文本特征提取
在自然语言处理中我们把文本数据变成向量数据,在向量数据中我们可以得到很多来自于文本数据当中的语言特性,这种方式叫做文本表示或文本特征构造。
文本特征的通用信息源
文本分类问题当中的对象
- 词:在英文文本处理当中面对的是单个词组用空格隔开容易区分,在中文文本当中需要通过特定的词库如python中的jieba、中科院、清华、哈工大的一些分词工具来进行分词处理。在处理词类时一般关注词性、词与上下文之间是否有强联系之类的问题。
- 文本:一般需要判断一段话当中他的情感状况、它是正面或反面、中立之类的问题或者如判断邮件是否为垃圾邮件之类的,或者会给出一个词或文本判断两个文本的相似性
如何构建NLP特征
直接可观测特征
单独词特征:如果观测独立与上下文的词语时一般关注它的时态(ed、ing)前缀(un、字母大写),如何找到他的词元、关注他在文本中出现的次数。
文本特征:主要考虑一个句子、一个段落或一篇文本时,观察到的特征是词在文本中的数量和次序。
文本表示
文本表示,简单的说就是不将文本视为字符串,而视为在数学上处理起来更为方便的向量。而怎么把字符串变为向量,就是文本表示的核心问题。
文本表示的好处是什么?
- 根本原因是计算机不方便直接对文本字符串进行处理,因此需要进行数值化或者向量化。
- 便于机器学习。
- 不仅传统的机器学习算法需要这个过程,深度学习也需要这个过程。良好的文本表示形式可以极大的提升算法效果。
文本表示分为哪几种呢?(基于类型)
- 长文本表示
- 短文本表示(句子)
- 词表示
文本表示分类(基于表示方法)
离散表示
One-hot表示Multi-hot表示
分布式表示
- 基于矩阵
- 基于降维表示
- 基于聚类表示
基于神经网络 - CBOW
- Skip-gram
- NNLM
- C&W
文本离散表示:词袋模型与TF-IDF
词袋子模型(bag of words)
词袋子模型是一种非常经典的文本表示。顾名思义,它就是将字符串视为一个 “装满字符(词)的袋子” ,袋子里的 词语是随便摆放的。而两个词袋子的相似程度就以它们重合的词及其相关分布进行判断。
举个例子,对于句子:“我们这些傻傻的路痴走啊走,好不容易找到了饭店的西门”。
我们先进行分词,将所有出现的词储存为一个词表。然后依据 “词语是否出现在词表中” 可以将这句话变为这样的向量:
[1,0,1,1,1,0,0,1,…]
词表:[我们,你们,走,西门,的,吃饭,旅游,找到了,…]
其中向量的每个维度唯一对应着词表中的一个词。可见这个向量的大部分位置是0值,这种情况叫作“稀疏”。为了减少存储空间,我们也可以只储存非零值的位置。
词袋子模型的优缺点
优点
- 简单,方便,快速
- 在语料充足的前提下,对于简单的自然语言处理任务效果不错。如文本分类。
缺点
- 其准确率往往比较低。凡是出现在文本中的词一视同仁,不能体现不同词在一句话中的不同的重要性。
- 无法关注词语之间的顺序关系,这是词袋子模型最大的缺点。如“武松打老虎”跟“老虎打武松”在词袋子模型中是认为一样的。
对词袋子模型的改进:TF-IDF
基于 TF-IDF 算法的关键词抽取
1.什么是TF-IDF呢?
TF(Term Frequency)词频
IDF(Inverse Document Frequency)逆文档频率,表示一个词的大小与常见词的反比
假如我们需要通过计算机来找到文本的关键词如何查找呢,一般是统计出现最高词语的频率也就是TF词频。但是在统计词语的过程中通常会遇到如下问题—最高出现的词汇可能是”停用词”,如”的”,”是”,”在”,在文本当中有的词的重要性是不同的,假如我们统计词频发现这五个词的频率最高,如”中国”、”土地”、”房子”、”蜜蜂”、”养殖”,其中中国、土地这些词汇经常出现而蜜蜂、养殖等词语不常出现。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
所以我们需要对文本词语进行一个权重处理,给蜜蜂、养殖等词语高权重,而”是”、”在”、”的”、”中国”等词语低权重等方法来处理文本。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
2.如何进行TF-IDF算法?
