的数学和几何计算的” GeForce256 图像处理芯片,将更多的晶体管用作执行单元, 而不是像 CPU 那样用作复杂的控制单元和缓存,将(TRANSFORM AND LIGHTING) 等功能从 CPU 分离出来,实现了快速变换,这成为 GPU 真正出现的标志。之后几年, GPU 技术快速发展,运算速度迅速超过 CPU。 2001年英伟达和ATI 分别推出的GEFORCE3和RADEON 8500,图形硬件的流水线被定义为流处理器,出现了顶点级可编程性,同时像素级也具有有限的编程性,但 GPU 的整体编程性仍然比较有限。
第三代 GPU(2006年以后), GPU实现方便的编程环境创建, 可以直接编写程序。 2006年英伟达与ATI分别推出了CUDA (Compute United Device Architecture,计算统一设备架构)编程环境和CTM(CLOSE TO THE METAL)编程环境, 使得 GPU 打破图形语言的局限成为真正的并行数据处理超级加速器。
2008年,苹果公司提出一个通用的并行计算编程平台 OPENCL(开放运算语言),与CUDA绑定在英伟达的显卡上不同,OPENCL 和具体的计算设备无关。
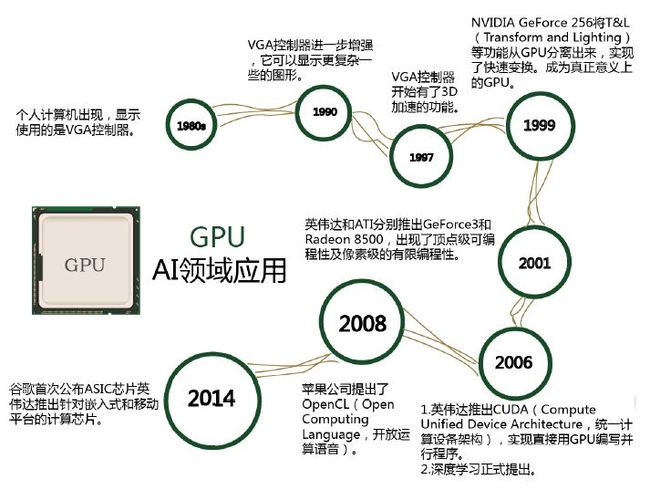
GPU芯片的发展阶段
目前, GPU 已经发展到较为成熟的阶段。谷歌、 FACEBOOK、微软、 Twtter和百度等公司都在使用GPU 分析图片、视频和音频文件,以改进搜索和图像标签等应用功能。此外,很多汽车生产商也在使用GPU芯片发展无人驾驶。 不仅如此, GPU也被应用于VR/AR 相关的产业。
但是 GPU也有一定的局限性。 深度学习算法分为训练和推断两部分, GPU 平台在算法训练上非常高效。但在推断中对于单项输入进行处理的时候,并行计算的优势不能完全发挥出来。
半定制化的FPGA
FPGA 是在 PAL、 GAL、 CPLD 等可编程器件基础上进一步发展的产物。用户可以通过烧入 FPGA 配置文件来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,比如用户可以把 FPGA 配置成一个微控制器 MCU,使用完毕后可以编辑配置文件把同一个FPGA 配置成一个音频编解码器。因此, 它既解决了定制电路灵活性的不足,又克服了原有可编程器件门电路数有限的缺点。
FPGA可同时进行数据并行和任务并行计算,在处理特定应用时有更加明显的效率提升。对于某个特定运算,通用 CPU可能需要多个时钟周期,而 FPGA 可以通过编程重组电路,直接生成专用电路,仅消耗少量甚至一次时钟周期就可完成运算。
此外,由于 FPGA的灵活性,很多使用通用处理器或 ASIC难以实现的底层硬件控制操作技术, 利用 FPGA 可以很方便的实现。这个特性为算法的功能实现和优化留出了更大空间。同时FPGA 一次性成本(光刻掩模制作成本)远低于ASIC,在芯片需求还未成规模、深度学习算法暂未稳定, 需要不断迭代改进的情况下,利用 FPGA 芯片具备可重构的特性来实现半定制的人工智能芯片是最佳选择之一。
功耗方面,从体系结构而言, FPGA 也具有天生的优势。传统的冯氏结构中,执行单元(如 CPU 核)执行任意指令,都需要有指令存储器、译码器、各种指令的运算器及分支跳转处理逻辑参与运行, 而FPGA每个逻辑单元的功能在重编程(即烧入)时就已经确定,不需要指令,无需共享内存,从而可以极大的降低单位执行的功耗,提高整体的能耗比。
由于 FPGA 具备灵活快速的特点, 因此在众多领域都有替代ASIC 的趋势。 FPGA 在人工智能领域的应用如图所示。
