基于Selenium爬取淘宝商品+pyquery解析+MongoDB存储
一、前言
你未看此花时,此花与汝同归于寂;你来看此花时,则此花颜色一时明白起来,便知此花不在你的心外。
喜欢阳明的哲学,也希望以后可以身心力行,知行合一。
二、环境搭建
本文主要在window系统下,基于python3环境。
selenium安装: pip3 install selenium
pyquery安装: pip3 install pyquery
pymongo安装: pip3 install pymongo
配置Chromedriver: 根据Chrome版本下载相应版本,具体参见上篇博客selenium使用
Mongodb安装:
1、下载地址
https://www.mongodb.com/download-center#community
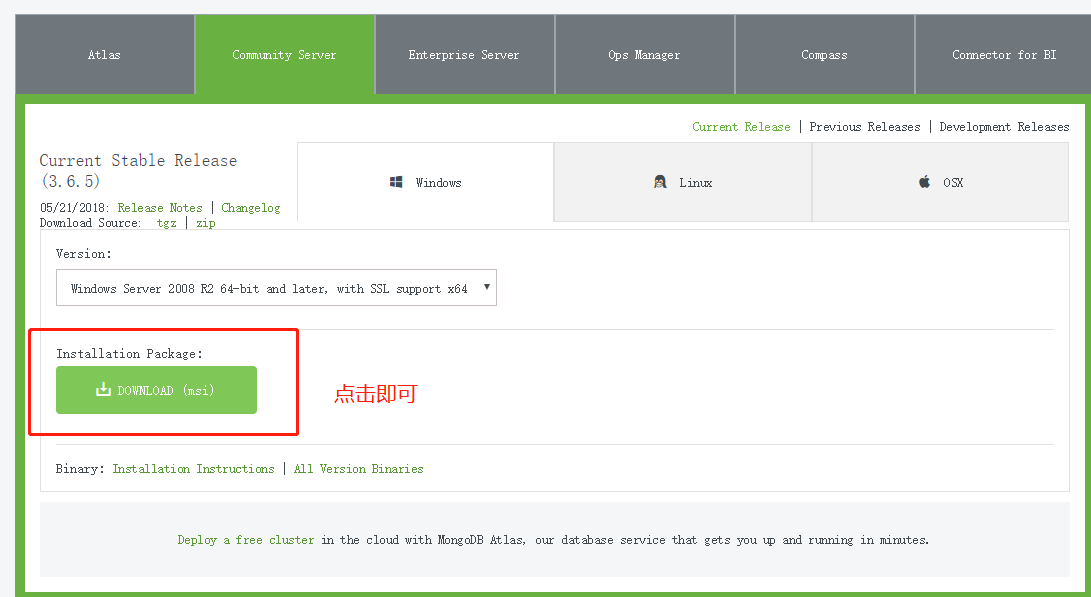
2、双击安装,选择common选项指定路径,点击next安装成功即可。下面设定你的安装路径为C:\MongoDB\Server\3.4
3、在此路径bin目录下新建【同级目录】data文件夹,进入data文件夹,新建子文件夹db来存储数据目录。
4、打开命令行,输入cmd命令,进入C:\MongoDB\Server\3.4\data\db目录下,运行MongoDB服务,如下:
mongod --dbpath "C:\MongoDB\Server\3.4\data\db"运行之后会打印一些信息,这样我们就启动MongoDB服务了。但这个命令行不能关闭,否则MongoDB这个服务就不能使用了。这显然不是我们想要的,接下来还需要将mongdb配置成系统服务。
a、以管理员模式运行命令行,【记住一定要用管理员身份】。
b、在bin目录新建同级目录logs,进入之后新建一个mongodb.log文件,用于保存MongoDB的运行日志。然后a步骤启动的命令行里输入
mongod --bind_ip 0.0.0.0 --logpath "C:\MongoDB\Server\3.4\logs\mongodb.log" --logappend --dbpath "C:\MongoDB\Server\3.4\data\db" --port 27017 --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install这里意思是绑定ip为0.0.0.0(任意IP可以访问),指定日志路径、数据库路径和端口,指定服务名称,如果没有出错,说明MongoDB服务已经安装成功,然后启动。可以在服务管理页面查看到系统服务。
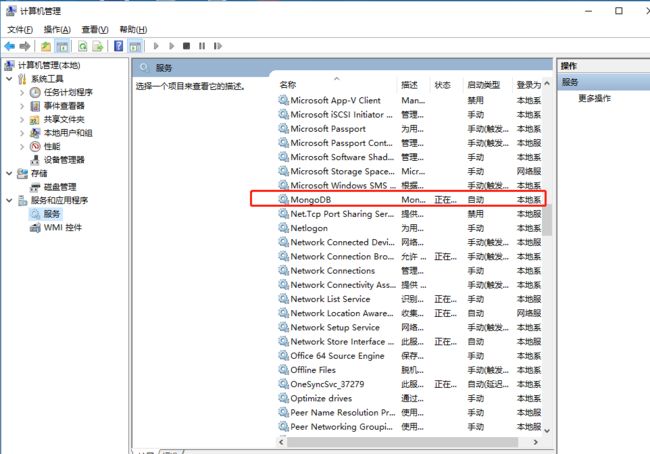
注:记得把之前根据命令行启动mongdb的cmd命令框关闭,然后这个服务设置成自动启动或者手动启动,这样可以非常方便的关联MongoDB服务了。
三、目标数据
我们利用selenium抓取淘宝商品并用pyquery解析得到商品的图片、名称、价格、购买人数、店铺名称和店铺所在地信息,并保存在MongoDB。

抓取的入口就是在淘宝搜索页面,例如输入iPad,就可以直接访问https://s.taobao.com/search?q=iPad,呈现第一页的搜索结果,如图所示:
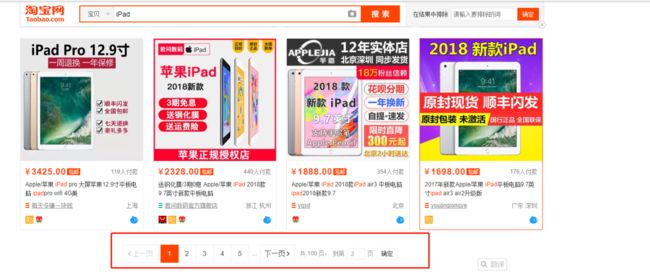
页面下方,有一个分页导航,可以下一页,也可以跳转页面跳转链接,一共100页。
注:这里不直接点击下一页,原因是:一旦爬取过程中出现异常退出,就无法快速切换到对应的后续页面了,而且在爬取过程中还要记录当前页面数,一旦点击下一页之后页面加载失败,还需要做异常检测,检测当前页面是加载到第几页了,整个流程比较复杂。所以这里直接用跳转的方式爬取。
当我们成功加载出某一页商品列表,利用Selenium获取页面源码,然后再用相应的解析库,这里选用pyquery进行解析,然后用mongdb存储,具体实现如下操作,相应库的使用方法,会另开博文叙述。
四、获取商品列表
分析下思路:如何利用selenium获取商品的链接页(获取的源码和浏览器看到的一样);如何对商品链接页解析,提取数据;如何保存数据到mongdb中。
首先根据我们的思路着手操作
获取商品的链接页
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from urllib.parse import quote
from pyquery import PyQuery as pq
from pymongo import MongoClient
# 声明浏览器对象,这里使用Chrome浏览器
browser = webdriver.Chrome(r'c:\bin\chromedriver.exe')
