Diversity Regularized Spatiotemporal Attention for Video-based Person Re-identification
一、介绍
大多现存的解决视频行人重识别问题的方法是把每一帧编码成一个向量,然后对所有的帧向量进行聚合得到视频序列的特征嵌入。在实践中,行人经常被部分遮挡,这样就破坏了提取的特征。作者提出了一个新的时空注意力模型,能够自动地学习视频序列中行人特定部分(如面部、躯干、包等)。作者的模型能够很好地对抗遮挡和不对齐,有效提取所有帧中的有用信息。作者的网络学习了多个空间部分注意力模型,同时采用了一个多样性正则化项来确保多个部分注意力模型关注身体的不同部分。总结来说,视频序列的特征嵌入通过空间注意力模型生成,通过时间注意力机制结合。结果表明,作者的网络能够自动地使用视频序列中条件最好的帧中的patch学到面部、躯干以及身体其他部分的特征。进一步的实验证明,作者的网络以很大的优势超过了state fo the art。
作者的贡献如下:
- 空间注意力明确地解决了帧间的对齐问题,避免了遮挡破坏提取的特征
- 除了身体的各个部分,眼镜、背包、帽子等附件对重识别也是很有用的。作者无监督的空间注意力模型使得网络能够自动地发现这些判别目标
- 基于Hellinger distance,作者提出了一个新颖的多样性正则项,保证了多个空间注意力模型关注的身体部位不重叠
- 作者使用了时域注意力模型来聚合每个空间注意力模型提取的特征集。各个空间注意力模型提取的特征连接在一起组成视频序列的特征
二 、作者的方法
2.1 网络结构

网络结构如上图,对于一个视频序列,首先通过一个有限制的采样策略来选择N个视频帧。然后将视频帧集合每张图经过预训练的ResNet50得到Nx2048x8x4的特征图。将特征图送入多区域空间注意力模块得到多个关注不同部位的特征集。然后将不同视频帧同一个部位的特征经过时域注意力模块在时域上进行聚合得到一个部位的一个向量表示。多个部位得到的多个向量连接后经过一个fc降维后作为视频序列的特征,训练阶段使用OIM loss来训练。
2.2 采样策略
将视频平均分成N个片段,每个片段随机选取一帧(能够关注到视频中随时间行人的变化,同时很好地避免冗余)。
2.3 多空间注意力模型
将N张图片送入预训练的ResNet50(使用conv1~res5c)得到Nx2048x8x4的特征图。为了便于理解,下面用一帧来解释,对于每张图,看作有32个2048维的空间特征![]() ,其中L=32。对于每个空间注意力模块(共K=6个),将2048x32的空间特征图经过一个d个神经元的fc+ReLU降维(D=2048,d=256)得到dx32,然后再经过一个神经元的fc得到1x32=32个e_(n,k,l),这一过程用数学表达式如下:
,其中L=32。对于每个空间注意力模块(共K=6个),将2048x32的空间特征图经过一个d个神经元的fc+ReLU降维(D=2048,d=256)得到dx32,然后再经过一个神经元的fc得到1x32=32个e_(n,k,l),这一过程用数学表达式如下:
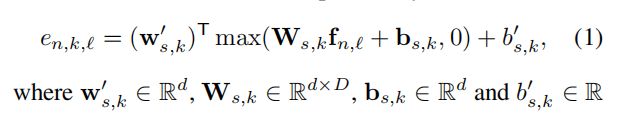
然后将一张图32个空间向量 scores经过下面的softmax得到32个空间向量的权重。每个空间向量权重表示为Sn,k,l 表示第n帧、第k个空间注意力模块、第l个空间向量的权重。Sn,k成为第k个空间注意力模块的感受野。

然后根据L个权重对L个空间特征进行加权求和(如下式),得到了第n帧、第k个空间注意力模块的特征Xn,k (the spatial gated feature)
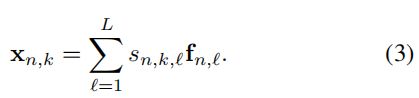
作者还使用了一个增强函数(下式),才补充材料中有说明,因为我看的论文没有补充材料,所以不是很理解,先放在下面:
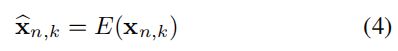
这样我们就得到了视频序列的NxKxD的空间注意力输出图。
2.4 多样性正则化
作者指出,如果不提供约束,仅仅用一个OIM损失(类似于Softmax损失),会导致模型退化,使得多个空间注意力模型结果检测人体相同的部位。为了提供约束使其关注不同的部位,考虑到每个空间注意力模块的感受野Sn,k具有概率解释(Softmax将其映射到0-1之间),作者指出直观地想到可以优化KL散度使不同集合概率分布不同:

