阿里云单盘百万IOPS的背后
本文组织:
单盘100万IOPS意味着?
背后的技术猛料!
性能这么高,安全性有保障么?
笑对Intel漏洞?
存储界已三足鼎立?
2018年1月9日,阿里云在北京隆重发布了如下产品和技术:


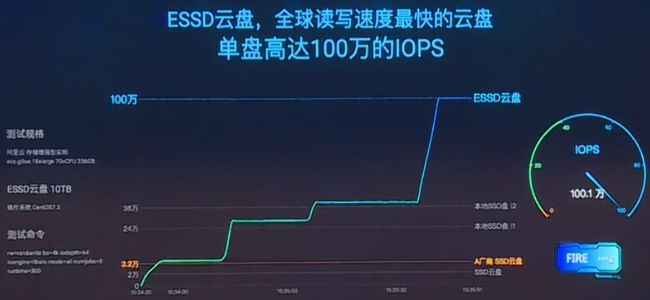
其中,ESSD是块存储服务,其达到了恐怖的单盘100万IOPS的峰值。阿里云现场演示了对一个10TB容量的ESSD块盘加I/O压力,然后轻易超越了友商、本地SSD盘的性能,最后直冲到了100万IOPS。另外,阿里云研究员伯瑜现场指出:100万IOPS,读和写均可达到。这一条很劲爆,作为NAND Flash介质,读性能比写性能可能要高六七倍以上。而阿里云竟然可以做到写也100万IOPS。
在为何测试时性能吊炸天而上线却惨不忍睹?一文中,冬瓜哥指出,不谈时延的IOPS都是耍流氓。而阿里云本次发布的ESSD在100万IOPS情况下平均延迟500us,50万IOPS情况下平均延迟100us。这个值已经超越了目前的SAN/全闪存厂商能够提供的最佳值。
另外,对于大并发高压力的互联网前端业务而言,除了关注IOPS和时延之外,另一个非常重要的指标就是抖动,因为一次抖动可能会导致系统的连锁反应,重则崩溃。阿里云很有信心的将一个测试系统的实时延迟值展示到了网络上,可以扫描下面的二维码直接查看。

