Inceptionv3 : Rethinking the Inception Architecture for Computer Vision 笔记
目录
简介
摘要
常用的卷积网络设计准则
分解大尺寸卷积核
辅助分类器(Auxiliary Classifiers)的实用性
有效降低feature map 大小
网络结构
通过标签平滑(Label Smoothing) 实现模型正则化
在低分辨率输入上的表现
实验结果与对比
结论
简介:
GoogleNet为2014年ILSVRC大赛冠军网络,使用inception模型,inception有v1-v4四个逐步演进和优化的version,本文是以inception v3为对象,结合设计深度网络的几个principle分析 inception结构及其合理性。
论文链接
摘要:
自2014年以来,very deep的神经网络逐步成为主流(注意到在VGG论文中也有提到,在数据集足够的情况下,增加网络深度和宽度很多时候可以取得更好的效果,学习更复杂的特征),但是在当今移动互联网和大数据的时代,提高计算效率和降低参数数量依旧是很多场景下的诉求),本文旨在探究通过分解卷积核和利用有效的正则化提高计算效率的方式。
VGG网络与GoogleNet的比较:
VGG的优点:网络结构更简单,可修改性也强
VGG的缺点:参数有138m之多,对计算资源的需要很大
GoogleNet的优点:参数少,只有5m,且准确率相当高(毕竟冠军网络)
GoogleNet的缺点: 网络复杂度高,很难调整网络结构适应不同场景
常用的设计准则:
1.避免表达的瓶颈(representational bottlenecks),表达的尺寸(即feature map的大小)(尤其是在浅层网络中)不应该出现急剧的衰减,如果对流经层的信息过度的压缩,将会丢失大量的信息,对模型的训练也造成了困难。这在后面的section中具体给出了例子说明。
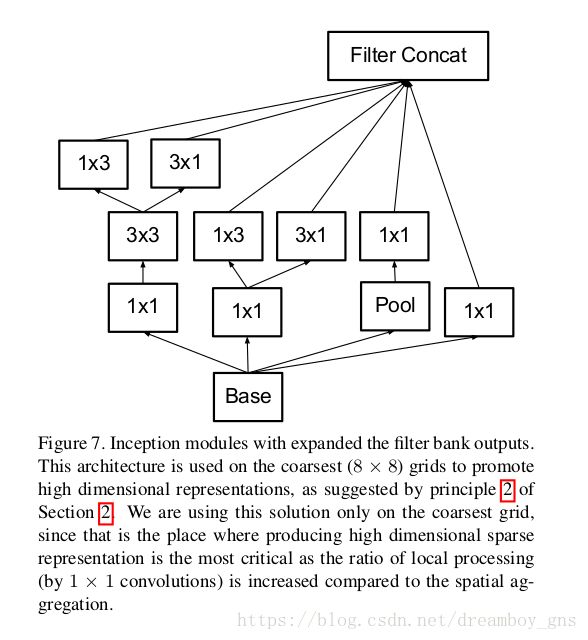
2.在网络中对高维的表达进行局部的处理,将会使网络的训练增快,可参见下面的figure7,即做出很多小的inception module。
3.在较低维度的输入上进行空间聚合(spatial aggregation),将不会造成多少表达能力上的损失,因为feature map上,临近区域上的表达具有很高的相关性,如果对输出进行空间聚合,那么将feature map的维度降低也不会减少表达的信息。这样的话,有利于信息的压缩,并加快了训练的速度。所以我们可以在较低维度3*3的卷积操作前通过1*1的卷积来reduce dimension,这样对表达能力不会造成太大影响且有效降低了计算量
4.设计网络的深度和宽度达到一个平衡的状态、将计算资源平衡的分配在模型的深度和宽度上面,才能最大化的提高模型的性能!
