以太坊源码情景分析之区块(block)数据同步
区块数据同步分为被动同步和主动同步
被动同步是指本地节点收到其他节点的一些消息,然后请求区块信息。比如NewBlockHashesMsg
主动同步是指节点主动向其他节点请求区块数据,比如geth刚启动时的syning,以及运行时定时和相邻节点同步
被动同步
被动同步由fetcher完成,被动模式又分为两种
- 收到完整的block广播消息(NewBlockMsg)
- 收到blockhash广播消息(NewBlockHashesMsg)
NewBlockHashesMsg被动模式
由于NewBlockHashesMsg被动同步模式下和主动同步模式下都会请求其他节点并接收header和body,因此需要有相关逻辑区分是被动同步模式下请求的数据还是主动模式下请求的数据,这个区分是通过filterHeaders和filterBodies实现的。NewBlockHashesMsg这种模式下逻辑很复杂,我们一起来先看下这种模式下的流程源码
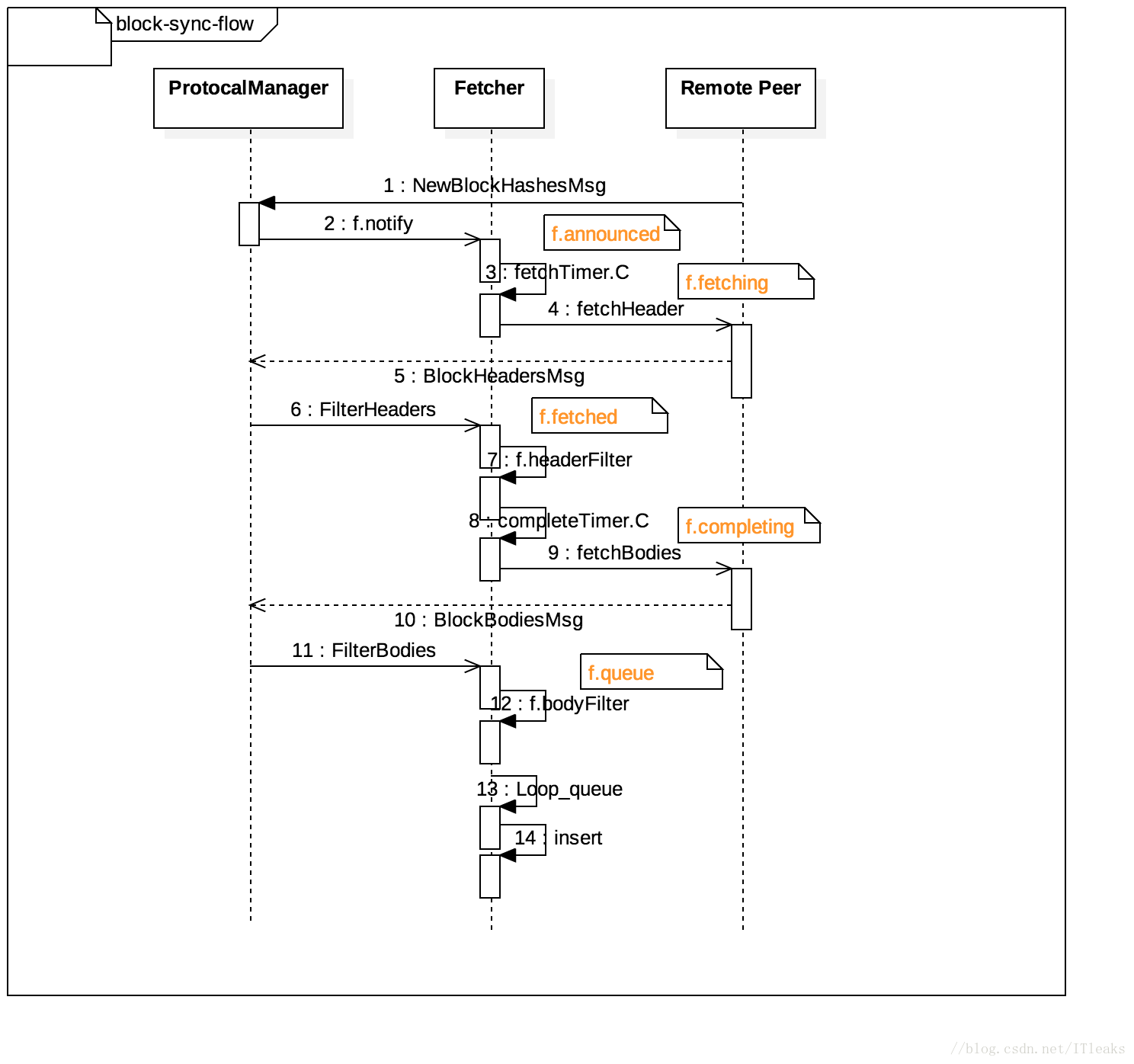
收到外部节点
NewBlockHashesMsg消息,然后发送一个
announce
给fetcher
func (pm *ProtocolManager) handleMsg {
case
msg.Code
==
NewBlockHashesMsg:
var
announces
newBlockHashesData
if
err
:=
msg.
Decode
(
&
announces); err
!=
nil
{
return
errResp
(ErrDecode,
"%v: %v"
, msg, err)
}
// Mark the hashes as present at the remote node
for
_
,
block
:=
range
announces {
p.
MarkBlock
(block.Hash)
}
// Schedule all the unknown hashes for retrieval
unknown
:=
make
(newBlockHashesData,
0
,
len
(announces))
for
_
,
block
:=
range
announces {
if
!
pm.blockchain.
HasBlock
(block.Hash, block.Number) {
unknown
=
append
(unknown, block)
}
}
for
_
,
block
:=
range
unknown {
pm.fetcher.
Notify
(p.id, block.Hash, block.Number, time.
Now
(), p.RequestOneHeader, p.RequestBodies)
}
}
func
(f
*
Fetcher)
Notify
(peer
string
, hash common.Hash, number
uint64
, time time.Time,
headerFetcher headerRequesterFn, bodyFetcher bodyRequesterFn)
error
{
block
:=
&
announce{
hash: hash,
number: number,
time: time,
origin: peer,
fetchHeader: headerFetcher,
fetchBodies: bodyFetcher,
}
select
{
//发送通知
case
f.notify
<-
block:
return
nil
case
<-
f.quit:
return
errTerminated
}
}
fetcher收到announce会将其放置到announced[]数组
func
(f
*
Fetcher)
loop
() {
case
notification
:=
<-
f.notify:
// All is well, schedule the announce if block's not yet downloading
if
_
,
ok
:=
f.fetching[notification.hash]; ok {
break
}
if
_
,
ok
:=
f.completing
[notification.hash]; ok {
break
}
f.announces[notification.origin]
=
count
f.announced[notification.hash]
=
append
(f.announced[notification.hash], notification)
if
f.announceChangeHook
!=
nil
&&
len
(f.announced[notification.hash])
==
1
{
f.
announceChangeHook
(notification.hash,
true
)
}
if
len
(f.announced)
==
1
{
f.rescheduleFetch(fetchTimer)
}
}
fetchTimer工作场景
-
f.announced的len=1,上面会调用f.rescheduleFetch,然后就会进入fetchTimer.C分支
- f.announced的len > 1,则它自身会不停的调用自己,知道将所有announce处理完毕
fetchTimer会将announce放置到f.fetching并调用fetchHeader请求其他节点获取header数据
func
(f
*
Fetcher)
loop
() {
case
<-
fetchTimer.C:
// At least one block's timer ran out, check for needing retrieval
request
:=
make
(
map
[
string
][]common.Hash)
for
hash
,
announces
:=
range
f.announced {
if
time.
