小目标检测算法SNIPER—— SNIP的实战版本 (目标检测)(two-stage)(深度学习)(Arvix 2018)
论文名称:《 SNIPER: Efficient Multi-Scale Training 》
论文下载:https://arxiv.org/abs/1805.09300
论文代码:https://github.com/MahyarNajibi/SNIPER

4)是SNIP的思想
一、 概述:
SNIPER算法是一种多尺度(multi-scale)训练算法。为了实现对图片上不同大小目标的检测,需要针对multi-scale提出有效方法。现在很多的目标检测算法,比如Faster R-CNN/Mask R-CNN,它们实现multi-scale的思路除了使用anchor的思想之外,还都使用了图像金字塔思想,这是为了提高精度。但是我们知道的,这种方法肯定会严重影响速度,不管是训练还是inference预测,用了这种方法的一般都是为了追求高精度,而暂时不注重速度。
图像金字塔(image pyramid)影响速度的原因:每一个scale的图片的所有像素都参与了后续的计算。(比如一个3scale的image pyramid(分别是原图的1倍,2倍,3倍),它要处理相当于原图14倍的像素)
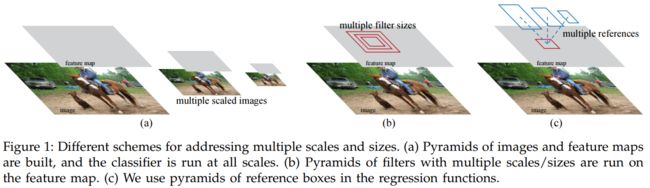
图像金字塔算法包含上采样和下采样。
(1)上采样:就是图片放大(所谓上嘛,就是变大),步骤:
1)将图像在每个方向放大为原来的两倍,新增的行和列用0填充;
2)使用先前同样的内核(乘以4)与放大后的图像卷积,获得新增像素的近似值;
(2)下采样:就是图像压缩,会丢失图像信息,步骤:
1)对图像进行高斯内核卷积;
2)将所有偶数行和列去除;
二、SNIPER的改进基础
(SNIPER 综合了R-CNN 在scale上的优点 和Fast R-CNN在速度上的优点):
(1)R-CNN回顾:
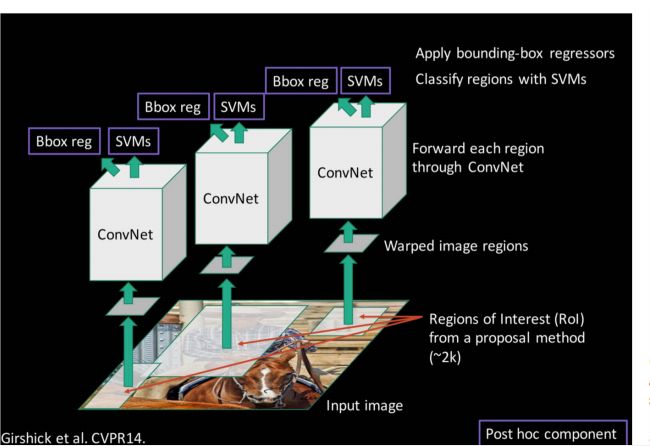
R-CNN
two-stage开山之作,很多新的目标检测算法都是从R-CNN演变而来的。在R-CNN检测的第二步里对通过selective search生成的候选区域(region proposals)做了warped操作,一般是warp成224x224大小的图片,这个是CNN中经常使用的输入图片尺寸。因为R-CNN相当于一个分类问题,因此将不同大小的region proposal缩放成固定大小,实际上引入了尺度不变性 (scale invariant ),这也解决了 multi-scale 的问题,任何一个唯一尺寸的region proposal都相当于一个scale。由于候选区域是由selective search生成的,因此有一定的先验知识,换句话说每个不同大小的region proposal,其scale也代表了object的scale。虽然第3步输入的是固定大小的region proposals(看起来是没有考虑scale的),但是scale已经在提取候选区域时和缩放时完成了,实际上输入的warped region proposals是有已经包含了多scale信息。它最主要的问题在于提取特征时,CNN需要在每一个候选区域上跑一遍,候选区域之间的交叠使得特征被重复提取, 造成了严重的速度瓶颈, 降低了计算效率。
2、Fast R-CNN回顾:
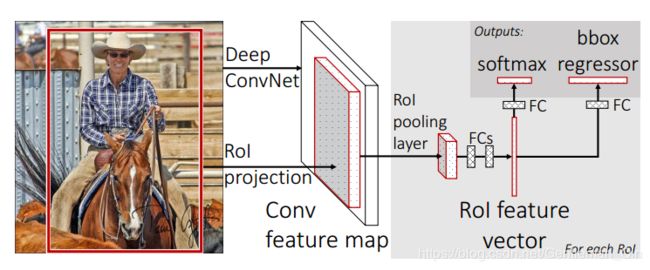
Faster R-CNN
Fast RCNN的提出主要是解决了R-CNN的速度问题,它通过将selective search生成的候选区域映射到feature map上,实现了候选区域间的卷积计算共享,同时由于共同参与计算,Fast R-CNN也能更多的获取到全局信息(contex)。而同时提出的 ROI pooling也将对应到feature map上的候选区域池化到相同的大小,ROI pooling 在某种程度上也可以引进尺度不变性 (scale invariant ),因为可以将不同大小的region proposal(连同 object)在feature map层面池化到固定大小。但它的问题是前面的卷积层部分是只在一个scale上进行的,这正是为了实现卷积计算共享所带来的一点负面影响,因为是卷积计算共享,所以不同大小的目标没有办法进行不同比例的缩放操作,所以相对于原图大小来说,它们都处于一个scale。这影响了尺度不变性 (scale invariant ),因此为了弥补这一点,在训练或者inference时,会使用image pyramid的操作,直接把原图放大&缩小后送入同一网络进行训练。但是image pyramid有一个问题,就是在缩放原图时,object也会跟着缩放,这就导致原来比较大的object变得更大了,原来更小的object变得更小。这在R-CNN中是不存在这个问题的。
