SSD-tensorflow 单类目标的检测
最近一段时间主要是做目标检测的任务,在没接触DL之前,受到目标图像尺度、特征不明显等影响传统方法效果并不是很好。
一、跑通SSD-tensorflow Demo
这一步基本都可以复现,主要参考了参照github上 balancap 的过程:
https://github.com/balancap/SSD-Tensorflow
中文翻译 https://blog.csdn.net/yexiaogu1104/article/details/77415990
二、实现单类目标的检测
跑通了上一步 该怎么做呢,Demo中实现了20类 的目标检测,但因需要,我只训练检测行人。
1、准备数据
(1)、提取原voc数据集里含有人的 xml 和 imge
参考网友的根据自己的目录修改(我的目录有点长,认真看)
bash xxx.sh
#!bin/sh
year="VOC2007"
# mkdir ...where to store
#mkdir .././datasets/test2/test1/
mkdir .././datasets/VOCperson/${year}_Anno/
mkdir .././datasets/VOCperson/${year}_Image/
cd .././datasets/VOCtrainval_06-Nov-2007/VOCdevkit/VOC2007/Annotations/
grep -H -R "person " > /media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/temp.txt #找到有关键字的行,并把这些行存到临时文档
#grep -H -R "person " > temp.txt #找到有关键字的行,并把这些行存到临时文档
cd /media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson
cat temp.txt | sort | uniq > $year.txt #根据名字排序,并把相邻的内容完全一样的多余行删除。
find -name $year.txt | xargs perl -pi -e 's|.xml:\t\tperson ||g' #把文档中后缀名和其他无用信息删掉,只保留没后缀名的文件名
cat $year.txt | xargs -i cp /media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCtrainval_06-Nov-2007/VOCdevkit/VOC2007/Annotations/{}.xml /media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/${year}_Anno/
cat $year.txt | xargs -i cp /media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCtrainval_06-Nov-2007/VOCdevkit/VOC2007/JPEGImages/{}.jpg /media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/${year}_Image/
rm temp.txt这样就得到了含有人的 imge和相应的xml文件,如下

(2)、修改xml 文件
由于提取的xml文件中可能还有其他物体的 object 信息,需要进一步去除
bash xxx.sh
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 31 10:03:03 2017
@author: hans
"""
import os
import xml.etree.ElementTree as ET
origin_ann_dir = 'Annotations_old/'
new_ann_dir = 'Annotations/'
for dirpaths, dirnames, filenames in os.walk(origin_ann_dir):
for filename in filenames:
if os.path.isfile(r'%s%s' %(origin_ann_dir, filename)):
origin_ann_path = os.path.join(r'%s%s' %(origin_ann_dir, filename))
new_ann_path = os.path.join(r'%s%s' %(new_ann_dir, filename))
tree = ET.parse(origin_ann_path)
root = tree.getroot()
for object in root.findall('object'):
name = str(object.find('name').text)
if not (name == "person"): #去除 不是 person的 object
root.remove(object)
tree.write(new_ann_path)
(3)、训练集、测试集 划分
通过修改自己的相关目录,注意这里是 运行 .py 文件 ,
import os
import random
xmlfilepath=r'/media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/VOC2007_Anno'
saveBasePath=r"/media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson"
trainval_percent=0.8
train_percent=0.7
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub size",tr)
ftrainval = open(os.path.join(saveBasePath,'/media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/ImageSets/Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'/media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/ImageSets/Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'/media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/ImageSets/Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'/media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/ImageSets/Main/val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close() (4)、转 tfrecord
这一步没有太多修改,没多大问题
三、训练网络(fine-tune)
(1)修改 pascalvoc_common.py文件
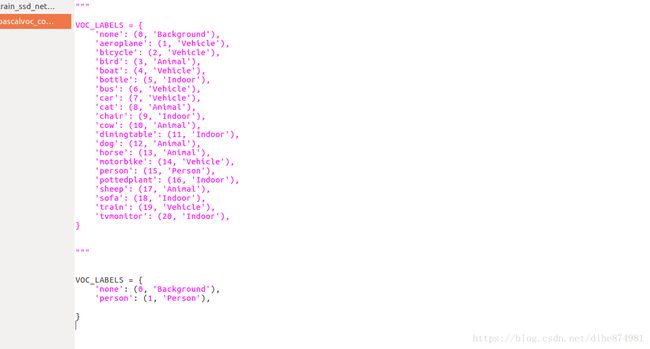
(2)注意这里是微调的,才开始搞的时候我把 CHECKPOINT_PATH 注释了,直接导致 loss 30~50 ,训练出来的模型也识别不出任何结果。(困了 好几天,呵呵)。用VGG-16 模型进行训练效果也同样(参数有问题?)
set files are stored.
DATASET_DIR=/media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/datasets/VOCperson/tfrecord/
#../../../../common/dataset/VOC2007/VOCtrainval_06-Nov-2007/VOCdevkit/VOC2007_tfrecord/
#Directory where checkpoints and event logs are written to.
TRAIN_DIR=.././log_files/log_person/
#The path to a checkpoint from which to fine-tune
CHECKPOINT_PATH=/media/xd/000398040009E3B2/txh_ubuntu/hands_on_ml/SSD-Tensorflow-master/checkpoints/VGG_VOC0712_SSD_300x300_iter_120000/VGG_VOC0712_SSD_300x300_iter_120000.ckpt
python3 ../train_ssd_network.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--batch_size=32 \ 最后,上张效果图(有点不理想),调参、调参

四、遥感图像检测
见下一篇中 要 解决高分辨率遥感图像检测中图像太大检测不出来的问题
,也就是把图像放大后再截取图像又可以重新检测出来了。