FPGA 在人工智能领域的应用
全定制化的ASIC
目前以深度学习为代表的人工智能计算需求,主要采用GPU、FPGA等已有的适合并行计算的通用芯片来实现加速。在产业应用没有大规模兴起之时,使用这类已有的通用芯片可以避免专门研发定制芯片(ASIC)的高投入和高风险。但是,由于这类通用芯片设计初衷并非专门针对深度学习,因而天然存在性能、 功耗等方面的局限性。随着人工智能应用规模的扩大,这类问题日益突显。
GPU作为图像处理器, 设计初衷是为了应对图像处理中的大规模并行计算。因此,在应用于深度学习算法时,有三个方面的局限性:
第一:应用过程中无法充分发挥并行计算优势。 深度学习包含训练和推断两个计算环节, GPU 在深度学习算法训练上非常高效, 但对于单一输入进行推断的场合, 并行度的优势不能完全发挥。
第二:无法灵活配置硬件结构。 GPU 采用 SIMT 计算模式, 硬件结构相对固定。 目前深度学习算法还未完全稳定,若深度学习算法发生大的变化, GPU 无法像 FPGA 一样可以灵活的配制硬件结构。
第三:运行深度学习算法能效低于FPGA。
尽管 FPGA 倍受看好,甚至新一代百度大脑也是基于 FPGA 平台研发,但其毕竟不是专门为了适用深度学习算法而研发,实际应用中也存在诸多局限:
第一:基本单元的计算能力有限。为了实现可重构特性, FPGA 内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠 LUT 查找表)都远远低于 CPU 和 GPU 中的 ALU 模块。
第二:计算资源占比相对较低。 为实现可重构特性, FPGA 内部大量资源被用于可配置的片上路由与连线。
第三:速度和功耗相对专用定制芯片(ASIC)仍然存在不小差距。
第四,:FPGA 价格较为昂贵。在规模放量的情况下单块 FPGA 的成本要远高于专用定制芯片。
因此,随着人工智能算法和应用技术的日益发展,以及人工智能专用芯片 ASIC产业环境的逐渐成熟, 全定制化人工智能 ASIC也逐步体现出自身的优势,从事此类芯片研发与应用的国内外比较有代表性的公司如图所示。
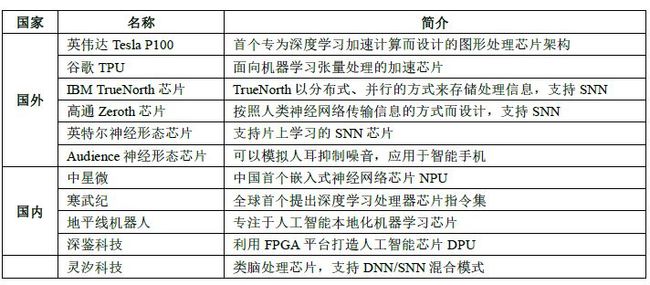
人工智能专用芯片研发情况一览
深度学习算法稳定后, AI 芯片可采用ASIC设计方法进行全定制, 使性能、功耗和面积等指标面向深度学习算法做到最优。
类脑芯片
类脑芯片不采用经典的冯·诺依曼架构, 而是基于神经形态架构设计,以IBM Truenorth为代表。 IBM 研究人员将存储单元作为突触、计算单元作为神经元、传输单元作为轴突搭建了神经芯片的原型。
目前, Truenorth用三星 28nm功耗工艺技术,由 54亿个晶体管组成的芯片构成的片上网络有4096个神经突触核心,实时作业功耗仅为70mW。由于神经突触要求权重可变且要有记忆功能, IBM采用与CMOS工艺兼容的相变非易失存储器(PCM)的技术实验性的实现了新型突触,加快了商业化进程。
来源:清华2018人工智能芯片研究报告
![]()
1.hi,嵌入式工程师们,据说2019年会是Linux年!
2.你眼里的嵌入式工程师应该是啥样的?
3.MIPS CPU架构宣布开源,RISC-V使命完成了?
4.MCU选8位还是32位?这可不是扔钢镚的事!
5.让自己更值钱,电子工程师可以这么做!
6.不是嵌入式坑了你,而是你坑了嵌入式

免责声明:本文系网络转载,版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将根据您提供的版权证明材料确认版权并支付稿酬或者删除内容。