三、SNIPER:
1、Chip Generation(chips的生成):
文章中定义了chips,指的是某个图片的某个scale上的一系列固定大小的(比如KxK个像素)的以恒定间隔(比如d个像素)排布的小窗(window) ,每个window都可能包含一个或几个objects(类似sliding window)。假设有n个scale,{s1,s2,…,si,…sn},每个scale的大小为 Wi×Hi,将原图缩放至对应比例后,在每个尺度的特征图上会产生K×K大小的chip(对于COCO数据集,论文用的512×512)并以等间隔(d pixels)的方式排布,注意是每个scale都会生成这些chips,而且chip的大小是固定的,变化的是图片的尺寸,跟anchor的思想刚好相反,因为anchor中,不变的是feature map,变化的是anchor。更重要的是,代替原图输进网络用于训练的就是这些chip,每个chip都是原图的一部分,包含了若干个目标。即一张图的每个scale,会生成若干个Positive Chips 和 若干个 Negative Chips 。每个Positive Chip都包含若干个ground truth boxes,所有的Positive Chips则覆盖全部有效的ground truth boxes。每个 Negative Chips 则包含若干个 false positive cases。怎么区分chip的正/负?小老弟先往下看。
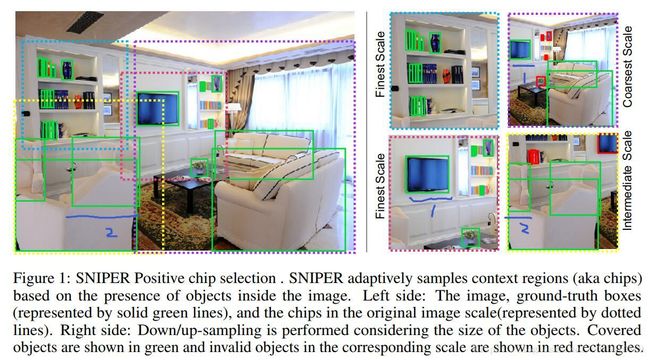
2、Positive Chip Selection(筛选有效Chip):
每个scale(共i个,i=1,...,n),都会有个对应的area range Ri,这个范围决定了这个scale上哪些ground truth box是用来训练的。所有ground truth box中落在 Ri 范围内的ground truth box 称为有效的(对某个scale来说),其余为无效的,有效的gt box集合表示为 Gi 。在某一Scale中,从所有chips中选取包含(完全包含)有效 gt box最多的chip,作为Positive Chip,该尺度下Positive Chip的集合称为 Cipos ,保证每个scale下的每一个gt box都会有chip包含它。因为不同scale的Ri的区间会有重叠,所以一个gt box可能会被不同scale的多个chip包含,也有可能被同一个scale的多个chip包含。被割裂的gt box(也就是部分包含)则保持残留的部分。
如上图,左侧是将gt box和不同scale上的 chip都呈现在了原图上,这里为了展示,将不同scale的图片缩放回原图大小,不同scale下的chip随之变化,所以chip才有大有小,它们是属于不同scale的。右侧是训练时真正使用的chips,它们的大小是固定的。可以看出这张图片包含了三个scale,所以存在三种chip,chip中包含有效的gt box(绿色)和无效的gt box(红色)。从原图可以看出,原图中有一大部分的背景区域(没被postive chip覆盖的区域)被丢弃了,而且实际上网络真正输入的是chip(比原图分辨率小很多),这对于减少计算量来说很重要。换句话说,SNIPER 只用了4张低分辨率的chips 就完成了所有objects的全覆盖和multi-scale的训练方式。在不同的scale上截取相同大小的chip,而且包含的是不完全相同的目标。这个方式很接近 RCNN。对较小的目标起到一种 zoom in “放大”的作用,而对较大的目标起到一种 zoom out“缩小”的作用。而对于网络来说,输入的还是固定大小的chip,这样的结构更加接近于分类问题网络。
