LSTM情感分类
这篇博客我主要介绍一情感分类的问题,比如我们拿到电影的影评,我们能快速区分是pos,还是neg,本文采用LSTM的网络框架,主要针对英文的评论进行分析。本文的代码,我是借鉴GitHub上的代码,这是我修改后的代码,可以直接用Python IDE跑起来,本文需要结合代码,博客更好的理解。
1.预处理
首先,我们先导入数据,在这里我们使用训练好的Glove,选用的是50维的向量,方便我们在自己的电脑上复现结果,那么我们拿到Glove矩阵之后,我们需要对我们的数据进行匹配,得到ID_Matrix,比方说:
import tensorflow as tf
maxSeqLength = 10 #Maximum length of sentence
numDimensions = 300 #Dimensions for each word vector
firstSentence = np.zeros((maxSeqLength), dtype='int32')
# print(firstSentence.shape)
firstSentence[0] = wordsList.index("i")
firstSentence[1] = wordsList.index("thought")
firstSentence[2] = wordsList.index("the")
firstSentence[3] = wordsList.index("movie")
firstSentence[4] = wordsList.index("was")
firstSentence[5] = wordsList.index("incredible")
firstSentence[6] = wordsList.index("and")
firstSentence[7] = wordsList.index("inspiring")
#firstSentence[8] and firstSentence[9] are going to be 0
print(firstSentence) #Shows the row index for each word
[ 41 804 201534 1005 15 7446 5 13767 0 0]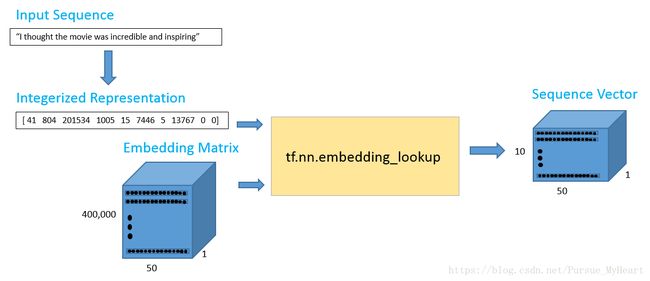
有了ID_Matrix,Glove向量矩阵,我们就导入我们的输入数据,根据输入数据单词,找到ID,找出序列向量(Sequence Vector)
在这里我们需要注意的是,我输入数据前我们需要对其预处理,因为数据当中包含一些特殊符号之类的,比如这一段话:
This film had a lot of promise, and the plot was relatively interesting, however the actors, director and editors seriously let this film down.
I feel bad for the writers, it could have been good. The acting is wooden, very few of the characters are believable.
Who ever edited this clearly just learnt some new edit techniques and wanted to splash them all over the film. There are lots of quick 'flashy' edits in almost every scene, which are clearly meant to be symbolic but just end up as annoying.
I wanted to like this film and expected there to be a decent resolution to the breakdown of equilibrium but alas no, it left me feeling like I'd wasted my time and the film makers had wasted their money.