分解大尺寸卷积核:
1*1的卷积核+紧随其后的3*3卷积核实际上也可以看做是分解大尺寸卷积核的一种情况,理论支持是设计原则中的第三点。这里将探索几种不同场景下的卷积核分解。
1. 只减小卷积核的尺寸(size)
我们可以把5*5的卷积核分解成两个3*3的卷积核,容易看到receptive field(感受野)是没有改变的,但是5*5卷积核的计算量是一个3*3卷积核的25/9=2.78倍。可见,3*3卷积核的堆砌在计算量上优于5*5的卷积核。
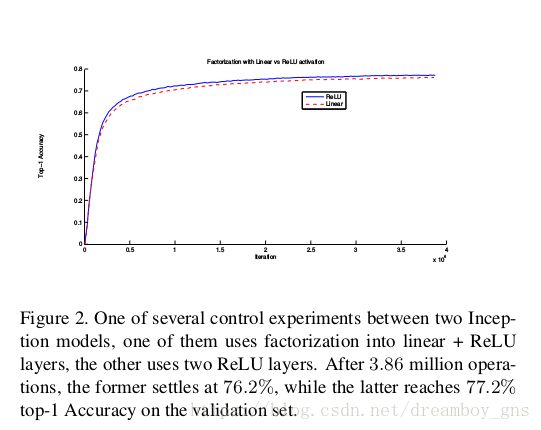
两个3*3 的卷结合引入了更多的non-linearity,增强了model的表达能力。论文中指出(如下图figure2),对分解后的两个卷积核都使用Relu激活函数更有利于准确率的提升,VGG论文中也对这一点进行了分析。
7*7或者尺寸更大的卷积核也可以此类推,即我们可以将它们分解为一系列的3*3卷积核,由此我们得到了figure5的结构图
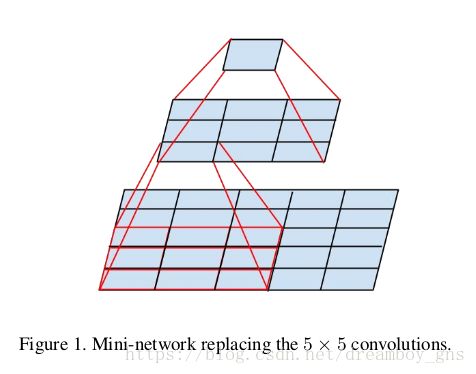
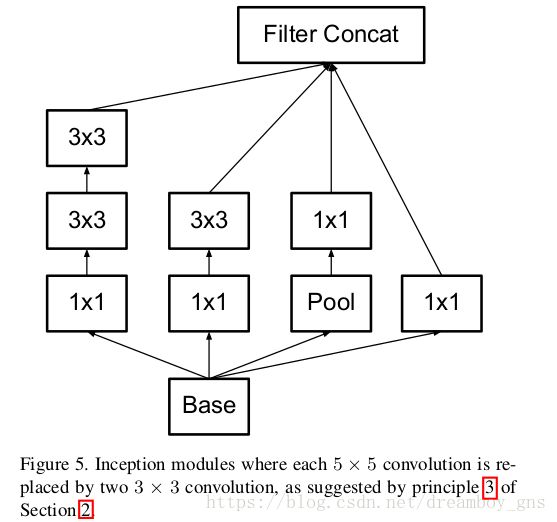
2. 分解成非对称的卷积核
从上面的分析中,我们很自然地会想到一个问题,即我们可不可以把3*3的卷积核再向更小的尺寸分解呢?比如2*2?