说到这里,我想多说几句,如果算法截止到这一步,相当于只选择原图中有兴趣的部分进行训练,这种从源头解决问题的思想,在星载图像压缩领域的未来方向之一有异曲同工之妙——现在我们的图像压缩传输方式是对在星上拍摄的全图压缩回传,在地面进行各种处理比如目标检测,我的导师松松老师曾跟我们提过这种思路,就是在拍摄图片后即在星载设备上进行初步的图像处理过滤部分无用的图片区域,将有用的压缩后回传,这将在图像压缩及传输方面节省相当多的人力物力(顺便打个广告,我们团队的星载图像压缩及传输应用于嫦娥探月工程、火星探测工程等国家级重大航天工程,曾获国家科技进步二等奖~)
3、Negative Chip Selection(过滤无效Chip):
思想:如果参与训练的图片只包含上述的 postive chip,那么由于还是有大部分的区域背景在postive chip,没人告诉网络“这样的背景时错误的”,所以算法对背景的识别效果不好,导致假正例(False Positive,即把背景误判成目标)的比率比较高。因此需要生成 negative chip送入训练来提高网络对背景的识别效果。现在的目标检测算法因为在multi-scale训练时,所有的像素都参与了计算,所以假正例率的问题不严重(但是计算量大,有的算法里还存在投入训练的负样本过多的情况,比如大部分one-stage算法),但是此处因为抛弃了很多背景,所以会使假正例率增加。为了降低假正例率和维持计算量不至于上涨太多,一个简单的解决办法就是使用一个精度不是很高的RPN(Region Proposal生成网络,提出于 Faster R-CNN ,点击进入对应博文)生成一些不太准确的proposals,这些proposals中肯定有一大部分都是假正例,此RPN都没有生成proposals的地方则有很大可能是背景区域或者漏掉的目标区域,那么训练时把这一部分也直接抛弃即可。
具体生成流程:首先使用训练集训练一个不是很精确的RPN,生成一系列 proposals,对每个scale i,移除该scale下被 positive chip 所覆盖到的那些proposals,因为它们大概率与positive chip 中的gt box重合,所以并非要作为负样本的背景。在输入图片的每个scale下的chip池中选取包含至少M个proposals的所有chips作为 negative chip(也要满足在本尺度的Ri范围内),其集合称为 Cineg。训练时,每张图片在每个epoch中只从 negative chip 池中选择固定数量的 negative chip(同时送入全部positive chip),由可调参数控制(具体操作文章中解释不清晰)。

说到这里,我又想多说几句,算法中的这一步我两周前的项目组内汇报的内容,即目标检测中正负样本比例适当的重要性,在One-Stage算法中存在一个“类别不平衡问题”(在 RetinaNet 中提出,点击进入对应博文),即负样本太多,但算法没有Two-stage算法中的生成Region Proposal的过程进行用来训练正负样本的比例控制(基本是1:3=正:负),导致训练精度不如Two-Stage算法,这也是One-Stage算法的一个改进方向( RefineDet 就是一个例子,点击进入对应博文)。而本文中的此步若不做,SNIPER算法则会刚好走入另一个极端,即缺少足够负样本来让网络知道“什么是错的”,导致训练出的模型基本的“排除”能力。
4、其他:
(1)许多网络为了增加精度,会使用image pyramid而且会使用较高分辨率的图片,SNIPER 则摆脱了对较高分辨率图像的依赖,训练时使用的是较低分辨率的chip,所以batch也可以调大,节省了内存,使得SNIP的思想可以落地,即所谓标题中的“实战版本”。
(2)生成 positive/negative chip的过程算是一个预处理过程,不算这一部分,即文章中所谓的端到端的训练。回归时标签的赋值与 Faster R-CNN是类似,其他的设置基本跟 Faster R-CNN 差别不大,只是正样本比例啊,OHEM啊,损失函数等有所不同。
(3)文章的 multi-scale 训练方式有创意,但是可能在实现上会有点复杂 ,得编程实现。
(4)文章证明了前作提出的“在高分辨率图片上进行训练这一常用技巧并不是提升精度必须要使用的策略”(即 SNIP 的核心观点,点击进入对应博文)的观点。
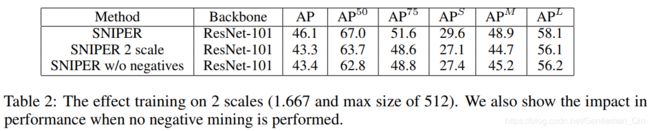
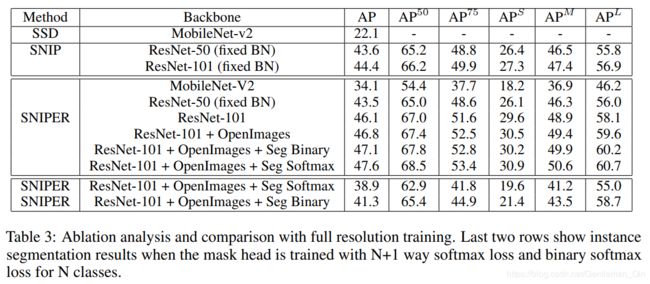
四、实验结果: