crowd counting 综述分析
Crowd counting
人群计数目前从两个角度来解决,一类方法是回归计数,直接得到图像中总人数的估计,另一类方法是先估计密度图,再有密度图积分求和得到总人数。目前来说密度图提供的信息更多些,得到的精度相对也更高些。可以将人群计数方法划分为六类:pixel-level analysis, texture-level analysis, object-level analysis, line counting, density mapping。
1、pixel-level analysis
基于像素特征的人群数目估计算法是最早被采用的估计算法,基本思想是提取当前图像中的前景像素总数和边缘像素点的数量越多,它们在此图像中所占比例越大,对应的在景人数也就越多。
Davies最早在crowd monitoring using image processing electronics-1995
中提出像素特征与人数呈近似的线性关系,通过三帧差法得出前景图像,并统计前景像素特征,接着再用人工方法统计每一帧图像中行人数量,建立线性方程求得相应线性关系。但是这种方法只有在人群数目较少时才能取得较好的效果;当人群数目过多,会出现严重的遮挡现象,这个方法也就不适用了。
1999年chow和cho在A Neural-Based Crowd Estimation by Hybrid Global Learning Algorithm中提出一种基于前馈神经网络(FFNN)的人群数目估计方法,并通过结合全局最优的最小二乘法与随机搜素算法对人群密度进行估计。经过前景处理后,提取出边缘像素点总数、前景像素总数所占整个图像像素点的比重、背景像素总数占整个图像像素点比重,这三个有效特征作为神经网络输入进行分类,实现框架图如下:

这个方法忽略了射影畸变以及图像阴影对系统的影响,当场景光照变化较快时,系统效果变差。
由于运动目标与摄像机相距越远其在图像中所占像素点就会越少,2004年Ma在On pixel count based crowd density estimation for visual surveillance中推导出一个有效的数学关系对图像中的运动物体进行几何校正,该算法主要思想是根据每一个前景目标所在图像中的位置给予不同权重值,结果证明其在行人遮挡不严重情况下具有较好效果。
2007年,Damian在Counting People using Video Cameras中提出网格化的解决方案,首先将图像按景深大小设置不同大小的网格(越靠近摄像头网格越大),并赋予相应权重,最后统计加权之后的像素特征。之后设置一个简易的检测器,检测图像是否有人。再用另外一个计数器对有人图片统计行人数量。结构图如下:

基于像素特征的人群数目估计方法简单,计算复杂的低,再稀疏场景下精确度较高,但是无法处理人群密度较大的场景下的人群遮挡问题。
2、texture-level analysis
高密度人群环境中,人与人之间的遮挡比较严重,单一的像素特征统计无法提供可靠的人群数量估计,1998年Marana在On the efficacy of tecture analysis for crowd monitoring中提出了基于纹理分析的人群密度估计算法。低密度人群在纹理上表现为纹理基元较大的粗模式,而高密度的人群图像的纹理基元较大,灰度差异较大,因而表现为细模式。文中利用灰度共生矩阵来分析图像的纹理特征,因为不同图像纹理尺度不同,灰度共生矩阵有很大差别,细纹理意味着图像包含更多细节,相应灰度共生矩阵中绝对值较大的矩阵元素主要集中分布在主对角线附近,与远离主对角线的矩阵元素数值上差异明显。相对的,粗纹理相似区域较大,所以其数值较大的元素分布就比较均匀。流程图:
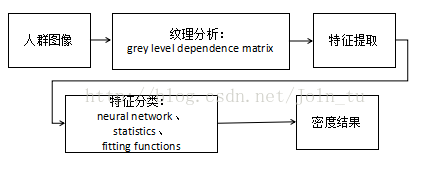
2006年Xiaohua在Estimation of Crowd Density Based on Wavelet and Support Vector Machine提出用二维的离散小波变换提取纹理特征,再用支持向量机分类方法将图像人群密度分类。流程图:

