Keras——imdb电影评论分类
本文主要介绍使用keras对IMDB评论进行分类。
示例代码:
import keras
from keras.datasets import imdb
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import RMSprop
from keras import losses
from keras import metrics
import matplotlib.pyplot as plt
'''
加载数据
num_words=1000:表示只保留训练数据中最常出现的10000个单词
train_data和test_data是评论列表,数据里的单词序列已被转换为整数序列,每个整数代表字典中的特定单词
train_labels和test_labels是0和1的列表,其中0表示‘负面评论’,1表示‘正面评论’
'''
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
# print('data0:', train_data[0], 'label0:', train_labels[0])
# print(max([max(sequence) for sequence in train_data]))
# 将评论解码回到英文单词
# word_index是将单词映射到整数索引的字典
word_index = imdb.get_word_index()
# print(word_index)
# 将word_index反转,实现将整数索引到单词的映射
reverse_word_index = dict([(value, key) for(key, value) in word_index.items()])
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
# print(decoded_review)
# 数据预处理
def vectorize_sequences(sequences, dimension=10000):
# 创建一个全0矩阵->shape(len(sequences), dimension)
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
# 将训练数据和测试数据矢量化
X_train = vectorize_sequences(train_data)
X_test = vectorize_sequences(test_data)
# print(X_train[0])
# 矢量化标签
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
# print(y_train[0])
# 创建模型
model = Sequential()
model.add(Dense(16, activation='relu', input_shape=(10000, )))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile model
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.compile(optimizer=RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
model.compile(optimizer=RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
X_val = X_train[: 10000]
partial_x_train = X_train[10000:]
y_val = y_train[: 10000]
partial_y_train = y_train[10000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(X_val, y_val))
history_dict = history.history
print(history_dict.keys())
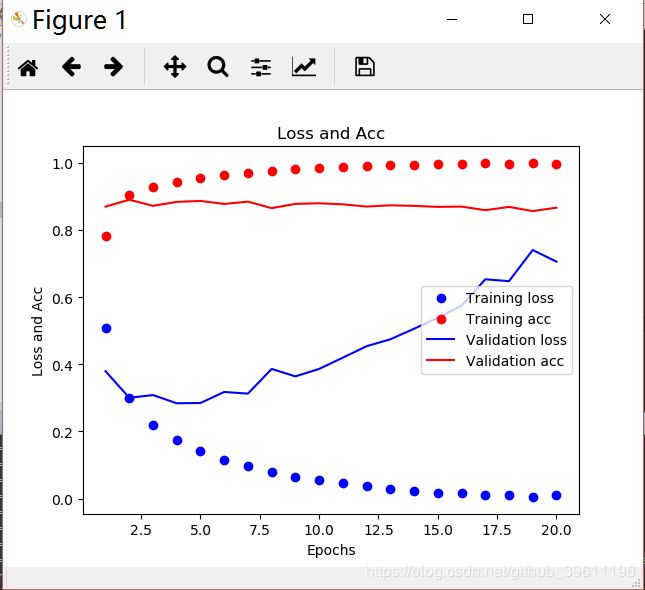
# 绘制loss-acc图
acc = history.history['binary_accuracy']
val_acc = history.history['val_binary_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, acc, 'ro', label='Training acc')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Loss and Acc')
plt.xlabel('Epochs')
plt.ylabel('Loss and Acc')
plt.legend()
plt.show()
结果(部分):
5632/15000 [==========>...................] - ETA: 1s - loss: 0.0047 - binary_accuracy: 1.0000
6144/15000 [===========>..................] - ETA: 1s - loss: 0.0045 - binary_accuracy: 1.0000
6656/15000 [============>.................] - ETA: 1s - loss: 0.0045 - binary_accuracy: 1.0000
7168/15000 [=============>................] - ETA: 1s - loss: 0.0045 - binary_accuracy: 1.0000
7680/15000 [==============>...............] - ETA: 1s - loss: 0.0043 - binary_accuracy: 1.0000
8192/15000 [===============>..............] - ETA: 0s - loss: 0.0043 - binary_accuracy: 1.0000
8704/15000 [================>.............] - ETA: 0s - loss: 0.0042 - binary_accuracy: 1.0000
9216/15000 [=================>............] - ETA: 0s - loss: 0.0045 - binary_accuracy: 0.9999
9728/15000 [==================>...........] - ETA: 0s - loss: 0.0045 - binary_accuracy: 0.9999
10240/15000 [===================>..........] - ETA: 0s - loss: 0.0045 - binary_accuracy: 0.9999
10752/15000 [====================>.........] - ETA: 0s - loss: 0.0045 - binary_accuracy: 0.9999
11264/15000 [=====================>........] - ETA: 0s - loss: 0.0045 - binary_accuracy: 0.9999
11776/15000 [======================>.......] - ETA: 0s - loss: 0.0047 - binary_accuracy: 0.9998
12288/15000 [=======================>......] - ETA: 0s - loss: 0.0067 - binary_accuracy: 0.9989
12800/15000 [========================>.....] - ETA: 0s - loss: 0.0108 - binary_accuracy: 0.9970
13312/15000 [=========================>....] - ETA: 0s - loss: 0.0114 - binary_accuracy: 0.9968
13824/15000 [==========================>...] - ETA: 0s - loss: 0.0111 - binary_accuracy: 0.9969
14336/15000 [===========================>..] - ETA: 0s - loss: 0.0108 - binary_accuracy: 0.9970
14848/15000 [============================>.] - ETA: 0s - loss: 0.0105 - binary_accuracy: 0.9971
15000/15000 [==============================] - 3s 210us/step - loss: 0.0105 - binary_accuracy: 0.9971 - val_loss: 0.7057 - val_binary_accuracy: 0.8665
dict_keys(['val_loss', 'val_binary_accuracy', 'loss', 'binary_accuracy'])
loss和acc: