推荐系统实战--movieslens数据集实现UserCF算法
UserCF:UserCollaborationFilter,基于用户的协同过滤
算法核心思想:在一个在线推荐系统中,当用户A需要个性化推荐时,可以先找到和他有相似兴趣的其它用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A,这种方法称为基于用户的协同过滤算法。
可以看出,这个算法主要包括两步:
一、找到和目标用户兴趣相似的用户集合——计算两个用户的兴趣相似度
二、找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户——找出物品推荐
下面分别来看如何实现这两步:
一、计算两个用户的兴趣相似度:
给定用户u和用户v,令N(u)表示用户u感兴趣的物品集合,N(v)表示用户v感兴趣的物品集合,那么可以通过Jaccard公式或者通过余弦相似度公式计算:
 ...Jaccard公式
...Jaccard公式
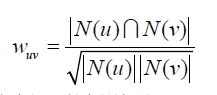 ...余弦相似度公式
...余弦相似度公式
举例:下图表示用户A对物品{a,b,d}有过行为,用户B对物品{a,c}有过行为

利用余弦相似度计算可得:
用户A和用户B的兴趣相似度为:
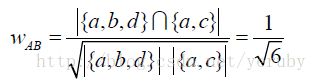
(cosθ = X * y /(||X|| * ||y||)) 也就是X * y = ||X|| * ||y|| * cosθ 这个公式推导得出
同理,
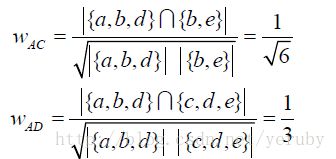
但是,需要注意的是,这种方法的时间复杂度是O(U^2),因为我们需要计算每一对用户之间的相似度,事实上,很多用户相互之间并没有对同样的物品产生过行为,所以很多时候当分子为0的时候没有必要再去计算分母,所以这里可以优化:即首先计算出|N(u) 并 N(v)| != 0 的用户对(u,v),然后对这种情况计算分母以得到两个用户的相似度。
针对此优化,需要2步:
(1)建立物品到用户的倒查表T,表示该物品被哪些用户产生过行为;
(2)根据倒查表T,建立用户相似度矩阵W:在T中,对于每一个物品i,设其对应的用户为j,k,在W中,更新相应的元素值,w[j][k]=w[j][k]+1,w[k][j]=w[k][j]+1,以此类推,扫描完倒查表T中的所有物品后,就可以得到最终的用户相似度矩阵W,这里的W是余弦相似度中的分子部分,然后将W除以分母可以得到最终的用户兴趣相似度。
针对此优化,需要2步:
(1)建立物品到用户的倒查表T,表示该物品被哪些用户产生过行为;
(2)根据倒查表T,建立用户相似度矩阵W:在T中,对于每一个物品i,设其对应的用户为j,k,在W中,更新相应的元素值,w[j][k]=w[j][k]+1,w[k][j]=w[k][j]+1,以此类推,扫描完倒查表T中的所有物品后,就可以得到最终的用户相似度矩阵W,这里的W是余弦相似度中的分子部分,然后将W除以分母可以得到最终的用户兴趣相似度。
得到用户相似度后,就可以进行第二步了。
二、给用户推荐和他兴趣最相似的K个用户喜欢的物品。
公式如下:
其中,p(u,i)表示用户u对物品i的感兴趣程度,S(u,k)表示和用户u兴趣最接近的K个用户,N(i)表示对物品i有过行为的用户集合,Wuv表示用户u和用户v的兴趣相似度,Rvi表示用户v对物品i的兴趣(这里简化,所有的Rvi都等于1)。
根据UserCF算法,可以算出,用户A对物品c、e的兴趣是:
以上就是UserCF最简单的实现方法。
我们还可以在此基础上进行改进,改进思想是:两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。
比如,两个用户都买过《新华词典》并不能说明两个人的兴趣相似,而如果两个人都买过《数据挖掘导论》则可以认为他们的兴趣相似。
==>公式如下:
可以看到,如果一个物品被大多数人有过行为,则这样的信息参考价值不大,权重变小。
以上内容参考自《推荐系统实践》
代码如下:
1.形成数据集
import numpy as np
import pandas as pd
import math
#形成用户-电影评分数据集
ratingsDF = pd.DataFrame({
'userId':[1,1,1,1,1,1,1,2,2,2,2,2,2,2,3,3,3,3,3,3,3,4,4,4,4,4,4,4],
'movieId':[1,2,3,4,5,6,7,1,2,3,4,5,6,7,1,2,3,4,5,6,7,1,2,3,4,5,6,7],
'rating':[5,0,3,4,5,0,0,3,0,3,0,2,3,4,0,0,2,0,4,3,0,3,5,0,0,2,0,4,]
})
#形成电影ID-名称数据集
moviesDF = pd.DataFrame({
'movieId':[1,2,3,4,5,6,7],
'title':['蝙蝠侠','闪电侠','蜘蛛侠','火影忍者','死神','超人','复仇者联盟']
})2.处理数据形成一个用户ID-电影ID透析表
ratingsPivotDF = np.pivot_table(ratingsDF,index='userId',columns='movieId',,values='rating',fill_values=0)
ratingsPivotDF
3.形成一个userId字典和movieI字典
