Keras系列之卷积神经网络处理序列
作者:《python深度学习》学习笔记,用于自己熟悉和理解
目录
1.背景
2.序列数据的一维卷积
3.序列数据的一维池化
4.一维卷积神经网络的实现
5.结合 CNN 和 RNN 来处理长序列
5.1 一维卷积神经网络的缺点
5.2 结合的优点
5.3 实现结合一维卷积基和 GRU 层的模型
1.背景
卷积神经网络在计算机视觉领域表现优异,同样也让它对序列处理特别有效。时间可以被看作一个空间维度,就像二维图像的高度或宽度。对于某些序列处理问题,这种一维卷积神经网络的效果可以媲美 RNN,而且计算代价通常要小很多。最近,一维卷积神经网络[通常与空洞卷积核(dilated kernel)一起使用]已经在音频生成和机器翻译领域取得了巨大成功。除了这些具体的成就,人们还早已知道,对于文本分类和时间序列预测等简单任务,小型的一维卷积神经网络可以替代 RNN,而且速度更快。
2.序列数据的一维卷积
一维卷积层可以识别序列中的局部模式。因为对每个序列段执行相同的输入变换,所以在句子中某个位置学到的模式稍后可以在其他位置被识别,这使得一维卷积神经网络具有平移不变性(对于时间平移而言)。举个例子,使用大小为 5 的卷积窗口处理字符序列的一维卷积神经网络,应该能够学习长度不大于 5 的单词或单词片段,并且应该能够在输入句子中的任何位置识别这些单词或单词段。因此,字符级的一维卷积神经网络能够学会单词构词法。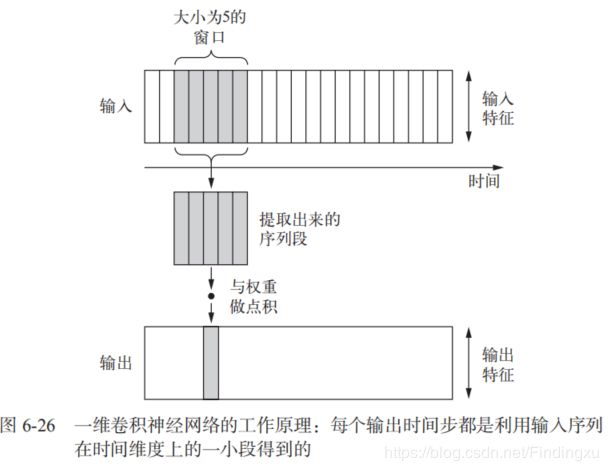
3.序列数据的一维池化
二维池化运算,比如二维平均池化和二维最大池化,在卷积神经网络中用于对图像张量进行空间下采样。一维也可以做相同的池化运算:从输入中提取一维序列段(即子序列),然后输出其最大值(最大池化)或平均值(平均池化)。与二维卷积神经网络一样,该运算也是用于降低一维输入的长度(子采样)。
4.一维卷积神经网络的实现
Keras 中的一维卷积神经网络是 Conv1D 层,其接口类似于 Conv2D。它接收的输入是形状为 (samples, time, features) 的三维张量,并返回类似形状的三维张量。卷积窗口是时间轴上的一维窗口(时间轴是输入张量的第二个轴)。
model = Sequential()
model.add(layers.Embedding(max_features, 128, input_length=max_len))
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer=RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2) 解析:是 Conv1D 层和 MaxPooling1D层的堆叠,最后是一个全局池化层或 Flatten 层,将三维输出转换为二维输出,让你可以向模型中添加一个或多个 Dense 层,用于分类或回归。
一维卷积神经网络可以使用更大的卷积窗口。对于二维卷积层,3×3 的卷积窗口包含 3×3=9 个特征向量;但对于一位卷积层,大小为 3 的卷积窗口只包含 3个卷积向量。因此,你可以轻松使用大小等于 7 或 9 的一维卷积窗口。
结果:验证精度略低于 LSTM,但在 CPU 和GPU 上的运行速度都要更快。使用正确的轮数(4 轮)重新训练这个模型,然后在测试集上运行。这个结果可以让我们确信,在单词级的情感分类任务上,一维卷积神经网络可以替代循环网络,并且速度更快、计算代价更低。
5.结合 CNN 和 RNN 来处理长序列
5.1 一维卷积神经网络的缺点
一维卷积神经网络分别处理每个输入序列段,所以它对时间步的顺序不敏感(这里所说顺序的范围要大于局部尺度,即大于卷积窗口的大小),这一点与 RNN 不同。
5.2 结合的优点
结合卷积神经网络的速度和轻量与 RNN 的顺序敏感性,可以在 RNN 前面使用一维卷积神经网络作为预处理步骤(见图 6-30)。对于那些非常长,以至于 RNN 无法处理的序列(比如包含上千个时间步的序列),这种方法尤其有用。卷积神经网络可以将长的输入序列转换为高级特征组成的更短序列(下采样)。然后,提取的特征组成的这些序列成为网络中 RNN 的输入。
5.3 实现结合一维卷积基和 GRU 层的模型
结构: 两个 Conv1D 层,然后是一个 GRU 层。
model = Sequential()
model.add(layers.Conv1D(32, 5, activation='relu',
input_shape=(None, float_data.shape[-1])))
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(32, 5, activation='relu'))
model.add(layers.GRU(32, dropout=0.1, recurrent_dropout=0.5))
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)
结果:效果不如只用正则化 GRU,但速度要快很多
参考:《python深度学习》