第一步,计算词频。
TF=某词在文章中出现的次数,考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
TF = 某词在文章中出现的次数/文章的总次数
第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
逆文档频率(IDF)=log(语料库的文档总数/包含该词的文档数+1)
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。
TF-IDF=TF*IDF
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
基于TextRank算法关键词提取
简单介绍PageRank
PageRank是google搜索引擎进行网页排名的算法,是用来计算网页重要性的,它将每一个网页看作一个节点,将网页之间的链接看作是节点之间的有向边,网页的重要性取决于链接到它的网页数量以及这些网页的重要性。其中它主要根据两点来进行网页排名1.指向该A网页的其他网页数量2.指向该A网页的其他网页质量
它的计算公式为:

其中PR(A)指的是网页(A)的排名,Ti是存在到A的链接的网页。C(Ti)是网页Ti中存在的链接的数量。d是阻尼系数,一般定义为用户随机点击链接的概率,根据工程经验一般取0.85。而(1-d)代表着不考虑入站链接的情况下随机进入一个页面的概率。
d阻尼系数:现实网络中,由于存在出链度数为0,即不链接到任何网页的页面,但是很多网页可以访问它。鉴于这类情况,PageRank公式需要进行修正,修正的方法是,在简单公式的基础上增加阻尼系数。
TextRank原理
TextRank与PageRank相同,不过TextRank是以词为节点,建立起连接关系,而且TextRank当中是无向图而PageRank当中是有向图。
在TextRank当中建立了共现关系,其主要思路是设置一个滑动窗口,其中默认大小为5,也就是最多出现5个词然后给五个词进行窗口滑动建立起无向图的关系连接。
基于TextRank提取关键词的主要步骤:
(1)把给定的文本T按照完整句子进行分割;
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词等。这些词形成候选关键词;
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现;
(4)根据PageRank原理中的衡量重要性的公式,初始化各节点的权重,然后迭代计算各节点的权重,直至收敛;
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词;
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
词向量的one-hot表示
假设我们的词库总共有n个词,那我们开一个1*n的高维向量,而每个词都会在某个索引index下取到1,其余位置全部都取值为0.词向量在这种类型的编码中如下图所示:

这种方式非常简单但是并没有解决词组之间的相关性问题。因此我们需要尝试将词向量的维度降低一些,在一个子空间内可能将词组关联性体现出来。
基于SVD降维的表示方法
这是一种构造词嵌入(即词向量)的方法,步骤如下:
1.遍历所有的文本数据集,统计词出现的次数
2.用一个矩阵X来表示所有的次数情况
3.对X进行奇异值分解得到一个的分解
4.用U的行(rows)作为所有词表中词的词向量
有两种方法来构造矩阵X
方法一:词-文档矩阵
最初的想法是,我们猜测相互关联的词组同时出现在相同的文件中的概率很高。例如,“银行”、“债券”、“股票”、“钱”等都可能出现在一起。但是,“银行”、“章鱼”、“香蕉”和“曲棍球”可能不会一直一起出现。基于这个想法,我们建立一个词组文档矩阵X,具体是这么做的:遍历海量的文件,每次词组i出现在文件j中时,将Xij的值加1。不过大家可想而知,这会是个很大的矩阵,而且矩阵大小还和文档个数M有关系。
方法二:基于窗口的共现矩阵X
我们还是用一样的逻辑,不过换一种统计方式,把矩阵X记录的词频变成一个相关性矩阵。我们先规定一个固定大小的窗口,然后统计每个词出现在窗口中次数,这个计数是针对整个语料集做的。可能说得有点含糊,咱们一起来看个例子,假定我们有如下的3个句子,同时我们的窗口大小设定为1(把原始的句子分拆成一个一个的词):
1.I enjoy flying.
2.I like NLP.