Since
(announces[
0
].time)
>
arriveTimeout
-
gatherSlack {
// Pick a random peer to retrieve from, reset all others
announce
:=
announces[rand.
Intn
(
len
(announces))]
f.
forgetHash
(hash)
// If the block still didn't arrive, queue for fetching
if
f.
getBlock
(hash)
==
nil
{
request[announce.origin]
=
append
(request[announce.origin], hash)
f.fetching
[hash]
=
announce
}
}
}
// Send out all block header requests
for
peer
,
hashes
:=
range
request {
// Create a closure of the fetch and schedule in on a new thread
fetchHeader
,
hashes
:=
f.fetching[hashes[
0
]].fetchHeader, hashes
go
func
() {
if
f.fetchingHook
!=
nil
{
f.
fetchingHook
(hashes)
}
for
_
,
hash
:=
range
hashes
{
headerFetchMeter.
Mark
(
1
)
fetchHeader
(hash)
// Suboptimal, but protocol doesn't allow batch header retrievals
}
}()
}
// Schedule the next fetch if blocks are still pending
//不停处理pending的fetch,直到announced的len=0
f.rescheduleFetch(fetchTimer)
}
func
(f
*
Fetcher)
rescheduleFetch
(fetch
*
time.Timer) {
// Short circuit if no blocks are announced
if len(f.announced) == 0 {
return
}
// Otherwise find the earliest expiring announcement
earliest
:=
time.
Now
()
for
_
,
announces
:=
range
f.announced {
if
earliest.
After
(announces[
0
].time) {
earliest
=
announces[
0
].time
}
}
fetch.
Reset
(arriveTimeout
-
time.
Since
(earliest))
}
其他节点返回header数据后,本地节点收到
BlockHeadersMsg消息并处理
func
(pm
*
ProtocolManager)
handleMsg {
case msg.Code == BlockHeadersMsg:
// A batch of headers arrived to one of our previous requests
var
headers
[]
*
types.Header
if
err
:=
msg.
Decode
(
&
headers); err
!=
nil
{
return
errResp
(ErrDecode,
"msg %v: %v"
, msg, err)
}
// Filter out any explicitly requested headers, deliver the rest to the downloader
//被动请求情况下就是请求一条,所以这里filter=True
filter
:=
len
(headers)
==
1
if
filter {
// Irrelevant of the fork checks, send the header to the fetcher just in case
headers
=
pm.fetcher.
FilterHeaders
(p.id, headers, time.
Now
())
}
if
len
(headers)
>
0
||
!
filter {
err
:=
pm.downloader.
DeliverHeaders
(p.id, headers)
if
err
!=
nil
{
log.
Debug
(
"Failed to deliver headers"
,
"err"
, err)
}
}
}
func
(f *Fetcher)
FilterHeaders
(peer
string
, headers []*types.Header, time
time.Time) []*types.Header {
log.
Trace
(
"Filtering headers"
,
"peer"
, peer,
"headers"
,
len
(headers))
// Send the filter channel to the fetcher
filter
:=
make
(
chan
*headerFilterTask)
select
{
case f.headerFilter <- filter:
case
<-
f.quit:
return
nil
}
// Request the filtering of the header list
select
{
case filter <- &headerFilterTask{peer: peer, headers: headers, time: time}:
case
<-
f.quit:
return
nil
}
// Retrieve the headers remaining after filtering
select
{
//等待结果
case task := <-filter:
return
task.headers
case
<-
f.quit:
return
nil
}
}
headerFilterTask来执行filter任务,这里的代码有点特别,是将一个chan(filter)通道对象作为数据传递给另外一个chan(f.headerFilter)通道,并紧接着传headerFilterTask给filter, 同时会从filter读取返回值,类似双工的工作模式
func (f *Fetcher) loop() {
case
filter := <-f.headerFilter:
// Headers arrived from a remote peer. Extract those that were explicitly
// requested by the fetcher, and return everything else so it's delivered
// to other parts of the system.
var
task
*
headerFilterTask
select
{
//获取任务
case task = <-filter:
case
<-
f.quit:
return
}
// Split the batch of headers into unknown ones (to return to the caller),
// known incomplete ones (requiring body retrievals) and completed blocks.
//检查是否已经存在对应的task
unknown
,
incomplete
,
complete
:=
[]
*
types.Header{}, []
*
announce{}, []
*
types.Block{}
for
_
,
header
:=
range
task.headers {
hash
:=
header.
Hash
()
// Filter fetcher-requested headers from other synchronisation algorithms
if
announce
:=
f.fetching[hash]; announce
!=
nil
&&
announce.origin
==
task.peer
&&
f.fetched[hash]
==
nil
&&
f.completing[hash]
==
nil
&&
f.queued[hash]
==
nil
{
// Only keep if not imported by other means
if
f.
getBlock
(hash)
==
nil
{
announce.header
=
header
announce.time
=
task.time
// If the block is empty (header only), short circuit into the final import queue
if
header.TxHash
==
types.
DeriveSha
(types.Transactions{})
&&
header.UncleHash
==
types.
CalcUncleHash
([]
*
types.Header{}) {
log.
Trace
(
"Block empty, skipping body retrieval"
,
"peer"
, announce.origin,
"number"
, header.Number,
"hash"
, header.
Hash
())
block
:=
types.
NewBlockWithHeader
(header)
block.ReceivedAt
=
task.time
complete = append(complete, block)
f.completing[hash]
=
announce
continue
}
// Otherwise add to the list of blocks needing completion
incomplete = append(incomplete, announce)
}
else
{
log.
Trace
(
"Block already imported, discarding header"
,
"peer"
, announce.origin,
"number"
, header.Number,
"hash"
, header.
Hash
())
f.
forgetHash
(hash)
}
}
else
{
// Fetcher doesn't know about it, add to the return list
unknown
=
append
(unknown, header)
}
}
select
{
//返回数据
case filter <- &headerFilterTask{headers: unknown, time: task.time}:
case
<-
f.quit:
return
}
// Schedule the retrieved headers for body completion
for
_
,
announce
:=
range
incomplete {
hash
:=
announce.header.