可以发现,去年发布的NAS Plus的性能也获得了极大提升,同时提升的还有极速OSS对象存储。
阿里云研究员吴结生表示,在存储界,一些厂商的产品其实也可以达到类似性能,但是他们都使用了本地盘加高速本地总线。能够在数据中心规模内部以云服务方式达到这种性能的,目前只有阿里云能够做到。
很显然,这种恐怖性能的背后,一定产生了一场大规模的后端技术、架构的升级、变革。
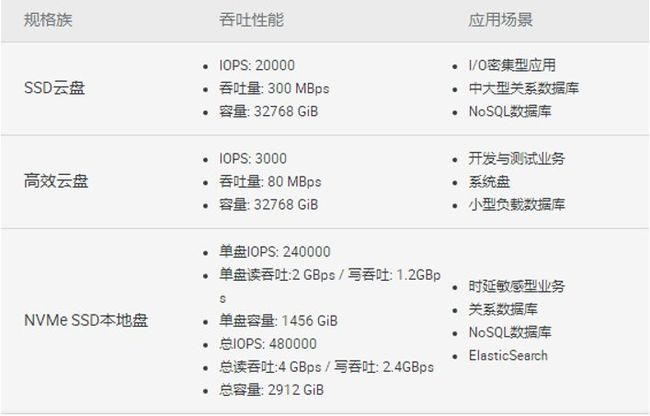
ESSD单盘容量最大可到256TB,而之前SSD云盘则为32TB。而且,加量不加价,仍然是每GB 1块钱。阿里云研究员伯瑜指出,现在有不少用户对大容量、高性能的单盘有需求,比如一些做Elastic Search的用户,要求几十TB以上容量的单盘,同时性能要求几十万IOPS,在ESSD推出之前,这类需求只能用本地盘来弥补,但是安全性就没有保障了。
单盘100万IOPS意味着:
相比上一代SSD云盘,峰值性能直接翻50倍!
相比上一代NVMe本地盘,峰值性能直接翻4倍!
一盘在手,打遍各类业务无敌手。无需再用多块盘组软raid,lvm等。
省钱!
别家真是没法玩了。
冬瓜哥有幸与阿里云存储的两位资深研究员Jason(吴结生)和伯瑜进行了交流,也了解到了阿里云存储本次性能飙升背后的猛料。
1. 硬件升级。除了服务器、SSD等基础规格升级之外,这里面最关键的其实是网络上的升级。目前阿里云VM上的云盘(本地盘)统一走的是以太网访问后端的盘古分布式存储平台上提供的各种存储资源。一百万IOPS@4KB,对网络的带宽耗费为40Gb/s,再加上开销,需要至少50Gb的带宽才能达到。阿里云存储引擎2.0采用了25Gb/s以太网,提升了带宽密度。另外,采用了全自研交换芯片和交换机,针对RDMA协议做了芯片级优化,能够让跨交换机端到端通信时延降低到2微秒(4KB+128B ack round robin时延)。
2. Luna通信库框架。有了强力网络硬件的支撑,软件的开销会成为优化的重中之重。在固态存储时代,传统较长的I/O路径已经严重拖累了I/O时延,对于NVMe SSD而言,由于NVMe协议栈原生已经为我们开凿好了高并发的通路,那么,降时延就是升IOPS的唯一途径了。阿里云存储2.0引擎在后端采用了SPDK框架来与NVMe SSD交互,采用用户态驱动,多队列自适应Polling模式。在前端,采用私有的I/O协议+RDMA+用户态驱动方式来转发前端I/O请求到后端盘古系统上。这一整套的通信库框架被称为鲲鹏。SPDK是Intel搞的一套用户态I/O栈,但是根据业界一些存储厂商的反馈,其中坑很多,性能也有待优化。阿里云研究员伯瑜指出,SPDK库已经在阿里实施了2年多,对它已经是驾轻就熟,该踩的坑也基本踩完了,而且阿里云应该是第一家将SPDK广泛使用的。研究员吴结生提到,鲲鹏库的诞生为阿里云存储的开发效率和性能这两个矛盾点找到了一个很好的平衡。
3. 线程模型改进。阿里云存储2.0引擎采用了用户态驱动,加co-routine协程,加run to completion模式。用户态驱动可以避免每次发送I/O都必须经历系统调用到内核来处理的性能损失。在用户态上实现协程,把内核的线程调度开销进一步降低,协程之间自主实现用户态上下文切换,和自主调度切换,这一切内核根本感知不到,这样可以在有限的线程运行时间片内全速的以非常低的切换开销执行多个协程。再加上内核可感知的多个用户线程并发充分利用处理器物理多核心,实现充分的并发。协程的另外一个关键点是其可以避免使用锁,因为多个协程运行在单个核心上,全串行无并发,靠上层逻辑实现手动同步。另外,采用run to completion线程模型,避免I/O路径上太多的异步耦合点,后者会带来较高的长尾效应,导致I/O时延不稳定。可参考冬瓜哥另一片文章:【冬瓜哥手绘】它保你上线性能也吊炸天!
4. 数据布局Append Only。对付随机写入的最好的办法就是append only模式,将所有写操作顺序记录写入,然后修改指针,这一招对SSD屡试不爽,实际上SSD内部也是这么做的。阿里云存储后台也采用这种方式。之前只对对象存储OSS和表格存储TableStore等做这种策略,阿里云存储2.0引擎下针对块存储也采用了该策略。
5.vhost-user架构。采用vhost-userI/O架构,bypass QEMU的virtio-blk架构,将IO dataplane从QEMU卸载下来,即IO请求的生命周期完全bypass QEMU。
6. 更细致的分层和抽象。在后台盘古系统中的单机内部,做了更细致的分层和抽象。在上层,针对不同的I/O属性,提供了定制化的策略模块,满足不同的I/O Profile需求。
抛开安全性谈性能就是空中楼阁。阿里云后台采用3副本同步写方式,能够保证9个9的可靠性。对象存储OSS的数据3副本放置在3个AZ里面,保证11个9的数据可靠性。块存储的数据由于三副本同步复制,所以对延迟非常敏感,会放置到1个AZ内部。
对于SSD/ESSD云盘,所有写到后台的数据是直接下盘,并非到RAM,正因如此才会加持到9个9的可靠性。
阿里云后台支持对数据做快照,快照生成的数据会被导出到OSS存储上作为备份而存在,这份备份会拥有更高的可容灾性,因为会与块存储位于不同的AZ。
吴结生研究员表示,由于目前阿里云提供了诸多不同档位的存储服务,下一步会实现自动迁移,当用户决定将当前服务提级或者降级时,目前是只能靠用户自己来迁移,不过可以通过导入快照方式来方便的实现。将来会实现系统后台自动迁移数据。 这样的话,会给用户带来更多的方便试错的机会。
目前阿里云正在使用机器学习方式对用户的底层I/O做学习分析,将来会做到智能推荐。

支持端到端的数据校验。支持加密。
在数据中心建设方面,阿里云有一套独特的经验和方法论。在AZ的设计上非常考究,包括供电、网络运营商,不同数据中心/AZ都是独立的不同供应商,不会用同一个供应商,以避免单点故障。甚至连地势也会考虑,比如高度差异,防止洪水淹没位于同样地势高度的数据中心。还会考虑链路途径化工厂引入的不稳定因素等。
聊到Intel本次的Meltdown和Spectre漏洞,伯瑜研究员笑道,其实这次漏洞的影响恰好说明了,阿里云引擎2.0采用的用户态驱动和I/O协议栈模式,能够天然抗拒新的OS补丁对性能产生的影响,也就是说,新补丁对性能几乎没有影响,因为发送I/O的工作都是直接在用户态做的,不牵扯到系统调用,否则,本次补丁还真有可能大幅降低系统性能。

本次,阿里云还发布了一个叫做CPFS的并行文件系统的服务,该FS是专门针对云上HPC系统推出的,其能够兼容Luster的访问接口,在HPC场景下能够提供相比NAS产品更好的扩展性和对HPC环境的兼容性。
阿里云存储产品总监承宗指出,得益于阿里云存储引擎2.0的发布,OSS和NAS Plus也推出了极速版本。其可以直接为用户带来投资上的节省,比如之前有一些应用必须采用大容量内存,而现在OSS推出了极速版,这些应用可以在同样的业务需求下,降低对内存的需求量,从而直接降低成本。
传统存储SAN/NAS,本地分布式存储,云端存储,如今已经进入了三足鼎立时代。螳螂捕蝉黄雀在后,随着分布式新兴存储系统对传统SAN/NAS存储的冲击,后方云存储又开始大肆强攻,到底应不应该把数据放到云上,这似乎已经不再是一个技术问题了。
