颜值估计(1)Label distribution based facial attractiveness computation by deep residual learning
版权声明:本篇文章为博主原创文章,码字不易,未经博主允许,不得转载:https://mp.csdn.net/postedit/79810023
Label distribution based facial attractiveness computation by deep residual learning (点击下载)
这篇文章属于颜值估计文章,利用的网络是深度残差网络。不同于之前的回归方法,该算法使用的标签是对标签分布进行学习,有一定的新意,因此总结在这里学习!
文章首先说明了,在颜值估计方面主要有两个难题摆在面前:
1、颜值估计图片样本的不足。网上和显示中能找到太多的图片,但是对应一个人长得到底怎么样,没有确切的打分结果作为标签。之前东南大学弄了一个数据集SCUT-FBP可以说是很大程度上弥补了这个问题的不足。该数据集的连接SCUT-FBP
2、没有精确的人脸表达。你很难说清楚,哪个人漂亮,哪个人丑陋,个人主观性太大。
为了解决以上两个问题,文章使用了对应的方案:
1、使用将传统的监督学习中的单一标签问题转换为学习标签分布的问题,这样的话就不是那么受样本数量多少的影响。
通常情况下,想要获得人们对于一个人的颜值评价的做法是:召集各种类型(从事不同工作,不同年龄,男女性等)评价人员(花钱雇的)来对手上有的数据集进行样貌评价,比如将颜值评分分为十个等级,然后一张一张给评价人员看,然后让他们打分,最终将他们评分的结果取平均,就是最终得分。可以想象,这个过程相当难做。对于以前使用人工特征提取器方法来进行衡量还好,数据量不需要那么大。但是对于现在热火朝天的深度学习而言,这种数据的获取方式所对应的工作量实在是太大了。而且每个人都有不同观念,对于美丑的鉴定又不是非常可观,导致最终结果也不一定准确。不过大数定律告诉我们,只要样本足够,那么精度就一定可以通过平均得到。希望将来能有一些机构专门针对这一领域进行专门的工作,能够产生一些类似ImageNet或者VOC之类的数据集(其实工作量都挺大)。
通过下图可以看到,对于同一张人脸,总共有5个人数,不同人对于其评估的结果是不同的。横坐标表示该脸得分等级,纵坐标表示一共有多大比例的评价人员对该数做出了贡献。从结果可以看出,虽然每个人的评分结果是不同的,但是对于该脸,总体评价是有一个分布的。如果将该人脸的评价从某一个固定的分数(比如图中的4.143这个平均分)转到某一个得分分布,这样的话就会更贴近实际情况了。比如我要我的算法不是用4.143作为标签,而是将对于该脸整体评价的分布作为标签,那么我的算法需要学的就是对于1分有0%的人做出评价,对于2分,有4%,对于3分,有15%··········。这样的话,算法可以不依赖太大的样本。
该文章就是这个思路。

2、相比手工选取特征进行人脸表达,利用深度残差网络来加深网络层次,从而提取更普遍的人脸特征。
深度学习之前,有太多的人工设计特征提取器,不能说它们不好,最起码在没有大数据驱动的情况下,依靠绝对智力来解决问题的做法是最正确的。这些特征提取器种类繁多,有针对几何结构的、针对肤色的、针对纹理的等。这里又分为针对局部设计的和针对总体设计的。这些特征提取器虽然现在逐渐被深度学习的方法替代,着实减轻了太多科研工作者的压力,但是其在某些较为重要的领域还是有着不可替代的作用的。现如今,用一个简单的3、5层网络所提取的特征进行处理,都有可能比手工特征提取器提取的特征更有用。并且网络越深,对于特征表达越有效,这已经在诸多网络中得到了验证,尤其是深度残差网络,简直是一种逆天的存在,居然能搞1000多层还能训练,实在是厉害。
本文便是采用了深度残差网络,直接将RGB图像丢给网络,自己去学特征。优势就是网络深,特征表达更高级,也更有效。
在以上1 和2 两种方案合力的作用下,该算法在SCUT-FBP数据集上达到了state-of-the-art精度
1、网络结构:
首先利用一些面部提取器(比如dlib)提取出人脸,然后提取出的人脸图像最短边扩充0来与最长边相同,得到一个正方形人脸,然后暴力resize到224*224大小。
下图对网络与训练进行了简单的描述:

