KMP算法的实现
KMP算法的实现
假如你急着要跟MM急着约会,抱团取暖,就直接调到下面看吧,我爱啰嗦,全部看完的话,我怕你会忍不住想打我。
kmp算法又称“看毛片”算法,但我作为跟根正苗红的社会主义接班人, 外加吃货属性 ,所以我还是偏向叫它“烤馍片”算法,此算法是一个效率非常高的字符串匹配算法。比之bf暴力其实在某些情况下也没高到哪里去的啦。
KMP是三位大牛:D.E.Knuth、J.H.Morris和V.R.Pratt同时发现的。其中第一位就是《计算机程序设计艺术》的作者!!!
开始不懂的时候,我在网上搜索资料,据说此算法是与红黑树,Manacher,遗传算法。。。等等可以强势提升逼格的牛逼算法之一,虽然很短,但确是属于难想难写的范畴里。
本着geek精神,经过一天的琢磨,凭借着搞不出来就不睡觉的社会主义建设者的拼搏精神终于在昨天的晚上顺利解决。喜迎十九大嘛。
多亏了小组温暖的空调(三十几度)。23333333~~~
提到KMP绕不开的就是BF暴力搜索了首先有这样两行字符串

第一行是主串str,第二行叫模式串ptr,要做的很简单,就是想在主串中找到一个子串使得它与模式串完全相同,你们都很聪明,一眼看过去就知道没有吧,恩,,,这个我也知道,重点是如何让计算机知道,怎么办。。。
我知道你们肯定都会说不就是,把这个和那个一比,那个再和这个比一比,再扭一扭,泡一泡就OK了。
emmmmmmmm~ mua ~ 回答完全正确。
首先,对于这个问题有一个很单纯的想法:从左到右一个个匹配,如果这个过程中有某个字符不匹配,就跳回去,将模式串向右移动一位。这有什么难的?
我们可以这样初始化:
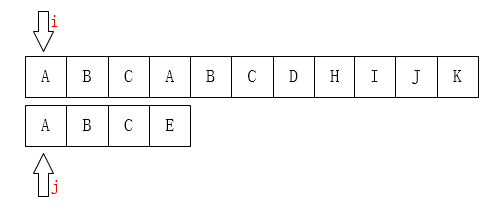
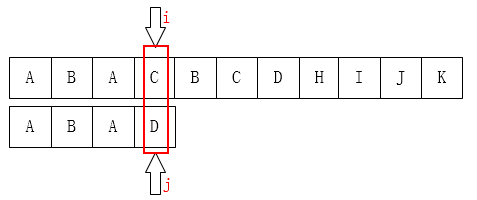
之后我们只需要比较i指针指向的字符和j指针指向的字符是否一致。如果一致就都向后移动,如果不一致,如下图:

A和E不相等,那就把i指针移回第1位(假设下标从0开始),j移动到模式串的第0位,然后又重新开始这个步骤:
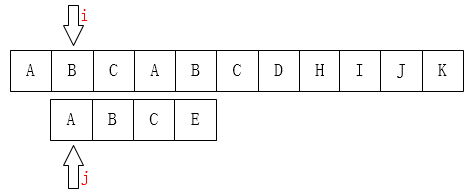
A和B又不相等,那就重复上一次的步骤直到找到相等的一个。发现最后好还是找不到,这不中要,重要的是咱们已经掌握了实现这个问题的方法。
根据此思路实现的代码如下(代码全部用标准C来实现)
/**
* 暴力破解法
* @ ptr 模式串
* @ str 主串
**/
#include
#include
int main(){
int j = 0; // 模式串的位置
int i = 0; // 主串的位置
int len_1;
int lne_2;
char str[100];
char ptr[100];
fgets(str,100,stdin); //获取主串
fgets(ptr,100,stdin); //获取模式串
len_1 = strlen(str);
len_2 = strlen(ptr);
while (i < len_1 && j < len_2){
if (str[i] == ptr[j]) { // 当两个字符相同,就比较下一个
i++;
j++;
} else {
i = i - j + 1; // 一旦不匹配,i后退
j = 0; // j归为0
}
}
if (j == len_2) {
printf("位置为%d\n",i-j); //找到就输出第一个符号的序号
} else {
printf("tan 90`\n"); //不存在
}
}
上边的算法其实在平常使用的时候是基本满足需求的
可是总有人需求不饱和,想搞出来一些骚操作,满脑子的骚想法,再加上时间复杂度为O(M×N);确实也蛮高的
如此 我们就要开始优化它。
我们继续来分析上边的两行字符串以及算法,发现每次模式串移动的太少了,一格一格的,像个老太太一样。我们一下子就看出了他下次如果直接移到与 下一次的主串A(即有相同首元素)所对应的位置 。这样岂不是要省很多事呢么。
的确省事多了,一次跳了4个位置,可是如果是这样呢主串为“SSSSSSSSSSSSB”,模式串为“SSB”。按照刚才对其首字母的方法,这两段的首字母相同,那模式串还是一个一个的在移动效率依旧不能提高,所以我们就觉得有没有一次能移动更多的方式呢???
====================================华丽丽的手动分割线==========================================
到了这里,是不是有点掀起美人的红盖头的感觉呢,没错,正因为如上原因,KMP 算法才应运而生,千呼万唤始出来啊!!!
我们做了那么多铺垫,其实无非就是想陈述一个事实,==整个KMP的重点就在于当某一个字符与主串不匹配时,我们应该知道j指针要尽可能多的移动到哪?==
也就是说当字符串有一处匹配不下去了,字符串他自己要能知道他下一步如何调整自身的位置与主串进行匹配而不是一味地傻瓜式地头部对其。那是不是每一个元素都得有所对应,自然而然的我们想到了找一个与模式串等长的数组来存储它匹配不上了该如何走的位置。(为方便,这里不用链表)所以此数组的求解成了此算法的核心内容。
我试下能用一两句话来说请这个问题不。
要不先看图吧
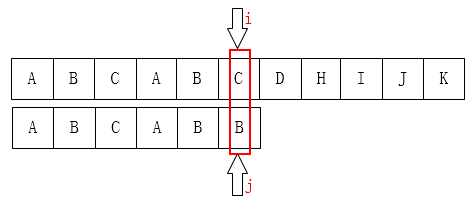
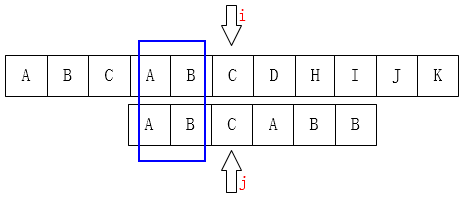
再看两幅

