CNN入门实战:我如何把准确率从86% 提高到99%(上)
首发于专栏:知乎专栏:https://zhuanlan.zhihu.com/p/43679939
个人公众号:follow_bobo
---------------------分割线--------------------------------------
哈哈哈,想不到我也能写如此标题党的文章
这个逼装的我
竟然有种坑蒙拐骗的感觉
让我想起来以前看到的《震惊,我是怎么用10块钱赚到1000万的!》
哈哈哈
麻烦大家点个赞,就是那种,假装我写得很好的那种样子
---------------------分割线--------------------------------------
今天我给大家讲一个实例,也就是实际工程中,我是如何一步一步分析数据,从而使我的输出结果能够顺利满足客户要求
首先我们要明白一点,这是工程项目,不是科研项目
AI的科研项目更多关注于局部问题,也是在一个点上进行突破,来证明自己算法的先进性
但是AI工程项目是,只要能落地,管他什么单枪棍棒,意大利炮都给我上
我们来看看下一幅图,很好的阐释了DL 算法和工业应用的区别
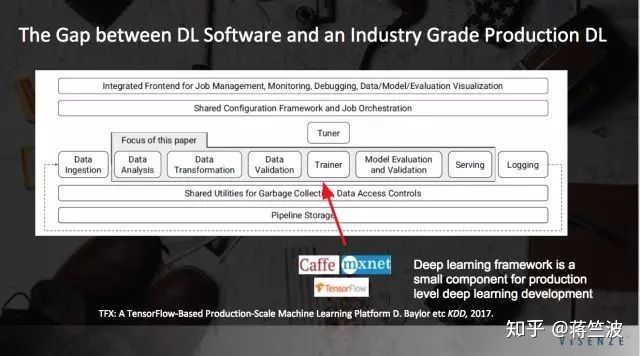
也就是说我们平时所常用的,或者研究的CNN模型(也就是上面的trainer),只是整个工程Pipeline 的一部分,要想项目落地,其实需要一个非常复杂的流程,远比上图介绍的复杂
那么今天,我就来介绍一个简单的工程项目
重点不讨论技术细节,重点在于是如何对数据进行分析处理的
数据就别问我要了,是不可能给的
-----------------------------------分割线------------------------------------------------
Step 1 : 展示数据
我要介绍的是一个AI医疗的项目,所用的数据是超声波心电图(Echocardiogram)
目的是给超声波心电图做分类,以达到帮助医生快速选择要检测的心电图类别
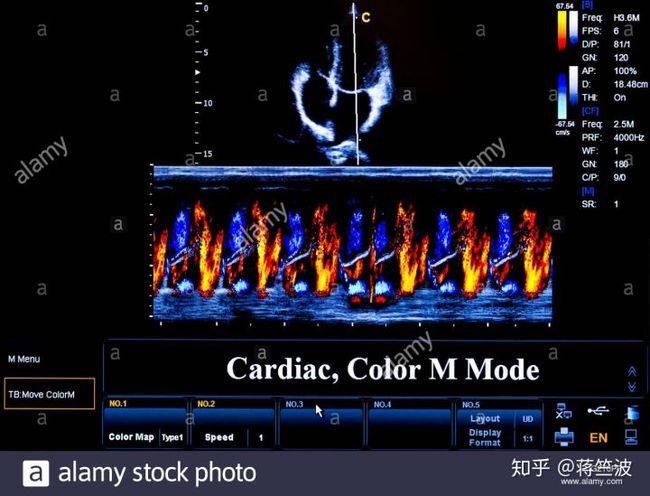
超声波心电图(图片来源于网络)
我想小伙伴们应该和我一样,当我看到这个图像数据是完全懵逼了
因为我的训练和测试数据完全就像上图所示,对于一个非医学专业来说,没法对图片进行理解
但这影响一个AI工程师进行训练和测试模型吗,哈哈,不影响的
反正Deep Learning 模型都是end to end, 我理解不来,模型能理解就行
毕竟谁还不会跑个模型,调个参?
我先来简单分析一下目前的数据情况:
- 目标类别一共20类,每类数量400-50不等
- 数据形式比较统一(都是超声波图和多普勒图),背景比较单一(都是黑色),图片质量参差不齐,很多情况下图片包含大量噪声
以上就是我看到数据的第一印象,但是这不影响我拿过来就是一顿train
我没有对现有数据进行任何调整的情况下,考虑到数据量少,于是我使用VGG19-pretrain模型,只fine-tune 最后VGG19一层,最后分类准确率为86%
刚开始,我看到这个结果是比较满意的
因为在没有对数据进行任何处理的情况下,分类准确率为86%,至少证明一点,这个项目是可行的,是有希望把它做好
在此之前,大家对数据都不了解,谁也无法保证这个项目能不能成功
Step 2 : 选择更好的Deep Learning模型
上面提到过,我使用的DL 模型是 VGG19,目的是为了证明项目的可行性,相当于建立一个Baseline
随后,我保持其他条件不变,遍历目前所有主流CNN模型,下面提供了代码:
https://zhuanlan.zhihu.com/p/37724444
遍历完事后,最后结果是Densenet201表现最好,达到了90%,其次是Dense169,dpn92, 都89%
你们看,一天的功夫,仅仅遍历一遍主流模型,我们已经达到了90%的分类准确
简直可喜可贺,可口可乐