Hash
()
if
_
,
ok
:=
f.completing[hash]; ok {
continue
}
f.fetched[hash]
=
append
(f.fetched[hash], announce)
if
len
(f.fetched)
==
1
{
f.rescheduleComplete(completeTimer)
}
}
// Schedule the header-only blocks for import
for
_
,
block
:=
range
complete {
if
announce
:=
f.completing[block.
Hash
()]; announce
!=
nil
{
f.
enqueue
(announce.origin, block)
}
}
}
上面代码对远端传递过来的header检验是否在f.fetching里(被动获取模式下,应该在f.fetching里面),并判读是否获取body,如果不需要继续获取body则将announce放到complete,并将数据enqueue到queued。否则将将announce放置到fetched,并请求body.
对于需要继续请求body的,会到达completeTimer.C
func
(f
*
Fetcher)
loop
() {
case
<-
completeTimer.C:
// At least one header's timer ran out, retrieve everything
request
:=
make
(
map
[
string
][]common.Hash)
for
hash
,
announces
:=
range
f.fetched
{
// Pick a random peer to retrieve from, reset all others
announce
:=
announces[rand.
Intn
(
len
(announces))]
f.
forgetHash
(hash)
// If the block still didn't arrive, queue for completion
if
f.
getBlock
(hash)
==
nil
{
request[announce.origin]
=
append
(request[announce.origin], hash)
//放置到completing里
f.completing
[hash]
=
announce
}
}
// Send out all block body requests
for
peer
,
hashes
:=
range
request {
log.
Trace
(
"Fetching scheduled bodies"
,
"peer"
, peer,
"list"
, hashes)
// Create a closure of the fetch and schedule in on a new thread
if
f.completingHook
!=
nil
{
f.
completingHook
(hashes)
}
bodyFetchMeter.
Mark
(
int64
(
len
(hashes)))
//请求body
go f.completing[hashes[0]].fetchBodies(hashes)
}
// Schedule the next fetch if blocks are still pending
f.
rescheduleComplete
(completeTimer)
completeTimer.C会将请求放到f.completing,以在后面的逻辑里匹配数据
Boy回来时本地会收到BlockBodiesMsg
func (pm *ProtocolManager) handleMsg {
case
msg.Code
==
BlockBodiesMsg:
// A batch of block bodies arrived to one of our previous requests
var
request
blockBodiesData
if
err
:=
msg.
Decode
(
&
request); err
!=
nil
{
return
errResp
(ErrDecode,
"msg %v: %v"
, msg, err)
}
// Deliver them all to the downloader for queuing
trasactions
:=
make
([][]
*
types.Transaction,
len
(request))
uncles
:=
make
([][]
*
types.Header,
len
(request))
for
i
,
body
:=
range
request {
trasactions[i]
=
body.Transactions
uncles[i]
=
body.Uncles
}
// Filter out any explicitly requested bodies, deliver the rest to the downloader
filter
:=
len
(trasactions)
>
0
||
len
(uncles)
>
0
//同样是filter模式,所以不会在下面走pm.downloader.DeliverBodies
if
filter {
trasactions, uncles = pm.fetcher.FilterBodies(p.id, trasactions, uncles, time.Now())
}
if
len
(trasactions)
>
0
||
len
(uncles)
>
0
||
!
filter {
err := pm.downloader.DeliverBodies(p.id, trasactions, uncles)
if
err
!=
nil
{
log.
Debug
(
"Failed to deliver bodies"
,
"err"
, err)
}
}
}
func
(f
*
Fetcher)
FilterBodies
(peer
string
, transactions [][]
*
types.Transaction, uncles [][]
*
types.Header, time time.Time) ([][]
*
types.Transaction, [][]
*
types.Header) {
log.
Trace
(
"Filtering bodies"
,
"peer"
, peer,
"txs"
,
len
(transactions),
"uncles"
,
len
(uncles))
// Send the filter channel to the fetcher
filter
:=
make
(
chan
*
bodyFilterTask)
select
{
case
f.bodyFilter
<-
filter:
case
<-
f.quit:
return
nil
,
nil
}
// Request the filtering of the body list
select
{
case filter <- &bodyFilterTask{peer: peer, transactions: transactions, uncles: uncles, time: time}:
case
<-
f.quit:
return
nil
,
nil
}
// Retrieve the bodies remaining after filtering
select
{
case
task
:=
<-
filter:
return
task.transactions, task.uncles
case
<-
f.quit:
return
nil
,
nil
}
}
func
(f
*
Fetcher)
loop
() {
case
filter
:=
<-
f.bodyFilter:
// Block bodies arrived, extract any explicitly requested blocks, return the rest
var
task
*
bodyFilterTask
select
{
case
task
=
<-
filter:
case
<-
f.quit:
return
}
bodyFilterInMeter.
Mark
(
int64
(
len
(task.transactions)))
blocks
:=
[]
*
types.Block{}
for
i
:=
0
; i
<
len
(task.transactions)
&&
i
<
len
(task.uncles); i
++
{
// Match up a body to any possible completion request
matched
:=
false
for hash, announce := range f.completing {
if
f.queued[hash]
==
nil
{
txnHash
:=
types.
DeriveSha
(types.
Transactions
(task.transactions[i]))
uncleHash
:=
types.
CalcUncleHash
(task.uncles[i])
if
txnHash
==
announce.header.TxHash
&&
uncleHash
==
announce.header.UncleHash
&&
announce.origin
==
task.peer {
// Mark the body matched, reassemble if still unknown
matched
=
true
if
f.
getBlock
(hash)
==
nil
{
block
:=
types.
NewBlockWithHeader
(announce.header).
WithBody
(task.transactions[i], task.uncles[i])
block.ReceivedAt
=
task.time
blocks = append(blocks, block)
}
else
{
f.
forgetHash
(hash)
}
}
}
}
if
matched {
task.transactions
=
append
(task.transactions[:i], task.transactions[i
+
1
:]
...
)
task.uncles
=
append
(task.uncles[:i], task.uncles[i
+
1
:]
...
)
i
--
continue
}
}
bodyFilterOutMeter.
Mark
(
int64
(
len
(task.transactions)))
select
{
case
filter
<-
task:
case
<-
f.quit:
return
}
// Schedule the retrieved blocks for ordered import
for
_
,
block
:=
range
blocks {
if
announce
:=
f.completing[block.
Hash
()]; announce
!=
nil
{
f.enqueue(announce.origin, block)
}
}
}
}
FilterBodies和FilterHeader类似,就是检测其他节点发送回的body数据是不是我们被动请求的数据(在不在f.completing里面),符合条件的会放到f.queued里面,否则过滤掉
到这个点,请求body和不请求body两种情况下获得的数据都会通过f.enqueue放置到f.equed数组里,不是被动请求的header, body数据会放到downloader里
func
(f
*
Fetcher)
enqueue
(peer
string
, block
*
types.Block) {
hash
:=
block.