userIdDict = dict(ratingPivotDF.index)
movieIdDict = dict(ratingPivotDF.columns)4.计算相似度公式
ratingValues = ratingsPivotDF.values.tolist()
def colCosineSimilarity(list1,list2):
res = 0
mol =0
den1 = 0
den2 = 0
for val1,val2 in zip(list1,list2):
mol += val1 * val2
den1 += math.sqrt(val1**2)
den2 += math.sqrt(val2**2)
res = mol / (den1 * den2)
rerurn res5.计算相似度
#设计一个 4*4大小的矩阵保存相似度
## 随后,需要计算用户之间的相似度矩阵,对于用户相似度矩阵,这是一个对称矩阵,同时对角线的元素为0,所#以我们只需要计算上三角矩阵的值即可:
userSimMatrix = np.zeros((len(ratingValues),len(ratingValues)),dtype=np.float32)
for i in range(len(ratingValues)-1):
for j in range(i+1,len(ratingValues)):
userSimMatrix[i,j] = calCosineSimelarity[i,j]
userSimMatrix[j,i] = userSimMatrix[i,j]6.排序相似度
# 接下来,我们要找到与每个用户最相近的K个用户,用这K个用户的喜好来对目标用户进行物品推荐
#如果数据大,可以取前K个
# 下面的代码用来计算与每个用户最相近的所有用户:
userMostSimDict = dict()
for i in range(len(ratingValues)):
userMostSimDict = sorted(enumerate(userSimMatrix[i]),key=lambda x:x[1],revers=True)7.利用公式计算兴趣度
from IPython.display import Image
Image(filename='recommenderSystem.png')
#通过上面的公式获得用户U对电影i的兴趣分,如果评过分说明对这部电影兴趣分为0。
#其中,p(u,i)表示用户u对物品i的感兴趣程度,S(u,k)表示和用户u兴趣最接近的K个用户,N(i)表示对物品i有#过行为的用户集合
#Wuv表示用户u和用户v的兴趣相似度,Rvi表示用户v对物品i的兴趣
userRecommendValues = np.zeros((len(ratingValues),len(ratingValues[0])),dtype=np.float32)
#从第i个人开始
for i in range(len(ratingValues)):
#从第j部电影开始
for j in range(len(ratingValues[i])):
#如果第i个人对第j部电影没有评分,则表明有兴趣
if ratingValues[i,j] == 0:
val = 0
#第i个人对第j部电影的兴趣度 = 前k个相似的人的相似度sim * 这k个人对电影的评分
for userId,sim in userMostSimDict:
val += sim * ratingValues[userId,j]
#得到最终的兴趣分,也就是计算出的对电影的评分
userRecommendValues[i][j] = val 8.开始推荐电影
排序兴趣度表,哪部电影兴趣度越大,那部排名越靠前
#接下来,我们为每个用户推荐电影:
#获得一个从大到小排列的兴趣分的矩阵
userRecommendDict = dict()
for i in range(len(ratingValues)):
userRecommendDict[i] = sorted(enumerate(list(userRecommendValues[i])),key=lambda x:x[1],reverse=True)
9.获得推荐的具体结果
# 将推荐的结果转换为推荐列表之后,我们将推荐结果转换为二元组,
# 这里要注意的是,我们一直使用的是索引,
# 我们需要将索引的用户id和电影id转换为真正的用户id和电影id,
# 这里我们前面定义的两个map就派上用场了:
userRecommendList = []
#遍历获得的推荐矩阵中的键值对,获得用户u对每部电影i的键值对
for userId,value in userRecommendDict.items():
#用户为用户字典中的用户
user = usersMap[userId]
#遍历得到的值,中存储电影id和兴趣分
for movieId,Pui in value:
#如果对某部电影有兴趣分,则推荐这部电影
if Pui != 0:
userRecommendList.append([user,moviesMap[movieId]])#最后一步,我们将推荐结果的电影id转换成对应的电影名,并打印结果:
recommendDF = pd.DataFrame(userRecommendList,columns = ['userId','movieId'])recommendDF = pd.merge(recommendDF,moviesDF,on='movieId',how='left')