3.I like deep learning. 由此产生的计数矩阵如下:
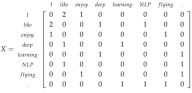
然后我们对X做奇异值分解,观察观察奇异值(矩阵的对角元素),并根据我们期待保留的百分比来进行截断(只保留前k个维度):
![]()
然后我们把子矩阵1:||,1:U1:|V|,1:k视作我们的词嵌入矩阵。也就是说,对于词表中的每一个词,我们都用一个k维的向量来表达了。
对X采用奇异值分解
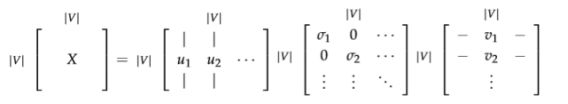
通过选择前K个奇异向量来进行降维:

这两种方法都能产生词向量,它们能够充分地编码语义和句法的信息,但同时也带来了其他的问题:
- 矩阵的维度会经常变化(新的词语经常会增加,语料库的大小也会随时变化)。
- 矩阵是非常稀疏的,因为大多数词并不同时出现。
- 矩阵的维度通常非常高(≈106×106) 训练需要O(n2)的复杂度(比如SVD)
- 需要专门对矩阵X进行特殊处理,以应对词组频率的极度不平衡的状况
当然,有一些办法可以缓解一下上述提到的问题:
- 忽视诸如“he”、“the” 、“has”等功能词。
- 应用“倾斜窗口”(ramp window),即:根据文件中词组之间的距离给它们的共现次数增加相应的权重。
- 使用皮尔森的相关性(Pearson correlation),将0记为负数,而不是它原来的数值。
基于神经网络的表示方法(当前流行方法)
基于神经网络的方法是创建一个模型,他能够一步步迭代地进行学习,最终得出每个单词基于其上下文的条件概率。
我们想建立一个概率模型,它包含已知和未知参数。每增加一个训练样本,它就能从模型的输入、输出和期望输出(标签),多学到一点点未知参数的信息。在每次迭代过程中,这个模型都能够评估其误差,并按照一定的更新规则,惩罚那些导致误差的参数。
两种应用场景
1.CBOW—基于上下文预测词语
我们知道一些上下文的单词如{“my”,”is”,”dulp”}我要预测中间的单词{“name”}这种模型叫做连续词袋子模型(CBOW).
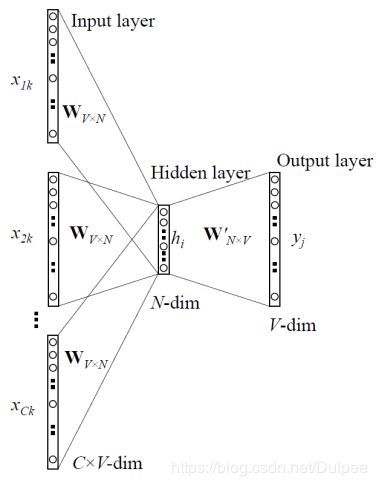
1.它们就是将句子表示为一些one-hot向量,作为模型的输入,咱们记为x©,模型的输出记为y©吧。因为连续词袋模型只有一个输出,所以其实我们只需记录它为y。y是已经知道并且有标签的中心词。
2.下一步定义模型中其他未知参数,建立两矩阵,和 。其中的n是可以任意指定的,它用来定义我们“嵌入空间”的维度。V是输入词矩阵。当词语wi(译注:wi是只有第i维是1其他维是0的one-hot向量)作为模型的一个输入的时候,V的第i列就是它的n维“嵌入向量”(embedded vector)。我们将V的这一列表示为vi。类似的,U是输出矩阵。当wj作为模型输出的时候,U的第j行就是它的n维“嵌入向量”。我们将U的这一行表示为uj。要注意我们实际上对于每个词语wi学习了两个向量。(作为输入词的向量vi,和作为输出词的向量uj)。
连续词袋模型(CBOW)中的各个记号:
wi:单词表V中的第i个单词
![]() :输入词矩阵
:输入词矩阵
vi:V的第i列,单词wi的输入向量
![]() :输出词矩阵
:输出词矩阵
ui:U的第i行,单词wi的输出向量
CBOW计算步骤:
1.对于m个词长度的输入上下文,我们产生它们的one-hot向量
![]()
2.我们得到上下文的嵌入词向量
![]()
3.将这些向量取平均
![]()
4.产生一个得分向量
![]()
5.将得分向量转换成概率分布形式
![]()
6.我们希望我们产生的概率分布 ,与真实概率分布Y相匹配。而y刚好也就是我们期望的真实词语的one-hot向量。
用一幅图来表示就是下面这个样子:
通过上面说的种种步骤,我们知道有了矩阵U、V整个过程是如何运作的,那我们怎样找到U和V呢?——我们需要有一个目标函数。通常来说,当我们试图从已知概率学习一个新的概率时,最常见的是从信息论的角度寻找方法来评估两个概率分布的差距。也就是使用交叉熵
![]()
结合我们当下的例子,y只是一个one-hot向量,于是上面的损失函数就可以简化为:
![]()
于是我们最终的优化函数为:
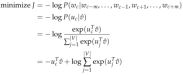
之后用SGD去更新每一个相关的词向量uc和vj 。
2.skip-gram—基于词语预测上下文
Skip-gram是CBOW的逆向过程,我们把”name”当成中心词将预测它周围的词语“my”,”is”,”dulp”。这个模型的建立与连续词袋模型(CBOW)非常相似,但本质上是交换了输入和输出的位置。我们令输入的one-hot向量(中心词)为x(因为它只有一个),输出向量为y(j)。U和V的定义与连续词袋模型一样。
它的具体过程为:
1.生成one-hot输入向量x。
2.得到上下文的嵌入词向量Vc=Vx。
3.因为这里不需要取平均值的操作,所以直接是v=Vc。
4.通过u=UVc产生2m个得分向量