Hash
()
// Schedule the block for future importing
if
_
,
ok
:=
f.queued[hash];
!
ok {
op
:=
&
inject{
origin: peer,
block: block,
}
f.queues[peer]
=
count
f.queued[hash] = op
f.queue.Push(op, -float32(block.NumberU64()))
if
f.queueChangeHook
!=
nil
{
f.
queueChangeHook
(op.block.
Hash
(),
true
)
}
}
}
上面的filterBody执行完,fetcher.loop会进入下一次循环,这时f.queue不为空,就会接着处理这个数据并插入到主链
func
(f
*
Fetcher)
loop
() {
// Iterate the block fetching until a quit is requested
fetchTimer
:=
time.
NewTimer
(
0
)
completeTimer
:=
time.
NewTimer
(
0
)
for
{
// Import any queued blocks that could potentially fit
height
:=
f.
chainHeight
()
//遍历f.queue
for !f.queue.Empty() {
op
:=
f.queue.
PopItem
().(
*
inject)
if
f.queueChangeHook
!=
nil
{
f.
queueChangeHook
(op.block.
Hash
(),
false
)
}
// If too high up the chain or phase, continue later
number
:=
op.block.
NumberU64
()
//如果高度不连续,没法作为head,push回去以备后面用
if
number
>
height
+
1
{
f.queue.
Push
(op,
-
float32
(op.block.
NumberU64
()))
if
f.queueChangeHook
!=
nil
{
f.
queueChangeHook
(op.block.
Hash
(),
true
)
}
break
}
// Otherwise if fresh and still unknown, try and import
hash
:=
op.block.
Hash
()
if
number
+
maxUncleDist
<
height
||
f.
getBlock
(hash)
!=
nil
{
f.
forgetBlock
(hash)
continue
}
//插入链作为头部
f.insert(op.origin, op.block)
}
}
}
func
(f
*
Fetcher)
insert
(peer
string
, block
*
types.Block) {
hash
:=
block.
Hash
()
// Run the import on a new thread
log.
Debug
(
"Importing propagated block"
,
"peer"
, peer,
"number"
, block.
Number
(),
"hash"
, hash)
go
func
() {
//赋值done,表示这次被动block请求完成,然后会清楚这次请求的所有数据
defer func() { f.done <- hash }()
// If the parent's unknown, abort insertion
parent
:=
f.
getBlock
(block.
ParentHash
())
if
parent
==
nil
{
log.
Debug
(
"Unknown parent of propagated block"
,
"peer"
, peer,
"number"
, block.
Number
(),
"hash"
, hash,
"parent"
, block.
ParentHash
())
return
}
// Quickly validate the header and propagate the block if it passes
switch
err
:=
f.
verifyHeader
(block.
Header
()); err {
case
nil
:
// All ok, quickly propagate to our peers
propBroadcastOutTimer.
UpdateSince
(block.ReceivedAt)
go
f.
broadcastBlock
(block,
true
)
case
consensus.ErrFutureBlock:
// Weird future block, don't fail, but neither propagate
default
:
// Something went very wrong, drop the peer
log.
Debug
(
"Propagated block verification failed"
,
"peer"
, peer,
"number"
, block.
Number
(),
"hash"
, hash,
"err"
, err)
f.
dropPeer
(peer)
return
}
// Run the actual import and log any issues
if
_
,
err
:=
f.insertChain
(types.Blocks{block}); err
!=
nil
{
log.
Debug
(
"Propagated block import failed"
,
"peer"
, peer,
"number"
, block.
Number
(),
"hash"
, hash,
"err"
, err)
return
}
// If import succeeded, broadcast the block
propAnnounceOutTimer.
UpdateSince
(block.ReceivedAt)
//向其他节点广播新block
go f.broadcastBlock(block, false)
// Invoke the testing hook if needed
if
f.importedHook
!=
nil
{
f.
importedHook
(block)
}
}()
}
func
(f
*
Fetcher)
loop
() {
case
hash
:=
<-
f.done:
// A pending import finished, remove all traces of the notification
f.
forgetHash
(hash)
f.
forgetBlock
(hash)
}
Fetcher.insert检测block的合法性,通过验证后即插入主链并向外广播
总结:
fetch请求一个block的数据,中间会经历很多过程,并维护了一个状态机,利用这个状态机可以区分其他节点返回回来的body和header是不是这次请求的返回数据.这个状态机的转换伴随着block信息推进到不同的变量,具体流程如下:
f.announced->f.fetching->f.fetched->f.completing->f.queue
NewBlockMsg被动模式
这个代码逻辑相对简单,就不分析源码了,大家可以结合下面的时序图自己看看
主动同步
同步入口
主动同步有好几个主要场景
- geth刚启动
- 新peer加入
- 定时sync
后面两个场景入口都在ProtocolManager.syncer
func
(pm
*
ProtocolManager)
syncer
() {
// Start and ensure cleanup of sync mechanisms
pm.fetcher.
Start
()
defer
pm.fetcher.
Stop
()
defer
pm.downloader.
Terminate
()
// Wait for different events to fire synchronisation operations
forceSync
:=
time.
NewTicker
(forceSyncCycle)
defer
forceSync.
Stop
()
for
{
select
{
case
<-
pm.newPeerCh:
// Make sure we have peers to select from, then sync
if
pm.peers.
Len
()
<
minDesiredPeerCount {
break
}
go pm.synchronise(pm.peers.BestPeer())
case
<-
forceSync.C:
// Force a sync even if not enough peers are present
go pm.synchronise(pm.peers.BestPeer())
case
<-
pm.noMorePeers:
return
}
}
}
可见syncing的入口函数是synchronise
func
(pm
*
ProtocolManager)
synchronise
(peer
*
peer) {
// Otherwise try to sync with the downloader
mode
:=
downloader.FullSync
if
atomic.
LoadUint32
(
&
pm.fastSync)
==
1
{
// Fast sync was explicitly requested, and explicitly granted
mode = downloader.FastSync
}
else
if
currentBlock.
NumberU64
()
==
0
&&
pm.blockchain.
CurrentFastBlock
().
NumberU64
()
>
0
{
// The database seems empty as the current block is the genesis. Yet the fast
// block is ahead, so fast sync was enabled for this node at a certain point.
// The only scenario where this can happen is if the user manually (or via a
// bad block) rolled back a fast sync node below the sync point. In this case
// however it's safe to reenable fast sync.
atomic.
StoreUint32
(
&
pm.fastSync,
1
)
mode = downloader.FastSync
}
// Run the sync cycle, and disable fast sync if we've went past the pivot block
if
err
:=
pm.downloader.