import re
strip_special_chars = re.compile("[^A-Za-z0-9 ]+")
def cleanSentences(string):
string = string.lower().replace("
", " ")
return re.sub(strip_special_chars, "", string.lower())
firstFile = np.zeros((maxSeqLength), dtype='int32')
with open(fname) as f:
indexCounter = 0
line=f.readline()
cleanedLine = cleanSentences(line)
print(cleanedLine)
split = cleanedLine.split()
for word in split:
if indexCounter < maxSeqLength:
try:
firstFile[indexCounter] = wordsList.index(word)
except ValueError:
firstFile[indexCounter] = 399999 #Vector for unknown words
indexCounter = indexCounter + 1里面有
,其次我们在输入数据前还要确定一下SeqMaxLength,因为我们输入向量的时候必须要长度一致,否则不好进行比如矩阵相加的运算等,我们在这里设置SeqMaxLength=250
还有要生成batch,这里我们令batch_size = 24,生成测试集的batch代码:
def getTrainBatch():
labels = []
arr = np.zeros([batchSize, maxSeqLength])
for i in range(batchSize):
if (i % 2 == 0):
num = randint(1,11499)
labels.append([1,0])
else:
num = randint(13499,24999)
labels.append([0,1])
arr[i] = ids[num-1:num]
return arr, labels2.LSTM建模
做完上面的预处理之后,我们就可以对其建模,其中也包括保存模型
import tensorflow as tf
tf.reset_default_graph()
labels = tf.placeholder(tf.float32,[batchSize,numClasses])
input_data = tf.placeholder(tf.int32,[batchSize,maxSeqLength])
data = tf.Variable(tf.zeros([batchSize, maxSeqLength, numDimensions]),dtype=tf.float32)
data = tf.nn.embedding_lookup(wordVectors,input_data)
lstmCell = tf.contrib.rnn.BasicLSTMCell(lstmUnits)
lstmCell = tf.contrib.rnn.DropoutWrapper(cell=lstmCell,output_keep_prob = 0.75)
value,_ = tf.nn.dynamic_rnn(lstmCell,data,dtype=tf.float32)
weight = tf.Variable(tf.truncated_normal([lstmUnits,numClasses]))
bias = tf.Variable(tf.constant(0.1,shape=[numClasses]))
value = tf.transpose(value,[1,0,2])
last = tf.gather(value,int(value.get_shape()[0]-1))
prediction = (tf.matmul(last,weight)+bias)
correctPred = tf.equal(tf.arg_max(prediction,1),tf.arg_max(labels,1))
accuracy = tf.reduce_mean(tf.cast(correctPred,tf.float32))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=labels))
optimizer = tf.train.AdamOptimizer().minimize(loss)
保存模型
sess = tf.InteractiveSession()
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
for i in range(iterations):
#Next Batch of reviews
nextBatch, nextBatchLabels = getTrainBatch()
sess.run(optimizer, {input_data: nextBatch, labels: nextBatchLabels})
if (i % 1000 == 0 and i != 0):
save_path = saver.save(sess, "models/pretrained_lstm.ckpt", global_step=i)
print("saved to %s" % save_path)3.测试
接下来测试,我们可以输入一句话进行测试,判断是pos还是neg
import tensorflow as tf
tf.reset_default_graph()
labels = tf.placeholder(tf.float32, [batchSize, numClasses])
input_data = tf.placeholder(tf.int32, [batchSize, maxSeqLength])
data = tf.Variable(tf.zeros([batchSize, maxSeqLength, numDimensions]),dtype=tf.float32)
data = tf.nn.embedding_lookup(wordVectors,input_data)
lstmCell = tf.contrib.rnn.BasicLSTMCell(lstmUnits)
lstmCell = tf.contrib.rnn.DropoutWrapper(cell=lstmCell, output_keep_prob=0.25)
value, _ = tf.nn.dynamic_rnn(lstmCell, data, dtype=tf.float32)
weight = tf.Variable(tf.truncated_normal([lstmUnits, numClasses]))
bias = tf.Variable(tf.constant(0.1, shape=[numClasses]))
value = tf.transpose(value, [1, 0, 2])
last = tf.gather(value, int(value.get_shape()[0]) - 1)
prediction = (tf.matmul(last, weight) + bias)
correctPred = tf.equal(tf.argmax(prediction,1), tf.argmax(labels,1))
accuracy = tf.reduce_mean(tf.cast(correctPred, tf.float32))
print("completely!")
sess = tf.InteractiveSession()
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint('./models'))
# Removes punctuation, parentheses, question marks, etc., and leaves only alphanumeric characters
inputText = "That movie was terrible."
inputMatrix = getSentenceMatrix(inputText)
predictedSentiment = sess.run(prediction, {input_data: inputMatrix})[0]
# predictedSentiment[0] represents output score for positive sentiment
# predictedSentiment[1] represents output score for negative sentiment
if (predictedSentiment[0] > predictedSentiment[1]):
print ("Positive Sentiment")
else:
print ("Negative Sentiment")
secondInputText = "That movie was the best one I have ever seen."
secondInputMatrix = getSentenceMatrix(secondInputText)
predictedSentiment = sess.run(prediction, {input_data: secondInputMatrix})[0]
if (predictedSentiment[0] > predictedSentiment[1]):
print("Positive Sentiment")
else:
print ("Negative Sentiment")