事实上,论文中指出,用3*1和1*3的卷积核可以更有效地降低计算量(与3*3相比降低了1/3)。而可以证明,n*n的卷积核都可以分解为n*1和1*n的卷积核。但是在实际当中,我们发现浅层网络中应用这种分解并不能起到很好的效果,而在feature map处于中等大小(比如12到20左右,此时输入已经经历了若干个卷积层)时这种分解是很有效的。
这种分解的应用如下图1和图2(figure7,还体现了我们的设计原则2,增强高维表达)
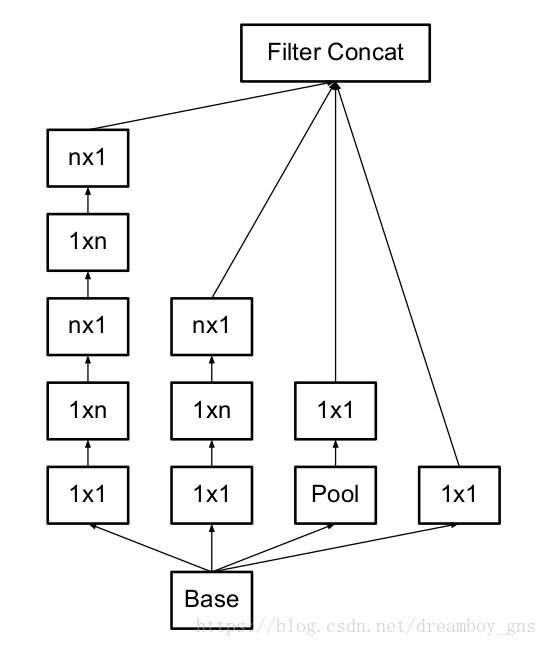
辅助分类器(Auxiliary Classifiers)的实用性
早期有论文指出,辅助分类器有助于提高超深网络的收敛性,理由是这种分类器可以让有用的梯度立刻产生作用而不必回溯到更低的layer中,这实际上解决了超深网络中的梯度消失问题。
但是,本论文作者发现辅助分类器并不能起到这样的效果。因为他发现移除掉辅助分类器的branch后,并不会影响网络的最终表现(main classifier, final performance),所以辅助分类器的作用更类似于一种正则化,而非早期论文指出的“帮助低层特征演进”
有效降低feature map 大小
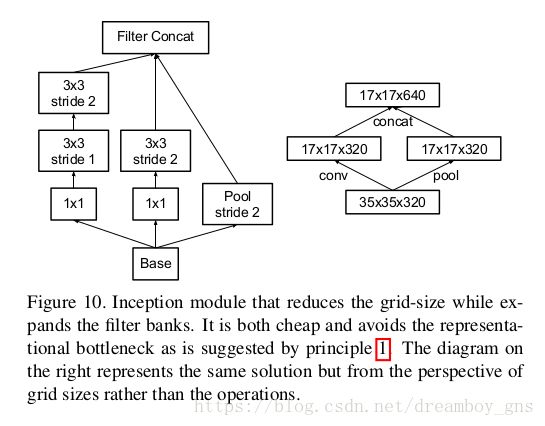
在我们的common sense中,我们常用卷积(same padding) + pooling操作来降低feature map的大小,但是这种方法的计算量较大。如从一个d*d*k的结构得到一个d/2*d/2*2k的结构,我们在卷积后进行pooling,那么计算量是2*d*d*k*k。一种替代方式是先进行pooling操作,再进行conv卷积操作,这样的计算量降低到了2*d/2*d/2*k*k,但是这种方法带来了表达瓶颈的问题,正如设计准则一所提到的。作者的替代方法如图,采用卷积与pooling并行,最后stack 在一起的结构(这种方式里我们的卷积不是same padding的)。因此我们可以看到在较低层中直接使用pooling容易带来表达瓶颈。
网络结构
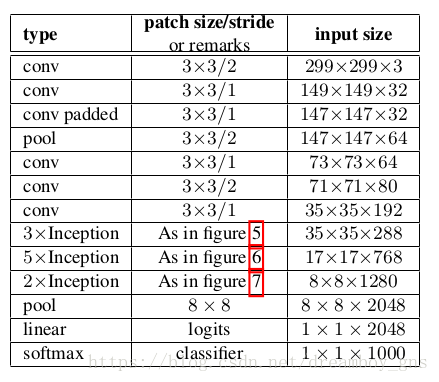
每一层的input-size都是上一层的output-size,没有标注padded的卷积层都没有使用same-padding
+
通过标签平滑(Label Smoothing) 实现模型正则化