Synchronise
(peer.id, pHead, pTd, mode); err
!=
nil
{
return
}
if
head
:=
pm.blockchain.
CurrentBlock
(); head.
NumberU64
()
>
0
{
// We've completed a sync cycle, notify all peers of new state. This path is
// essential in star-topology networks where a gateway node needs to notify
// all its out-of-date peers of the availability of a new block. This failure
// scenario will most often crop up in private and hackathon networks with
// degenerate connectivity, but it should be healthy for the mainnet too to
// more reliably update peers or the local TD state.
//通知邻近节点有新块
go pm.BroadcastBlock(head, false)
}
}
func
(d
*
Downloader)
Synchronise
(id
string
, head common.Hash, td
* big.Int
, mode SyncMode)
error
{
err := d.synchronise(id, head, td, mode)
....
return
err
}
func
(d
*
Downloader)
synchronise
(id
string
, hash common.Hash, td
* big.Int
, mode SyncMode)
error
{
// Set the requested sync mode, unless it's forbidden
d.mode
=
mode
// Retrieve the origin peer and initiate the downloading process
p
:=
d.peers.
Peer
(id)
if
p
==
nil
{
return
errUnknownPeer
}
return
d.syncWithPeer
(p, hash, td)
}
查找通信节点主链共同祖先
我们知道同步数据块有一个很重要的事情需要准备,就是找到两个节点链的共同祖先(findAncestor)
func
(d
*
Downloader)
syncWithPeer
(p
*
peerConnection, hash common.Hash, td
* big.Int
) (err
error
) {
origin
,
err
:=
d.
findAncestor
(p, height)
}
这个模块,比特币和以太币的实现很不一样
- 比特币是将本地chain顶端N个block的hash及后续以1/2跳跃的方式得到m个block的hash(blocklocator)发送给外部节点,这样外部节点能轻松的找到两个节点的链的共同祖先
- 以太币不一样,它分两个步骤来操作,第一步是向外部节点请求N个block的hash并和本地对比找到共同祖先,如果第一步没有找到祖先,则按照类似1/2跳跃的方式循环请求更前面的区块的hash,并和本地对比来找到共同祖先
- 可见两种方式的核心区别是,比特币是主动提供本地链区块头信息,外部节点负责找出祖先,而以太币是从外部节点获取数据,本地负责找出祖先。如果共同祖先大部分都是在前N个区块,这两种方式差不多,但是如果进行到1/2跳跃请求,则以太坊的请求次数明显增多。
func
(d
*
Downloader)
findAncestor
(p
*
peerConnection, height
uint64
) (
uint64
,
error
) {
// Figure out the valid ancestor range to prevent rewrite attacks
floor
,
ceil
:=
int64
(
-
1
), d.lightchain.
CurrentHeader
().Number.
Uint64
()
if
d.mode
==
FullSync {
ceil
=
d.blockchain.
CurrentBlock
().
NumberU64
()
}
else
if
d.mode
==
FastSync {
ceil
=
d.blockchain.
CurrentFastBlock
().
NumberU64
()
}
if
ceil
>=
MaxForkAncestry {
floor
=
int64
(ceil
-
MaxForkAncestry)
}
p.log.
Debug
(
"Looking for common ancestor"
,
"local"
, ceil,
"remote"
, height)
// Request the topmost blocks to short circuit binary ancestor lookup
head
:=
ceil
if
head
>
height {
head
=
height
}
//请求tip区块前N=MaxHeaderFetch个区块的信息
from
:=
int64
(head)
-
int64
(MaxHeaderFetch)
if
from
<
0
{
from
=
0
}
// Span out with 15 block gaps into the future to catch bad head reports
limit
:=
2
*
MaxHeaderFetch
/
16
count
:=
1
+
int
((
int64
(ceil)
-
from)
/
16
)
if
count
>
limit {
count
=
limit
}
//请求前N=MaxHeaderFetch个区块头
go p.peer.RequestHeadersByNumber(uint64(from), count, 15, false)
// Wait for the remote response to the head fetch
number
,
hash
:=
uint64
(
0
), common.Hash{}
ttl
:=
d.
requestTTL
()
timeout
:=
time.
After
(ttl)
for
finished
:=
false
;
!
finished; {
select
{
//接收到区块头数据
case
packet
:=
<-
d.headerCh:
// Discard anything not from the origin peer
if
packet.
PeerId
()
!=
p.id
{
log.
Debug
(
"Received headers from incorrect peer"
,
"peer"
, packet.
PeerId
())
break
}
// Make sure the peer actually gave something valid
headers := packet.(*headerPack).headers
if
len
(headers)
==
0
{
p.log.
Warn
(
"Empty head header set"
)
return
0
, errEmptyHeaderSet
}
// Make sure the peer's reply conforms to the request
for
i
:=
0
; i
<
len
(headers); i
++
{
//验证这些返回的header是否是我们上面请求的headers
if number := headers[i].Number.Int64(); number != from+int64(i)*16 {
p.log.
Warn
(
"Head headers broke chain ordering"
,
"index"
, i,
"requested"
, from
+
int64
(i)
*
16
,
"received"
, number)
return
0
, errInvalidChain
}
}
// Check if a common ancestor was found
finished
=
true
for i := len(headers) - 1; i >= 0; i-- {
// Skip any headers that underflow/overflow our requested set
if
headers[i].Number.
Int64
()
<
from
||
headers[i].Number.
Uint64
()
>
ceil {
continue
}
// Otherwise check if we already know the header or not
if
(d.mode
==
FullSync
&&
d.blockchain.HasBlock(headers[i].Hash(), headers[i].Number.Uint64()))
||
(d.mode
!=
FullSync
&&
d.lightchain.
HasHeader
(headers[i].
Hash
(), headers[i].Number.
Uint64
())) {
number
,
hash
=
headers[i].Number.
Uint64
(), headers[i].
Hash
()
// If every header is known, even future ones, the peer straight out lied about its head
if
number
>
height
&&
i
==
limit
-
1
{
p.log.
Warn
(
"Lied about chain head"
,
"reported"
, height,
"found"
, number)
return
0
, errStallingPeer
}
break
}
}
// Out of bounds delivery, ignore
}
}
// Ancestor not found, we need to binary search over our chain
start
,
end
:=
uint64
(
0
), head
if
floor
>
0
{
start
=
uint64
(floor)
}
//1/2跳跃模式的循环请求
for
start
+
1
<
end {
// Split our chain interval in two, and request the hash to cross check
check
:=
(start
+
end)
/
2
ttl
:=
d.
requestTTL
()
timeout
:=
time.