基于纹理特征的分析算法对高密度场景下的人群计数有不错效果,但是在低密度场景下,由于相邻基元之间的灰度变化较慢,图像提供细节信息较少,因而对低密度人群分类错误率较高。
3、Object-level analysis
Object-level analysis旨在检测出图片场景中的所有目标物体,进行计数。但,此方法仅在低密度人群场景下具有较高的精确度,一旦人群密度过度检测效果就不好了。
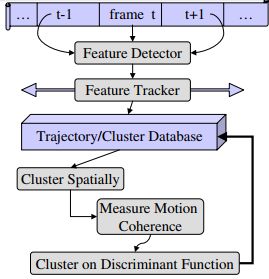
Brostow和Cipolla在2006年于Unsupervised Bayesian Detection of Independent Motion in Crowds中提出一种无监督学习的贝叶斯聚类算法来进行计数,基本思想是认为不同帧同一个物体上的相同的点一同运动。但是即便在低密度人群场景下的检测准确率,都比之前方法要低。流程图:
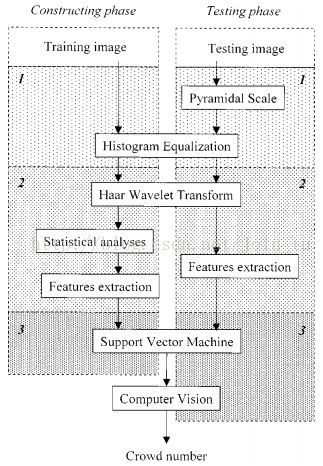
Lin et al.于2001在Estimation of Number of People in Crowded Scenes Using Perspective Transformation中,提出通过检测场景中的人头,来规避密集场景下检测的错误。该法用SVM的方法提取哈尔小波特征训练人头分类器。文章没给出实验结果,但是亲测检测成功率不是很理想。流程图:
Gao et al.于2016年在People-flow counting in complex environments by combining depth and color information中,提出一各基于颜色和深度信息的方法来计算人数。作者首先用帧差法分离运动区域,然后用SVM训练好的人头分类器检测运动区域的目标。总体来说在中高密度的人群场景下也具有不错的准确率,但是所有测试视频,都是由垂直安装的镜头进行拍摄的。流程图:

4、Line counting
Line counting主要是计算通过一条线的人流量。
Cong et al.于2009年在Flow Mosaicking: Real-time Pedestrian Counting without Scene-specific Learning中提出一种方法,将通过一根直线的行人建模为流体,并用光流法建立一个流速场。将加权的像素以及边缘作为输入,用二次回归估计行人数量(感觉有点像上边的像素统计方法)。受视角畸变的影响,每一个行人不同位置上的像素所在区域大小和数量都受到严重影响,文中将不同位置像素全部投射到肩部位置后,在进行权重的赋值。
Ma and Chan于2013在Crossing the Line: Crowd Counting by Integer Programming with Local Features另一个相似的方法。
5、Density mapping
通过估计密度图来进行人群计数。目前在高密度人群场景下,较好的方法都是基于CNN深度学习的方法来估计人群密度。
Lempitsky and Zisserman于2010年在Learning To Count Objects in Images中提出一种估计静止图片帧中人群密度的方法。对一系列给定表示目标位置的点,用一个各高斯核进行卷积操作,就得到一个人群密度分布的图,对于出现在边缘表示目标的点,常常会由于高斯核卷积而没有计算。但是论文并没有给出如何预测目标位置的方法。
Zhang et al.于2015年在Cross-scene Crowd Counting via Deep Convolutional Neural Networks中,提出利用CNN网络对不同密度场景,且已标定目标位置的图片进行训练,将训练图片区域分为低密度,中等密度,高密度三个层次,输出人群的密度图以及人数。在检测阶段,除了用训练好的CNN网络进行检测之外,还从训练图片中提取相似场景数据对输出进行微调以减小误差。实验中错误率为百分之十点七,帧率没有给出。流程图:
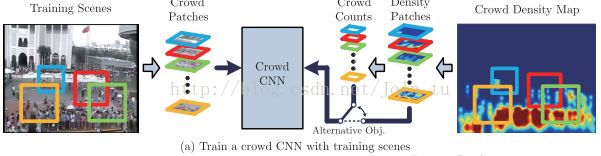