但是还是离我们的目标差了十万八千里
因为这是医疗用途,医疗必须谨慎谨慎再谨慎
因此,我们一个落地的基本目标是
在保证速度的情况下,分类准确率至少在98%以上
这是一个看似简单,但是极其复杂的问题,因为越往上走,提升准确率越难
Step 3 :调参,修改模型
说是调参,实际上就是在进行一个大量的尝试的过程:
修改优化器的种类
修改学习率(learning rate)
冰冻(Freeze)某些层,不让它更新参数
使不一样的网络层有不一样学习率
修改pooling层
修改Batch Normalization 层
修改全连接层
改变输入数据的格式和大小
修改Loss function
。。。。。。。。
。。。。。。。。
因为没有对数据进行深度研究过,只能拿别的调参方法用来这个数据集上瞎试咯

效果嘛,其实也就是好一丢丢,运气好的话,能有91%的分类准确率

你可能会问我,为什么一直在模型上下功夫
因为这个医疗数据,我每次看都头大,不想研究它
为了能在每周汇报上有进展,我都会先在模型上解决一部分问题
Step 4 : 回到数据
通过我们和医生的详细讨论之后,我们发现,首先医生做分类,是通过一个整体部分来检查的:
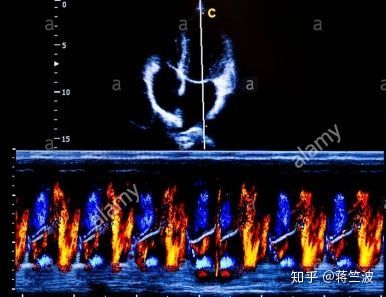
我们把上图从原图中切出来,相当于去掉了一点噪声背景
这个数据图像其实由两部分组成:上面超声波图像,下面多普勒图像

超声波

多普勒
假设超声波label为A,多普勒label为B, 最后医生最终的label 就是A+B
但是医生更看重B的分类结果
并且 A 和 B是 有一定联系的
大概知道了数据的含义后,这样我们就可以针对性的做一个模型
接下来,我们先将A , B单独抠出来
其实这一步非常麻烦,因为数据质量样式参差不齐,很多情况下抠出来的效果如下:
失败的抠图1

失败的抠图2
ok, 假设我们已经把A,B都完整抠出来了,你们想想应该怎么做
那边玩手机的同学,麻烦把手机关了
其实模型也很简单
把这个问题做成一个多输入多输出问题就好
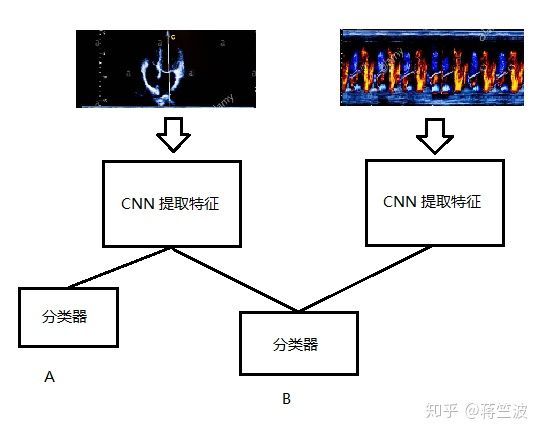
这个时候,我们对A的分类器的Loss 设置了一权值为0.8的系数
我们希望B作为主输出,A作为副输出
想了解更多的同学,可以移步:
https://keras.io/getting-started/functional-api-guide/keras.io
你们猜猜,这个简单的网络
把我最后的分类准确率提高到了多少?

下期见
拜了个拜