After
(ttl)
go p.peer.RequestHeadersByNumber(check, 1, 0, false)
// Wait until a reply arrives to this request
for
arrived
:=
false
;
!
arrived; {
select
{
case
<-
d.cancelCh:
return
0
, errCancelHeaderFetch
case packer := <-d.headerCh:
// Discard anything not from the origin peer
…
}
}
return
start,
nil
}
数据请求流程
找到共同祖先区块origin block后就是请求获取数据了
func
(d
*
Downloader)
syncWithPeer
(p
*
peerConnection, hash common.Hash, td
* big.Int
) (err
error
) {
origin, err := d.findAncestor(p, height)
fetchers
:=
[]
func
()
error
{
func
()
error
{
return
d.
fetchHeaders
(p, origin
+
1
, pivot) },
// Headers are always retrieved
func
()
error
{
return
d.
fetchBodies
(origin
+
1
) },
// Bodies are retrieved during normal and fast sync
func
()
error
{
return
d.
fetchReceipts
(origin
+
1
) },
// Receipts are retrieved during fast sync
func
()
error
{
return
d.
processHeaders
(origin
+
1
, pivot, td) },
}
if
d.mode
==
FastSync {
fetchers
=
append
(fetchers,
func
()
error
{
return
d.
processFastSyncContent
(latest) })
}
else
if
d.mode
==
FullSync {
fetchers
=
append
(fetchers,
d.processFullSyncContent
)
}
return
d.
spawnSync
(fetchers)
}
func
(d
*
Downloader)
spawnSync
(fetchers []
func
()
error
)
error
{
var
wg
sync.WaitGroup
errc
:=
make
(
chan
error
,
len
(fetchers))
wg.
Add
(
len
(fetchers))
for
_
,
fn
:=
range
fetchers
{
fn
:=
fn
go
func
() {
defer
wg.
Done
(); errc
<-
fn
() }()
}
// Wait for the first error, then terminate the others.
var
err
error
for
i
:=
0
; i
<
len
(fetchers); i
++
{
if
i
==
len
(fetchers)
-
1
{
// Close the queue when all fetchers have exited.
// This will cause the block processor to end when
// it has processed the queue.
d.queue.
Close
()
}
if
err
=
<-
errc; err
!=
nil
{
break
}
}
d.queue.
Close
()
d.
Cancel
()
wg.
Wait
()
return
err
}
可见syncing的大概过程就是调用
-
调用fetchHeaders, fetchBodies, fetchReceipts请求数据
- 调用processHeaders, processFullSyncContent处理数据
我们知道fetchBodies和fetchReceipts是依赖header数据的,所以自然需要等待header请求数据返回后才能执行,所以这些函数的执行应该是有顺序的,执行顺序如下
但是这几个过程都是一个独立的go routine, 这些函数先后顺序又是如何保证的?估计你大概都能猜测到,通过chan, 一个等待,一个通知的方式即可实现。
因为fetchBodies,fetchReceipts行为差不多,但是他们都依赖fetchHeaders的,因而和fetchHeaders不一样
fetchHeader只需要两步
- 请求数据(fetch)
- 等待并接收数据(wait-result)
而fetchBodies, fetchReceipt多一个步骤
- 等待header数据(wait-header)
- 请求数据(fetch)
- 等待并接收数据(wait-result)
整个流程图大致如下:
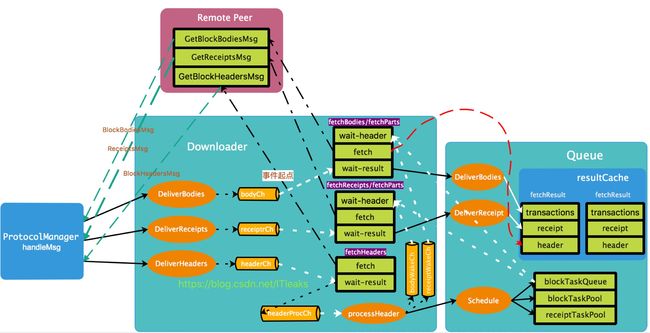
这个流程涉及点多, 最难的点是fetchBodies和fetchReceipt等待header数据的过程,按照这个流程图我们来分析下这个等待header的代码
fetchBodies,fetchReceipt最后都是调用fetchParts,只是参数不一样,然后就分别等待在bodyWakeCh,receiptWakeCh上。
func
(d
*
Downloader)
fetchParts
(errCancel
error
, deliveryCh
chan
dataPack, deliver
func
(dataPack) (
int
,
error
), wakeCh
chan
bool
,
expire
func
()
map
[
string
]
int
, pending
func
()
int
, inFlight
func
()
bool
, throttle
func
()
bool
, reserve
func
(
*
peerConnection,
int
) (
*
fetchRequest,
bool
,
error
),
fetchHook
func
([]
*
types.Header), fetch
func
(
*
peerConnection,
*
fetchRequest)
error
, cancel
func
(
*
fetchRequest), capacity
func
(
*
peerConnection)
int
,
idle
func
() ([]
*
peerConnection,
int
), setIdle
func
(
*
peerConnection,
int
), kind
string
)
error
{
// Create a ticker to detect expired retrieval tasks
ticker
:=
time.
NewTicker
(
100
*
time.Millisecond)
defer
ticker.
Stop
()
update
:=
make
(
chan
struct
{},
1
)
// Prepare the queue and fetch block parts until the block header fetcher's done
finished
:=
false
for
{
select
{
//这里的wakeCh就是bodyWakeCh或者receiptWakeCh
case cont := <-wakeCh:
// The header fetcher sent a continuation flag, check if it's done
if
!
cont {
finished
=
true
}
// Headers arrive, try to update the progress
select
{
//会唤醒update逻辑,也即fetch逻辑
case update <- struct{}{}:
default
:
}
case
<-
ticker.C:
// Sanity check update the progress
select
{
case update <- struct{}{}:
default
:
}
case
<-
update:
// If there's nothing more to fetch, wait or terminate
//上面的tick,wake都会唤醒进入该逻辑,所以需要检测是否有pending task
// 如果是header数据接收后,则是先进入wakeCH然后进入这里的,且pending() > 0
if pending() == 0 {
if
!
inFlight
()
&&
finished {
log.
Debug
(
"Data fetching completed"
,
"type"
, kind)
return
nil
}
break
}
// Send a download request to all idle peers, until throttled
progressed
,
throttled
,
running
:=
false
,
false
,
inFlight
()
idles
,
total
:=
idle
()
for
_
,
peer
:=
range
idles {
// Short circuit if throttling activated
if
throttle
() {
throttled
=
true
break
}
// Short circuit if there is no more available task.
if
pending
()
==
0
{
break
}
// Reserve a chunk of fetches for a peer. A nil can mean either that
// no more headers are available, or that the peer is known not to
// have them.