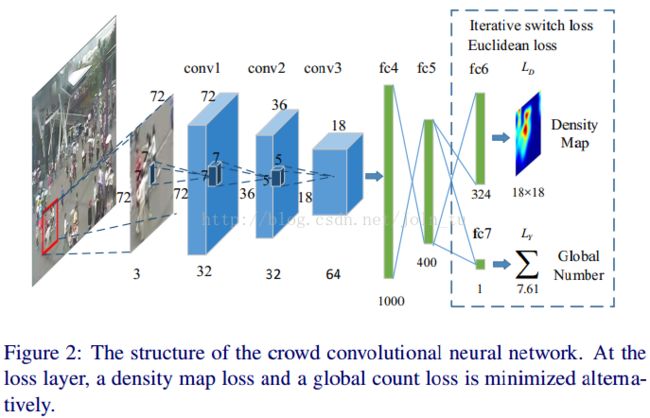
Zhang et al.于2016年在Single-Image Crowd Counting via Multi-Column Convolutional Neural Network,一种可以从一个单幅的图像中准确地估计任意人群密度和任意角度的人群数目的方法。该方法构建了一种简单有效的的多列卷积神经网络结(MCNN)将图像映射到其人群密度图上。该方法允许输入任意尺寸或分辨率的图像,每列CNN学习得到的特征可以自适应由于透视或图像分辨率引起的人/头大小的变化,并能在不需要输入图的透视先验情况下通过几何自适应的核来精确计算人群密度图。MCNN上不同列的卷积核拥有不同的尺度,以便于适应不同大小的人头。作者提到他们训练得到的MCNN模型要优于现有的其他方法。网络结构:
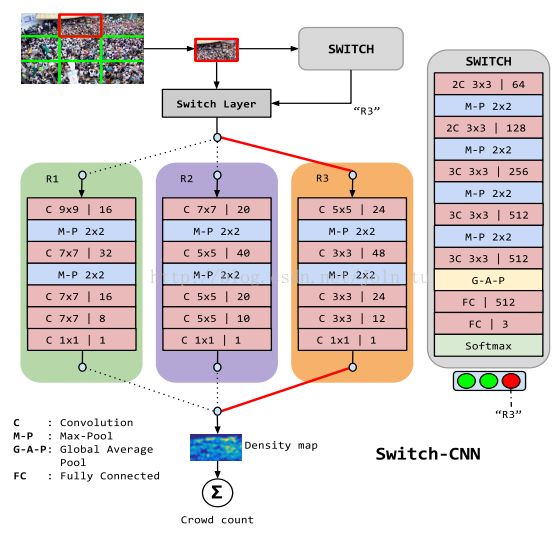
Sam于2017年在Switching Convolutional Neural Network for Crowd Countingt针对密集人群提出了一个S-cnn网络,根据图像块的内容信息选择适合的CNN进行人群密度估计。网络大体可以分为三个部分,一个是输入后后SWITCH以及SwitchLayer,SWITCH用于给输入的图片块分配标签,Switch Layer将根据这个标签将输入的图片块传入相应的CNN网络。第二部分是用于处理不同密度图片块的CNN网络,里边用不同大小的卷积核对不同尺度密度的人群图片进行处理。最后是输出的密度图。groundtruth由一个标准化的高核与每一个人头中心点的卷积和生成密度图。整个算法分为三个部分,分别是prestraining、differential training、switch training和coupled training。prestraining给出损失函数定义,以及用SGD梯度下降来进行参数更新。switch training将训练图像块进行分为三类,对应三个CNN网络需要的训练数据,然后再对每个CNN网络使用对应的数据集合进行微调。switch training对不同标签下的图片块进行训练生成分类器。coupled training通过对switch和regressors的切换训练对图块分类器和CNN regressors的参数进行微调调。
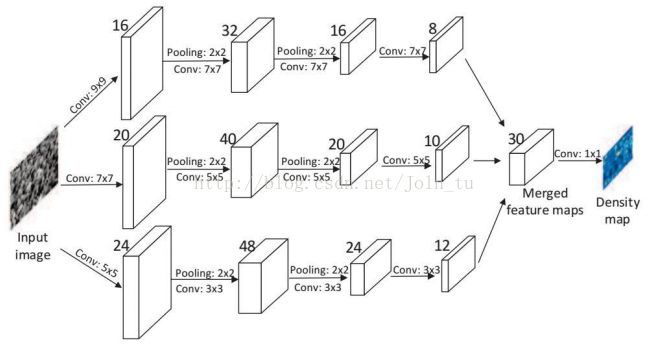
Zhang et al.在Crowd counting via scale-adaptive convolutional neural network中此文提出了一个单列的卷积结构,在保证相同检测精度的同时,大大提升了速度。文中设计一个单一的网络结构,用小尺寸卷积核提取固定的特征用于之后不同卷积核的的训练,大大降低了网络结构的复杂程度,在保证检测精度的同时,还对帧速有了很大的改善。网络结构:
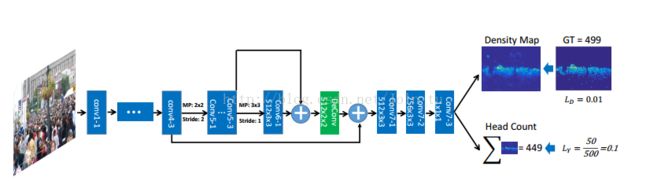
人群的数量和密度是群体分析的重要属性。这些统计数据为一些评估提供了一般的度量,例如消防部门制定的建筑物的容量等。虽然在人群计数方面有很多研究,但人们关注的焦点却很少。现有方法在测量人口密度高的人群中,仍然存在着挑战性的问题。这些挑战还需要良好的数据,以各种不同的角度、角度、分辨率和地面真相标签来进行比较。
【1】Grant J M, Flynn P J. Crowd Scene Understanding from Video: A Survey[M]. ACM, 2017.