考虑我们的softmax函数,它得到的概率是对真实标签分布进行正则化后的结果。在z(y) >> z(k) for k != y 时,我们近似完成了最大似然估计,但是这种方法存在两个问题,即它可能会导致过拟合且拉大了类别之间的差距,如果我们的model给某个class打上了概率1,那么就强化了概率间的差距,model的泛化(generalize)能力就得不到保证。简单来说,就是模型太自信了!(too confident)。基于此,论文作者提出了一种修正的方法,即Label-Smoothing Regularization(LSR),LSR虽然会一定程度上影响我们的最大似然估计,但它强化了模型泛化的能力。修正后的distribution公式和entropy交叉熵公式如下(delta为origin分布):
![]()
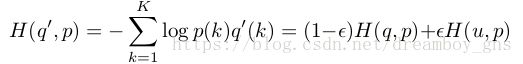
其中u(k)为我们引入的一个固定分布,使用较多的是统一分布(uniform distribution)即u(k) = 1/K (K为类别数) 这样q'(k)就有了一个正的下界,不同的label之间的差距不会太大(如果某个class为1其它均为0,通过LSR计算出来的交叉熵就会很大)
在低分辨率输入上的表现
视觉网络在分类与物体检测上一个很重要的应用场景就是小物体检测。直觉上来看,高分辨率图像输入往往可以得到表现更好的识别模型。但是我们不能忽略高分辨率同时带来的高计算量(即我们对同样的模型用小分辨率输入时它的计算量会降低), 现在摆在我们面前的问题是,当计算量保持不变的情况下,提高输入的尺寸对我们的任务会起到多大的帮助?论文中保持计算量不变的方法是降低前两层的stride或者直接移除掉pooling层,结果如图
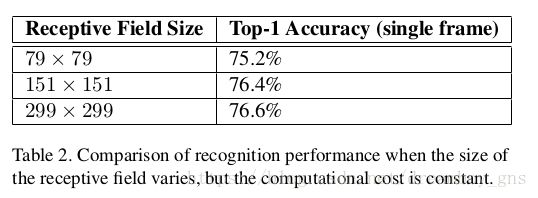
可以发现,我们完全可以用high cost的低分辨率图像在R-CNN等语境中达到较好的小物体检测和识别效果
实验结果与对比:
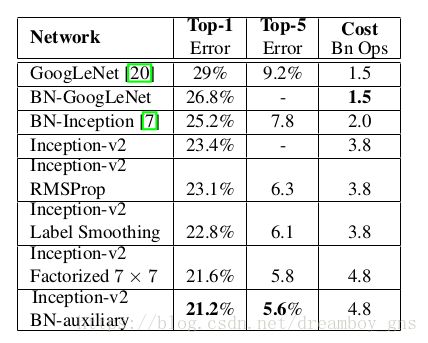
如上图,每一行inceptionv2都是新的changes加上上面行的changes,这里的BN-auxiliary指的是对辅助分类器层的全连接层做了BN(Batch Normalization,可参见inceptionv2论文),最后一行应用了所有changes的网络就是新的inceptionv3模型
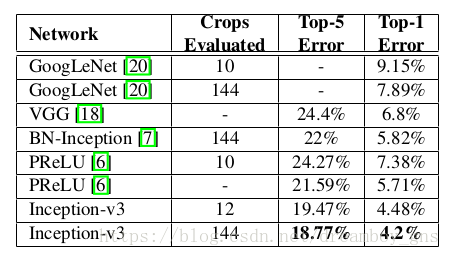
和相关网络的比较
结论:
作者提供了几个scale up 卷积网络的原则并在inception模型中分析了这几个准则。inception模型的计算量只相对于先辈提高了2.5倍,就在ILSVR的分类问题上达到了21.2% top-1 error 与5.6% error top-5 的准确率。文章中论证了高质量的结果通过79*79的图像就可以达到,分析了分解卷积核,降低维度,辅助分类器,模型正则化等方法。
参考:
https://blog.csdn.net/wspba/article/details/68065564