5.将得分向量转换成概率分布形式y=softmax(u)。
6.我们希望我们产生的概率分布与真实概率分布 相匹配,也就是我们真实输出结果的one-hot向量。

像连续词袋模型一样,我们需要为模型设定一个目标/损失函数。不过不同的地方是我们这里需要引入朴素贝叶斯假设来将联合概率拆分成独立概率相乘。如果你之前不了解它,可以先跳过。这是一个非常强的条件独立性假设。也就是说只要给出了中心词,所有的输出词是完全独立的。

中文文本向量化
第一步导入包
import sys,codecs
import pandas as pd
import numpy as np
import jieba.posseg
import jieba.analyse
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer#构建tfidf权重计算
from sklearn.feature_extraction.text import CountVectorizer#构建词频矩阵
# 数据预处理操作:分词,词性筛选
def dataPrepos(text):
l = []
pos = ['n','nz','v','vd','vn','l','a','d']#定义选取的词性
seg = jieba.posseg.cut(text)
for i in seg:
if i.word and i.flag in pos:
l.append(i.word)
return l
# tf-idf获取文本top10关键词
def getKeywords_tfidf(data,topK):
idList, titleList, abstractList = data['id'], data['title'], data['abstract']
corpus = [] # 将所有文档输出到一个list中,一行就是一个文档
for index in range(len(idList)):
text = '%s。%s' % (titleList[index], abstractList[index]) # 拼接标题和摘要
text = dataPrepos(text) # 文本预处理
text = " ".join(text) # 连接成字符串,空格分隔
corpus.append(text)
# tf-idf获取文本top10关键词
def getKeywords_tfidf(data,topK):
idList, titleList, abstractList = data['id'], data['title'], data['abstract']
corpus = [] # 将所有文档输出到一个list中,一行就是一个文档
for index in range(len(idList)):
text = '%s。%s' % (titleList[index], abstractList[index]) # 拼接标题和摘要
text = dataPrepos(text) # 文本预处理
text = " ".join(text) # 连接成字符串,空格分隔
corpus.append(text)
# 1、构建词频矩阵,将文本中的词语转换成词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus) # 词频矩阵,a[i][j]:表示j词在第i个文本中的词频
# 2、统计每个词的tf-idf权值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
# 3、获取词袋模型中的关键词
word = vectorizer.get_feature_names()
# 4、获取tf-idf矩阵,a[i][j]表示j词在i篇文本中的tf-idf权重
weight = tfidf.toarray()
# 5、打印词语权重
ids, titles, keys = [], [], []
for i in range(len(weight)):
print(u"-------这里输出第", i+1 , u"篇文本的词语tf-idf------")
ids.append(idList[i])
titles.append(titleList[i])
df_word,df_weight = [],[] # 当前文章的所有词汇列表、词汇对应权重列表
for j in range(len(word)):
print (word[j],weight[i][j])
return corpus
def main():
# 读取数据集
dataFile = '/data/NLP/sample_data.csv'
data = pd.read_csv(dataFile)
# tf-idf关键词抽取
global corpusA
corpusA = getKeywords_tfidf(data,10)
print(corpusA)
corpusA = []
main()