画图手累,不画了,宝贝儿,那你看懂了嘛
看不懂就多看两边吧。
敲黑板, 干货来了。
一语盖之,找相同而已
即找到 从模式串首字符开始和(模式串失配的前一个字符或者前几个字符) 和 模式串失配的前一个字符或者前几个字符(多多益善) 一模一样的字符段 如果有,则记下他的下一个字符的位置存入相对应的数组的位置。 (最大前缀后缀公共元素长度)
那我们试着做一个吧
1. 先找最大前缀后缀公共元素长度

.2.求next数组
next 数组考虑的是除当前字符外的最长相同前缀后缀,所以通过第①步骤求得各个前缀后缀的公共元素的最大长度后,只要稍作变形即可:将第①步骤中求得的值整体右移一位,然后初值赋为-1,如下表格所示:

基于以上的想法,可以实现一下代码(有时候知道想法了,实现代码实际上也不是一件容易的事,还是要多动手,多造轮子)
#includeprintf("%d ",next[i]);
}
代码确实简洁,看不懂没关系,我开始也看不懂。一步一步来解释。
现在要始终记住一点,next[j]的值(也就是k)表示,当P[j] != T[i]时,j指针的下一步移动位置。
- k=-1,意味着初始化回模式串首,模式串移不动了,得主串移动。
- 至于为什么这样回溯
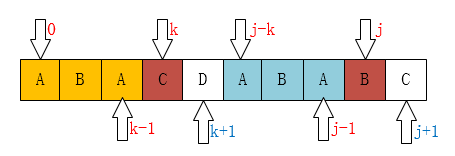
C和B此时匹配不上,那么此时的需要求解的模式串末尾的next值是他上一次求得的next的值
可能不是很清楚对应着 k = next[k] 这句代码结合下面的图你应该就清楚了吧。

因为你ptr[B]虽然现在匹配不是了,但我们关注的是最大前缀后缀公共元素长度,并发现你之前的A在他那一步是曾经匹配上过的,所以这个A现在就是当前的最大公共串,A失配时需要跳转到的位置就是B是失配时需要跳转的位置。
至此,我们的KMP算法基本上可以实现了。
#include感觉怎么样,是不是没有那么难,不过几十行而已
此时代码的时间复杂度竟然降低至 O(M+N);说点题外话, 宝贝儿,你看,这个代码的优化不过比之我们最开始写就的代码,只改了区区几行而已,而性能上居然有如此大的提升,我开学以来特别喜欢的东西就是这些优秀的算法了,这较之去年我对复杂算法的态度上一个特别巨大的转变,越难我越喜欢,无他,我喜欢啊。
其实这样的代码还是有缺陷的,不完美,比如这样
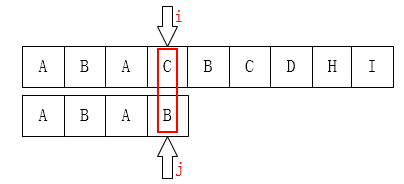
很显然的是B与C匹配不上,根据他的NEXT值他会跳转到下边的情况,对于大牛们来说这种低效是不能容忍的。
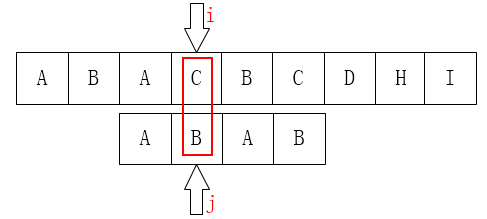
可是这个还是B(就你B事多),还是匹配不上的,实际上模式串中的A到时候也会发生这种情况,第二个A失配时根据NEXT要跳到第一个字符上,可是这两个刚好是A、一样的,所以就算跳过去了,还是匹配不上,所以这时候需要主串进行移动了。问题显然出现在 P[j] = P[next[j]] 这里,好人当到底,所以修改一下代码就是
#includeprintf("%d ",next[i]);
} 至此终于算是将馍片烤出来了。金黄酥脆,外焦里嫩,不枉我下这么大功夫。
要提到的是,这种优化显然是把next数组的值变了,没关系,进化了嘛,不叫next了叫nextval了。其实本质上都是一样的,无他,为了提高效率而已,这也是无数程序员,无数前辈孜孜以求的东西,今天我们一本书,一部电脑,就能轻轻松松习得,感慨难言。
给你们看个惊喜!!!

![]()
233333333~
我写这么多,你们看着办吧,攒钱娶媳妇,我不管~~~
×本篇参考了诸多前辈们的博客,书籍。
×有的图比较难绘,我就直接拉了过来。
×时间仓促,水平有限,有错误恳请指出。
×代码的都在本地验证过了,可以放心使用,linux环境