//reserve是reserveBodies或者reserveReceipt
//该函数会从bodyTaskPool或者receiptTaskPool里取出task,也就是request
request, progress, err := reserve(peer, capacity(peer))
if
err
!=
nil
{
return
err
}
if
progress {
progressed
=
true
}
if
request
==
nil
{
continue
}
if
request.From
>
0
{
peer.log.
Trace
(
"Requesting new batch of data"
,
"type"
, kind,
"from"
, request.From)
}
else
{
peer.log.
Trace
(
"Requesting new batch of data"
,
"type"
, kind,
"count"
,
len
(request.Headers),
"from"
, request.Headers[
0
].Number)
}
// Fetch the chunk and make sure any errors return the hashes to the queue
if
fetchHook
!=
nil
{
fetchHook
(request.Headers)
}
//这里是发出GetBlockBodyMsg,GetReceiptMsg请求数据的函数
if err := fetch(peer, request); err != nil {
// Although we could try and make an attempt to fix this, this error really
// means that we've double allocated a fetch task to a peer. If that is the
// case, the internal state of the downloader and the queue is very wrong so
// better hard crash and note the error instead of silently accumulating into
// a much bigger issue.
panic
(fmt.
Sprintf
(
"%v: %s fetch assignment failed"
, peer, kind))
}
running
=
true
}
// Make sure that we have peers available for fetching. If all peers have been tried
// and all failed throw an error
if
!
progressed
&&
!
throttled
&&
!
running
&&
len
(idles)
==
total
&&
pending
()
>
0
{
return
errPeersUnavailable
}
}
}
}
所以核心点是:bodyWakeCh,receiptWakeCh及blockTaskQueue, blockTaskPool, receiptTaskPool在哪里赋值的
func
(d
*
Downloader)
processHeaders
(origin
uint64
, pivot
uint64
, td
* big.Int
)
error
{
for
{
select
{
case
<-
d.cancelCh:
return
errCancelHeaderProcessing
case headers := <-d.headerProcCh:
// Terminate header processing if we synced up
if
len
(headers)
==
0
{
// Notify everyone that headers are fully processed
//没有Header数据,但是仍旧需要通知
for _, ch := range []chan bool{d.bodyWakeCh, d.receiptWakeCh} {
select
{
case
ch
<-
false
:
case
<-
d.cancelCh:
}
}
…
rollback
=
nil
return
nil
}
// Otherwise split the chunk of headers into batches and process them
gotHeaders
=
true
for
len
(headers)
>
0
{
// Select the next chunk of headers to import
limit
:=
maxHeadersProcess
if
limit
>
len
(headers) {
limit
=
len
(headers)
}
chunk
:=
headers[:limit]
….
// Unless we're doing light chains, schedule the headers for associated content retrieval
if
d.mode
==
FullSync
||
d.mode
==
FastSync {
….
// Otherwise insert the headers for content retrieval
inserts := d.queue.Schedule(chunk, origin)
if
len
(inserts)
!=
len
(chunk) {
log.
Debug
(
"Stale headers"
)
return
errBadPeer
}
}
headers
=
headers[limit:]
origin
+=
uint64
(limit)
}
...
// Signal the content downloaders of the availablility of new tasks
// 这里会唤醒前面的fetchParts
for _, ch := range []chan bool{d.bodyWakeCh, d.receiptWakeCh} {
select
{
case ch <- true:
default
:
}
}
}
}
}
func (q *queue)
Schedule(headers []*types.Header, from
uint64) []*types.Header {
q.lock.
Lock()
defer q.lock.
Unlock()
// Insert all the headers prioritised by the contained block number
inserts :=
make([]*types.Header,
0,
len(headers))
for
_,
header :=
range headers {
// Make sure chain order is honoured and preserved throughout
….
// Queue the header for content retrieval
q.blockTaskPool[hash] = header
q.blockTaskQueue.
Push(header, -
float32(header.Number.
Uint64()))
if q.mode == FastSync {
q.receiptTaskPool[hash] = header
q.receiptTaskQueue.
Push(header, -
float32(header.Number.
Uint64()))
}
inserts =
append(inserts, header)
q.headerHead = hash
from++
}
return inserts
}
数据填充及组装
区块数据的请求的目标是获取header,body, receipt数据,这些数据到达后会添加到queue.resultCache[index]的一个fetchResult对象里面。这个对象的header数据有点特殊,它不是由processHeader添加进去的,而是在fetchBodies真正调用fetch请求bodies数据时通过new fetchResult初始化赋值的。
所有数据准备好后,processFullSyncContent会被唤醒并读取fetchResult并插入到主链
fetchResult数据结构:
type
fetchResult
struct
{
Pending
int
// Number of data fetches still pending
Hash common.Hash
// Hash of the header to prevent recalculating
Header
*
types.Header
Uncles []
*
types.Header
Transactions types.Transactions
Receipts types.Receipts
}
Header数据填充点:
func
(d
*
Downloader)
fetchParts
(errCancel
error
, deliveryCh
chan
dataPack, deliver
func
(dataPack) (
int
,
error
), wakeCh
chan
bool) {
case
<-
update:
request
,
progress
,
err
:=
reserve
(peer,
capacity
(peer))
}
func
(q
*
queue)
ReserveBodies
(p
*
peerConnection, count
int
) (
*
fetchRequest,
bool
,
error
) {
isNoop
:=
func
(header
*
types.Header)
bool
{
return
header.TxHash
==
types.EmptyRootHash
&&
header.UncleHash
==
types.EmptyUncleHash
}
q.lock.
Lock
()
defer
q.lock.
Unlock
()
return
q.reserveHeaders
(p, count, q.blockTaskPool, q.blockTaskQueue, q.blockPendPool, q.blockDonePool, isNoop)
}
func
(q
*
queue)
reserveHeaders
(p
*
peerConnection, count
int
, taskPool
map
[common.Hash]
*
types.Header, taskQueue
*
prque.Prque,
pendPool
map
[
string
]
*
fetchRequest, donePool
map
[common.Hash]
struct
{}, isNoop
func
(
*
types.Header)
bool
) (
*
fetchRequest,
bool
,
error
) {
// Short circuit if the pool has been depleted, or if the peer's already
// downloading something (sanity check not to corrupt state)
if
taskQueue.
Empty
() {
return
nil
,
false
,
nil
}
if
_
,
ok
:=
pendPool[p.id]; ok {
return
nil
,
false
,
nil
}
// Calculate an upper limit on the items we might fetch (i.e. throttling)
space
:=
q.
resultSlots
(pendPool, donePool)
// Retrieve a batch of tasks, skipping previously failed ones
send
:=
make
([]
*
types.Header,
0
, count)
skip
:=
make
([]
*
types.Header,
0
)
progress
:=
false
for
proc
:=
0
; proc
<
space
&&
len
(send)
<
count
&&
!
taskQueue.
Empty
(); proc
++
{
header
:=
taskQueue.
PopItem
().(
*
types.Header)
hash
:=
header.
