SLAM笔记(七)回环检测中的词袋BOW
1.词频
(摘自阮一峰博客,参见附录参考)
如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行”词频”(Term Frequency,缩写为TF)统计。考虑到文章有长短之分,为了便于不同文章的比较,进行”词频”标准化。一般分母设置为文章总的词数或者出现最频繁的那个词的出现次数。比如:
对于一篇《中国的蜜蜂养殖》
但 出现次数最多的词—-“的”、”是”、”在”—-这一类最常用的词。它们叫做”停用词”(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
另一个问题,我们可能发现”中国”、”蜜蜂”、”养殖”这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为”中国”是很常见的词,相对而言,”蜜蜂”和”养殖”不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,”蜜蜂”和”养殖”的重要程度要大于”中国”,也就是说,在关键词排序上面,”蜜蜂”和”养殖”应该排在”中国”的前面。
最常见的词(”的”、”是”、”在”)给予最小的权重,较常见的词(”中国”)给予较小的权重,较少见的词(”蜜蜂”、”养殖”)给予较大的权重。这个权重叫做”逆文档频率”(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了”词频”(TF)和”逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值:
如果某个词相对来说不是很常见的词,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
评价(阮一峰)
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以”词频”衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
2.词袋
2.1 普通词袋
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “likes”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数),元素表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
实际处理时,每个单词的元素是其逆文本频率。
度量两袋词的相似度
两篇文章的相似度一般用其余弦相似度来衡量
2.2视觉词袋
词袋则是将该处的单词换成特征描述子表示。
对描述子聚类(如K类)后,可以用一个K维度向量表示该图:
每个单词的元素是其逆文本频率。
构建视觉词袋的步骤:
- 1.先对一图像集合 检测特征,形成特征描述量。2.通过对描述子进行聚类来形成词典,比如用层次Kmeans来形成一个词汇树(Vocabulary Tree),每个节点下的描述子集相近,可以认为同一个节点下的这些描述子是一个视觉单词(当然更顶层的表示越的图像越复杂)。如一个三层的每层聚类4的词汇树,可以形成4个维度的词向量,也可以形成16个维度的词向量,我们这儿只使用4个维度的粗表示。
- 对图像集中的每张图像,提取其对应特征描述量进行分类,然后得到分别属于四个类的描述子个数。即得到一个四维度的向量,归一化该向量,则将该图像表示成一个4维的向量。
- 将张图像都如上述表示成4维向量,则可以根据向量相似度知道每两张图像之间的相似度。
3.利用视觉词袋做回环检测SLAM
3.1 回环检测中的视觉词向量数据库
一般提前训练好词典,设计成单词树,每个树节点包含一个逆序索引信息包,每帧图像包含一个顺序索引信息包。对一新进来的图像帧,将其中每个特征点都从单词树根节点往下遍历,取汉明距离最小的节点接着往下遍历直到叶节点。最终同上,计算各个叶节点上的数目并形成第图像表达向量 v v 。同时得到图像的顺序索引,以便用于之后的回环检测。
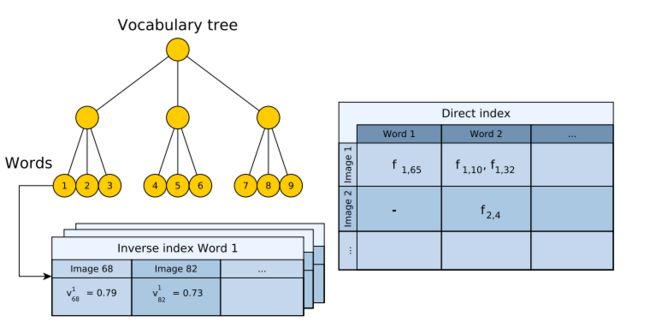
逆序索引:
对每个单词节点,它存储了逆序索引。所谓逆序索引,存储的是图像的索引号,以及该单词在对应图像中的权重(即逆文本频率),这样更容易找到该单词最相关的图像。(由于对应图像多少差别,逆序索引序列有长有短)
容易想到,每进来一张图像,该数据库包括逆序索引就需要更新。
如上图,分成Lw层,0层代表叶子节点即单词word所在的节点。该节点可能包含好多个特征点。节点1的逆序索引的表示在图68的逆文本频率(权重)为0.79,在图82的逆文本频率为0.73
顺序索引:
顺序索引对于每张图像,存储出现在图像中的每个特征(word)对应的父节点;找到父节点后再把父节点下边所有特征也加入顺序索引中。这样在最后的几何验证阶段就可以迅速找到两帧之间的特征匹配点对。需要为每张图建立0-Lw所有层的顺序索引。
如上图,第l层中,图1的顺序索引有节点3,节点3下边的所有特征点在本图像中出现的只有本图像中第65个特征点,其他顺序索引同理。
3.2 回环检测中的图像比较与度量
两图像的相似度为其向量的L1范数([0,1]):
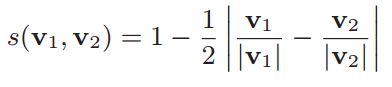
差异越大得分越小趋近于0;相似则趋近于1
当新的一帧到来,先计算其表达向量 vt v t ,随后凭借逆序索引得到一连串的相似图像,分别与每一张相似图像 vtj v t j 的归一化相似度:

其中分母为当前帧与上一帧的L1范数。跳过整个分母不满足最小阈值或上一帧的特征点数目不满足最小阈值的情况,来避免(诸如旋转时)当前帧与上一帧差异度太大(差异度越大得分越小)
对这些归一化相似度取一个合适的最小阈值取得
组匹配(Match grouping)
我们知道时间相近的帧在一定程度上是相似的,为了防止回环检测时与一大堆时间相近的帧匹配的相似度相差极小,因此当ni,ni+1,…,mi两两之间的时间都小于阈值时,帧相似度进一步转变成组相似度:
如果组相似度得分高于阈值,则选为组匹配并流入下一时间一致性步骤:
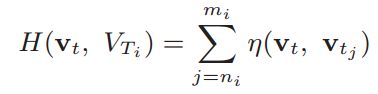
如果Vt’是最佳,则检查:
![]()
即如果该组相似度成立,那么当前帧的前一帧和最佳匹配的前一帧也应该成立….前k帧和最佳匹配前k帧也成立的话,则取出则k帧中最佳的一对(应该就是当前帧与最佳匹配)
几何一致有效性
对回环检测到的图像对进行几何约束校验。具体细节论文 [3] [ 3 ] 没有细说,但基本逻辑应该是先计算一个基础矩阵F,再根据F验证满足d(x1,F,x2)小于某阈值(即满足集合约束)的点对(x1,x2)占所有特征点的比例是否足够高。
上述过程中,首先需要得带特征点对。先提取当前帧It的特征,再由顺序索引查找出匹配帧It’中所有l(l由所需特征数目决定)层中的节点,将这两张图像相同节点下的特征分别进行匹配。
在这些匹配点挑选12个点对生成一个基础矩阵,并利用RANSAC算法不断优化这个基础矩阵。最后利用这个基础矩阵来验证
有时也采用投票机制选取候选者,加速搜索。
参考并致谢:
1.TF-IDF与余弦相似性的应用(一):自动提取关键词
2.浅谈回环检测中的词袋模型(bag of words)
3. Gálvez-López D, Tardós J D. Real-time loop detection with bags of binary words[C]// Ieee/rsj International Conference on Intelligent Robots and Systems. IEEE, 2011:51-58.