对于输出,我们可以看到,最后一层用到了5维的全连接,是因为对人脸进行打分的分数段一共有5个(1,2,3,4,5分)。
图中的{n1, n2, n3, n4}分别表示残差网络每个块有几层。如果不太熟悉残差网络,请再回去看下网络结构(Deep residual learning for image recognition )。
文章分别用了50层和101层的网络,所以对应的{n1, n2, n3, n4}分别为{2, 3, 5, 2}和{2, 3, 22, 2}。
网络就介绍完了,其实网络这块到没有什么改动,最后的全连接改成了所需要的结果。
2、 损失函数
前面说了,该算法采用的不是单一标签进行分类或回归,而是采用结果标签的分布来进行训练,所以看一下怎么训。
我们在年龄估计这块介绍过将年龄进行编码时可以使用高斯描述度来表达,这里作者也是受整个启发,进行的改进。
对于一幅输入图像,那么最后全连接特征表达输出的5维特征表达经过softmax层之后,对应产生5个概率,这5个概率就分别表示该图片属于每个分数的可能性。
对于这张图像,假设其对应的标签分数分别为: y={y1 , y2, y3, y4, y5}(这里一共5个颜值评分,所以有5个)。而且每个分数都有一个评价人员所占的比例。比如上面说的,有15%的评价人员给出了3分的评价,那么这个15%就是该分数的一个分布值。
而经过softmax层之后,各概率的分布为 di={d1, d2, d3, d4, d5},其中d1+d2+d3+d4+d5=1。那么网络需要学习的就是这个di 的每个值都应该与评价人员给出某个分数所占的比例相同。
就是通过这样一个转化,将原来进行分类所对应的某个标签(第一类,第二类·······)转换成进行分数比例(%0,%4等)的学习。
那么如何如何定义损失函数呢?
作者在这里给出了两种方式:
1、 欧式距离:
这个比较直白,对于每个概率都有一个对应的标签分布值与其对应,那么将估计结果与标签分布值之间求均方差即可:

这里的di就表示我们实际对应的标签分布值,f(x;theta)就表示网络学习到的概率分布。
2、 KL散度
这个概念属于信息论,它是衡量一种分布由另外一种分布进行表示时所损失的信息,具体可以看这篇博客:https://blog.csdn.net/u014380165/article/details/77284921#comments

那么预测的时候,给定一张图像,通过网络学到一个分布,这个分布结果就是我们所要求的估计结果。当然,如果你说非要某一个确切的数,比如3.52分这样的表示,那么就可以将所得的结果进行加权平均来得到最终分数。
那么,怎么衡量结果是否好呢?
由于其他算法在进行预测的时候都采用的是单一标签(比如3.52分),那么在这里可以将网络最终预测结果进行加权平均,从而也得到一个具体的分数,利用该分数与其他算法进行对比,可以评价模型的好坏。
这里引入一个概念叫做皮尔逊相关(Pearson correlation)来进行衡量。公式如下:
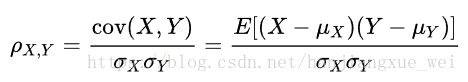
分子为两个变量的协方差,分母为两个变量的方差乘积。
这个概念的定义其实大家都见过,只不过没注意它是这个名称而已,具体可以见这里或这里。对于两个变量,相关系数越大表示两个变量的线性相关性越高,也就意味着可以通过一个变量经过线性变化表示另外一个变量的可能性就越大。对应本文来说,也就意味着估计结果越贴近真实标签分布,有很大的可能性可以用估计结果表示标签分布。
那么,网络学习到的结果在SCUT-FBP上进行评估的时候,其相关性如下图:

表格中的[11]是另一篇文章的结果,文章为A new humanlike facial attractiveness predictor with cascaded fine-tuning deep learning model ,点击这里下载。
可以看到,本文用的ResNet50与数据集标签分布相关程度最高,也意味着该结果与真是分布越贴进。
网络与损失函数说完了,上一张训练图:
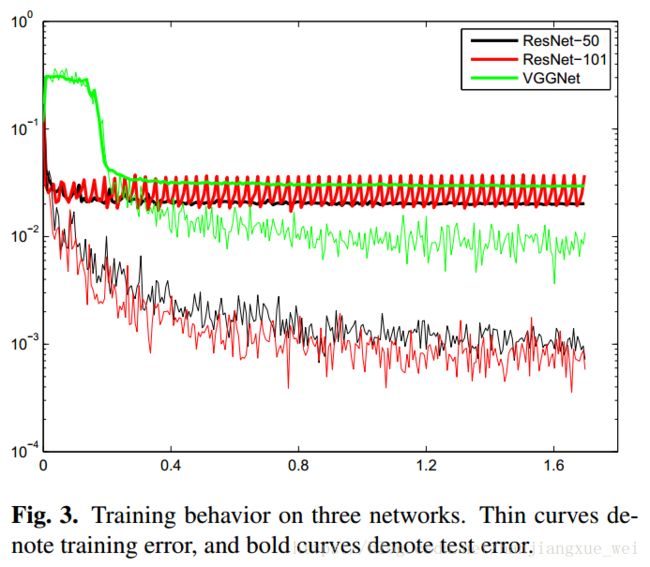
作者对比了三种网络,如上图所示。细线表示训练误差,粗线表示测试误差。非常直观,ResNet50表现最为出色,所得的结果也较好。这里作者使用了两种损失函数进行比较,发现欧氏距离稍微好点,所以网络采用的损失函数为均方误差。
作者最后又对数据集进行了增强,从而达到了更好的精度。具体见下表:

其中的 LDL 表示label distribution learning
本篇文章感觉作者的想法很有新意,所以记录在此以进行学习,希望自己也能够实现一下,熟悉一下这方面的东西。
还是希望大家能够批评指正!