但是 作者指出Sn,k大部分元素都是近0的,在KL散度计算中经过log(.)运算后变化非常大,训练不稳定,作者没有采用这一方法。
作者提出了一个函数H来测量两个感受野Sn,i和Sn,j间的重叠程度:
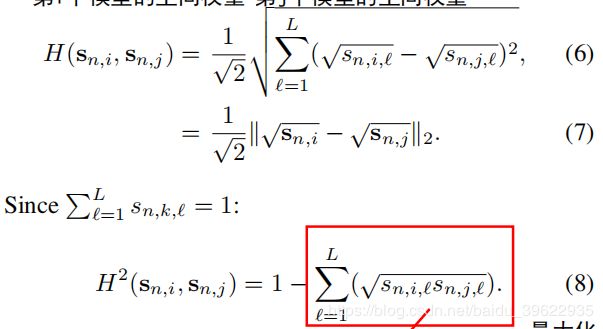
显然,H不小于0,H越大两个感受野重叠程度越小。所以等价于优化H^2的最大值(8)式,又等价于优化矩形框中表达式的最小值。用![]() 表示,则矩形框表达式等价于(9)式:
表示,则矩形框表达式等价于(9)式:
![]()
其中|| . ||_F为弗罗贝尼乌斯范数(F范数),为矩阵各元素平方之和。
这样,作者把Q作为正则项加上一个权重alpha放入损失函数中,称Q为多样性正则项。
在文本嵌入任务中,有(10)式很常见的正则项:
![]()
两者看起来很相似,但是作者指出Q是基于![]() 但是Q’在任何矩阵上都能用;Q‘使矩阵倾向于使S只在对角线有值,Q ’保证不重叠的同时使注意力集中在单个空间特征上,而Q在保证不重叠的同时使注意力可以关注在例如上半身这种大的空间特征。所以两者有很大的差别,作者后面设置了Q和Q‘的对比实验。
但是Q’在任何矩阵上都能用;Q‘使矩阵倾向于使S只在对角线有值,Q ’保证不重叠的同时使注意力集中在单个空间特征上,而Q在保证不重叠的同时使注意力可以关注在例如上半身这种大的空间特征。所以两者有很大的差别,作者后面设置了Q和Q‘的对比实验。
2.5 时域注意力
为了关注到更多细粒度的信息,作者没有采用每帧一个权重的聚合方法,而是采用了NxK个权重、每帧视频的每个空间感受野一个单独权重的时域注意力方法。具体实现上,将NxKxD特征图经过一个神经元的fc得到NxK的scores,然后再在时域N上Softmax得到NxK的时域权重。t_n,k表示对于第k个空间注意力模块,第n帧感受野特征的权重。
![]()

然后按照(13)式进行加权求和得到对于视频序列,第k个空间感受野的特征。
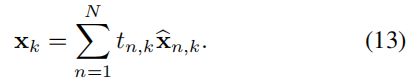
(Xk总的产生过程如下:

即空间特征先后经过空间、时间注意力加权得到。 )
最后,K个特征连接在一起,组成视频序列的特征:
![]()
2.6 损失函数
OIM loss使用一个存储了之前训练集中所有行人特征的查找表,在前向过程中,每个batch中的样本利用了之前所有行人特征计算分类可能性。OIM loss被证明在行人重识别任务中比Softmax loss更有效(得读读这篇论文)。
三、实施细节
- 每个视频等长分成N = 6 chunks
- CNN使用ResNet50,现在图片行人重识别数据集上预训练,包括CUHK01、CUHK03、3DPeS、VIPeR、DukeMTMC-reID、CUHK-SYSU,然后在PRID2011、iLIDS-VID、MARS上fine tune。训练完成后,固定CNN的参数。然后使用时域平均池化和OIM loss训练多个空间注意力模型。最后,整个网络(包含了时域注意力模块)在一起训练(CNN不更新权重)
- 输入图片256x128,网络使用SGD优化,初始学习率0.1然后变成0.01
- 聚合的空间注意力特征经过一个fc降维到128维,然后进行了L2-norm,来表示整个视频
- 训练阶段采用了上文介绍的采样方式,在测试阶段使用N个片段的第一张图片(不明白为什么这样做)
- PRID2011、iLIDS-VID数据集使用Rank-1,而Mars使用Rank-1和mAP
四、实验结果