Hash
()
// If we're the first to request this task, initialise the result container
index
:=
int
(header.Number.
Int64
()
-
int64
(q.resultOffset))
if
index
>=
len
(q.resultCache)
||
index
<
0
{
common.
Report
(
"index allocation went beyond available resultCache space"
)
return
nil
,
false
, errInvalidChain
}
if
q.resultCache[index]
==
nil
{
components
:=
1
if
q.mode
==
FastSync {
components
=
2
}
q.resultCache[index] = &fetchResult{
Pending: components,
Hash: hash,
Header: header,
}
}
// Otherwise unless the peer is known not to have the data, add to the retrieve list
if
p.
Lacks
(hash) {
skip
=
append
(skip, header)
}
else
{
send = append(send, header)
}
}
if
progress {
// Wake WaitResults, resultCache was modified
q.active.Signal()
}
// Assemble and return the block download request
if
len
(send)
==
0
{
return
nil
, progress,
nil
}
request
:=
&
fetchRequest{
Peer: p,
Headers: send,
Time: time.
Now
(),
}
pendPool[p.id] = request
return
request, progress,
nil
}
Body数据填充点:
func
(q
*
queue)
DeliverBodies
(id
string
, txLists [][]
*
types.Transaction, uncleLists [][]
*
types.Header) (
int
,
error
) {
q.lock.
Lock
()
defer
q.lock.
Unlock
()
reconstruct
:=
func
(header
*
types.Header, index
int
, result
*
fetchResult)
error
{
if
types.
DeriveSha
(types.
Transactions
(txLists[index]))
!=
header.TxHash
||
types.
CalcUncleHash
(uncleLists[index])
!=
header.UncleHash {
return
errInvalidBody
}
result.Transactions = txLists[index]
result.Uncles
=
uncleLists[index]
return
nil
}
return
q.deliver
(id, q.blockTaskPool, q.blockTaskQueue, q.blockPendPool, q.blockDonePool, bodyReqTimer,
len
(txLists), reconstruct)
}
unc
(q
*
queue)
deliver
(id
string
, taskPool
map
[common.Hash]
*
types.Header, taskQueue
*
prque.Prque,
pendPool
map
[
string
]
*
fetchRequest, donePool
map
[common.Hash]
struct
{}, reqTimer metrics.Timer,
results
int
, reconstruct
func
(header
*
types.Header, index
int
, result
*
fetchResult)
error
) (
int
,
error
) {
// Short circuit if the data was never requested
request
:=
pendPool[id]
if
request
==
nil
{
return
0
, errNoFetchesPending
}
for
i
,
header
:=
range
request.Headers {
// Short circuit assembly if no more fetch results are found
if
i
>=
results {
break
}
// Reconstruct the next result if contents match up
index
:=
int
(header.Number.
Int64
()
-
int64
(q.resultOffset))
if
index
>=
len
(q.resultCache)
||
index
<
0
||
q.resultCache[index]
==
nil
{
failure
=
errInvalidChain
break
}
if err := reconstruct(header, i, q.resultCache[index]); err != nil {
failure
=
err
break
}
hash
:=
header.
Hash
()
donePool[hash] = struct{}{}
q.resultCache[index].Pending
--
useful
=
true
accepted
++
// Clean up a successful fetch
request.Headers[i]
=
nil
delete
(taskPool, hash)
}
// Return all failed or missing fetches to the queue
for
_
,
header
:=
range
request.Headers {
if
header
!=
nil
{
taskQueue.
Push
(header,
-
float32
(header.Number.
Uint64
()))
}
}
// Wake up WaitResults
if
accepted
>
0
{
q.active.Signal()
}
// If none of the data was good, it's a stale delivery
switch
{
case
failure
==
nil
||
failure
==
errInvalidChain:
return
accepted, failure
case
useful:
return
accepted, fmt.
Errorf
(
"partial failure: %v"
, failure)
default
:
return
accepted, errStaleDelivery
}
}
receipt数据填充点:
func
(q
*
queue)
DeliverReceipts
(id
string
, receiptList [][]
*
types.Receipt) (
int
,
error
) {
q.lock.
Lock
()
defer
q.lock.
Unlock
()
reconstruct
:=
func
(header
*
types.Header, index
int
, result
*
fetchResult)
error
{
if
types.
DeriveSha
(types.
Receipts
(receiptList[index]))
!=
header.ReceiptHash {
return
errInvalidReceipt
}
result.Receipts = receiptList[index]
return
nil
}
return
q.
deliver
(id, q.receiptTaskPool, q.receiptTaskQueue, q.receiptPendPool, q.receiptDonePool, receiptReqTimer,
len
(receiptList), reconstruct)
}
这里的deliver函数和上面一样
数据填充总结:
三个数据赋值到fetchResult的同时都会调用q.active.Signal
所以数据填充完后,q.active.Signal调用了三次。这个也是processFullSyncContent唤醒的条件
数据组装:
func
(d
*
Downloader)
processFullSyncContent
()
error
{
for
{
results
:=
d.queue.
Results
(
true
)
if
len
(results)
==
0
{
return
nil
}
if
d.chainInsertHook
!=
nil
{
d.
chainInsertHook
(results)
}
if
err
:=
d.importBlockResults
(results); err
!=
nil
{
return
err
}
}
}
func
(q
*
queue)
Results
(block
bool
) []
*
fetchResult {
q.lock.
Lock
()
defer
q.lock.
Unlock
()
// Count the number of items available for processing
nproc
:=
q.
countProcessableItems
()
for
nproc
==
0
&&
!
q.closed {
if
!
block {
return
nil
}
//等待,知道所有的fetch完成
q.active.
Wait
()
nproc
=
q.
countProcessableItems
()
}
// Since we have a batch limit, don't pull more into "dangling" memory
if
nproc
>
maxResultsProcess {
nproc
=
maxResultsProcess
}
results
:=
make
([]
*
fetchResult, nproc)
copy(results, q.resultCache[:nproc])
return
results
}
请注意上面的
q.active.
Wait
(),这个就是等待休眠点,前面的header, body, receipt数据填充时会调用q.active.Signal三次后,processFullSyncContent就会从这里继续执行。然后就从q.resultCache中拷贝数据并执行importBlockResults插入到主链
func
(d
*
Downloader)
importBlockResults
(results []
*
fetchResult)
error
{
blocks
:=
make
([]
*
types.Block,
len
(results))
for
i
,
result
:=
range
results {
blocks[i] = types.NewBlockWithHeader(result.Header).WithBody(result.Transactions, result.Uncles)
}
if index, err := d.blockchain.InsertChain(blocks); err != nil {
return
errInvalidChain
}
return
nil
}
/********************************
* 本文来自CSDN博主"爱踢门"
* 转载请标明出处
: http://blog.csdn.net/itleaks
******************************************/