# 引入WebDriverWait对象,指定显示等待,最长等待时间10s
wait = WebDriverWait(browser, 10)
KeyWord = 'ipad'
# 总页数
MAX_PAGE = 100
MONGO_URL = 'localhost'
MONGO_DB = 'taobao'
MONGO_COLLECTION = 'products'
client = MongoClient(MONGO_URL)
db = client[MONGO_DB]
# 获取商品链接页
def index_page(page):
print('正在爬取第',page,'页')
# 搜索关键词在淘宝中的首页链接地址
try:
# quote作用是字符串编码,对应的unquote是解码,自己可以动手操作
url = 'https://s.taobao.com/search?q=' + quote(KeyWord)
browser.get(url)
# 如果寻找第2/3/4……页,开始利用跳转输入,确定搜索。
if page>1:
# 找到数字输入框的节点,传入presence_of_element_located条件,代表节点出现的意思,参数是节点的定位元组
# 这样做到的效果就是在10s内如果这个输入框节点成功加载处理,就返回该节点,超过10s还没加载出来,就抛出异常
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input')))
# 找到确定按钮的输入框节点,同上解释,不过是按钮节点
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page)
submit.click()
# text_to_be_present_in_element方法,判断元素中存在指定文本,用来判断当前高亮页面是当前的页面数即可,说明跳转页数成功
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page)))
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'#mainsrp-itemlist > div > div > div')))
get_products()
except TimeoutException:
index_page(page)
# 解析商品列表
def get_products():
# 获取各种渲染后的源码
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('data-src'),
'price': item.find('.price').text().replace('\n',''),
'deal': item.find('.deal-cnt').text(),
'title':item.find('.title').text().replace('\n',''),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
save_to_mongo(product)
def save_to_mongo(result):
try:
if db[MONGO_COLLECTION].insert(result):
print('存储MongoDB成功')
except Exception:
print('存储MongoDB失败')
def main():
for i in range(1,MAX_PAGE+1):
index_page(i)
if __name__=='__main__':
main()打印成功页面
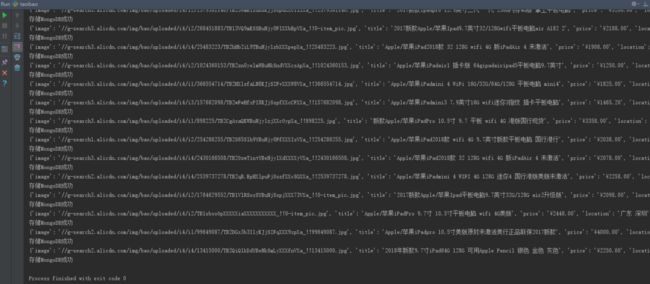
存储到MongoDB数据库

到此为止,我们成功的爬取了淘宝的商品信息。
五、对接PhantomJS
如果不想使用Chrome的Headless模式,还可以使用PhantomJS(无界面浏览器)来抓取。不会弹出窗口,只需要在WebDriver的声明修改一下即可
browser = webdriver.PhantomJS()另外,它还支持命令行配置,比如,可以设置缓存和禁止图片加载的功能,进一步提高爬取效率:
SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']
browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)六、结束
本文主要基于静觅大神的博客,自己动手操作而成,有自己的理解,有少量代码中参数的一些不同,但结果应该都一样,后续还会持续向静觅大神学习爬虫技术,欢迎交流。