成分分析如上图,Baseline是指相同的训练方式,但是仅使用ResNet50,提取各帧特征后时域上平均池化,再经过128fc+OIM loss.SapAtn是使用了多空间注意力模型+时域平均池化+128fc+OIM loss。SpaAtn+Q'和 SpaAtn+Q是在SpaAtn的基础上加了多样性正则项。SpaAtn+Q+MaxPool是将时域平均池化变成时域最大池化。SpaAtn+Q+TemAtn使用了时域注意力模块。SpaAtn+Q+TemAtn+Ind是作者的方法,SpaAtn+Q+TemAtn的基础上最后在相应的测试数据集上进行了fine tune。
- Baseline和SapAtn对比,说明作者的多空间注意力模型能够学到行人身体上有助于判别的信息。
- SpaAtn和SpaAtn+Q'以及SpaAtn+Q对比,说明了多样性正则项能够很好地促进多空间注意力模型
- SpaAtn+Q'以及SpaAtn+Q对比,证明了作者提出的基于F-距离的正则项Q相比于文本嵌入中常用的正则项Q的有效性,作者认为效果更好的原因是Q使得网络能够学到更大且不重叠的区域
- SpaAtn+Q和SpaAtn+Q+MaxPool和SpaAtn+Q+TemAtn的对比,证明了作者时域注意力模块的有效性(大概提升1%)
- SpaAtn+Q+TemAtn+Ind说明,最后整个网络在视频数据集上fine tune后,效果最好

表2说明,k=6即训练6个空间注意力模型效果最好。作者还通过实验发现,对于人体,分成2个空间注意力区域反而不如1个。
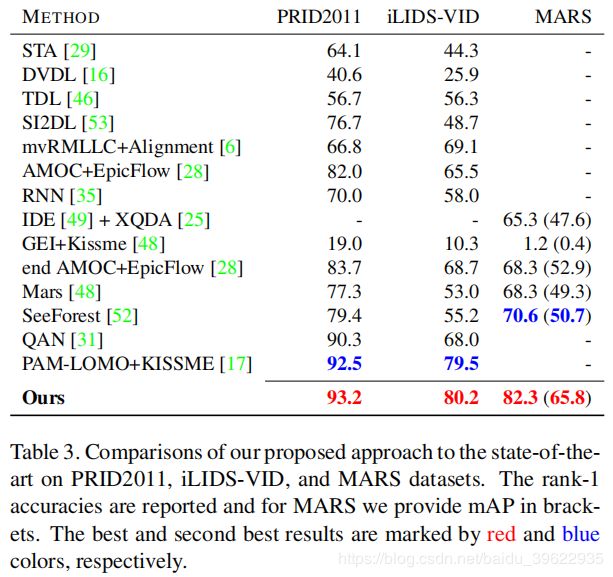
表3是和state of the art的对比,结果说明作者的方法在三个数据集上都超过了state of the art,其中在MARS数据集上提升最大,有11%的提升,说明作者的方法很适合场景较复杂的视频行人重识别问题(MARS有很多distractors)。

多空间注意力模型的可视化结果,可以看到,作者的方法能够关注到大的且不重叠的对判别有利的区域。
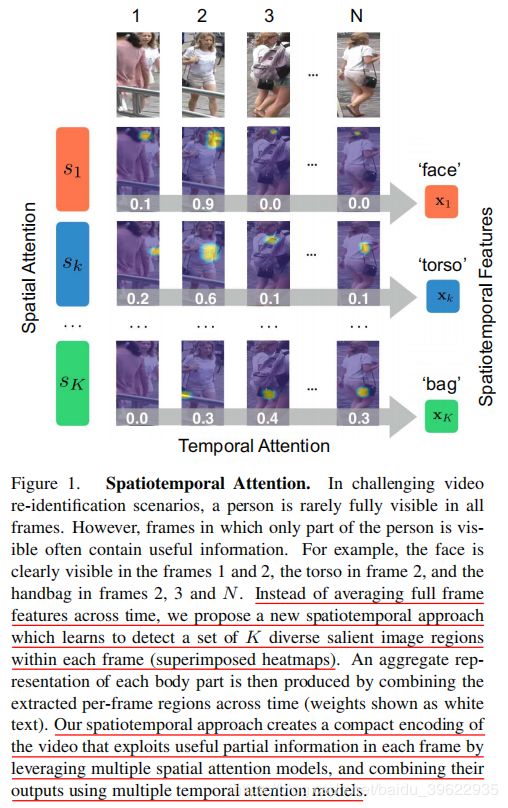
时域注意力的可视化结果,可以看到,作者的时域注意力相比于平庸化的时域平均,能够有选择地关注到无遮挡空间注意力区域。比如对于注意面部的空间注意力模型S1,经过时域注意力模块后能够重点关注第1、2帧人脸比较清晰的图像。而后对于面部信息不太好的后两张,则不关注。