数据结构之哈弗曼编码的(Huffman Coding)加密解密压缩
Huffman树又叫最优二叉树,它的特点是带权路径最短。
Huffman树的一个重要应用是Huffman编码,Huffman编码是长度最短的前缀编码。即给定要传送的字符的权值,根据权值求出Huffman编码,它一定是前缀编码(指任意字符的编码都不是另一个字符编码的前缀),并且在传送过程由字符组成的文字时,编码长度最小。
因此Huffman编码可以对文字进行加密解密还有压缩。加密的工作就是将文字转换为编码,解密工作是将编码转换为文字,如何转换本文不做详解(严蔚敏的《数据结构》书中有代码)。那么如何进行压缩?当字符转变为编码,如果数字编码用char数组存储,则size并未减少。因此我们考虑用位操作。
由于编码完成后,码的形式是0和1组成的串,因此按位存储比原来将节省空间,假设平均编码长度为5位(若平均编码长度超过8位则没有压缩效果了,毕竟char是一个字节,但不可能超过8位,因为根据Huffman编码性质编码长的出现频率低,编码短的出现频率高,后面结果也得到了验证),则64位8个字节可以存储12.8个字符,而char只能存储8个字符。因此文字得到了压缩。
整个程序执行过程如图所示:

其中最难的是writeFile,利用位操作将编码组合在一起并写入文件,这里我们定义一个Unit单元,它包含64位数据,每次编码塞满64位数据,则写入文件。
按照上面的思想,写成的代码如下:
// HuffmanCode.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include 程序的执行结果如下图:
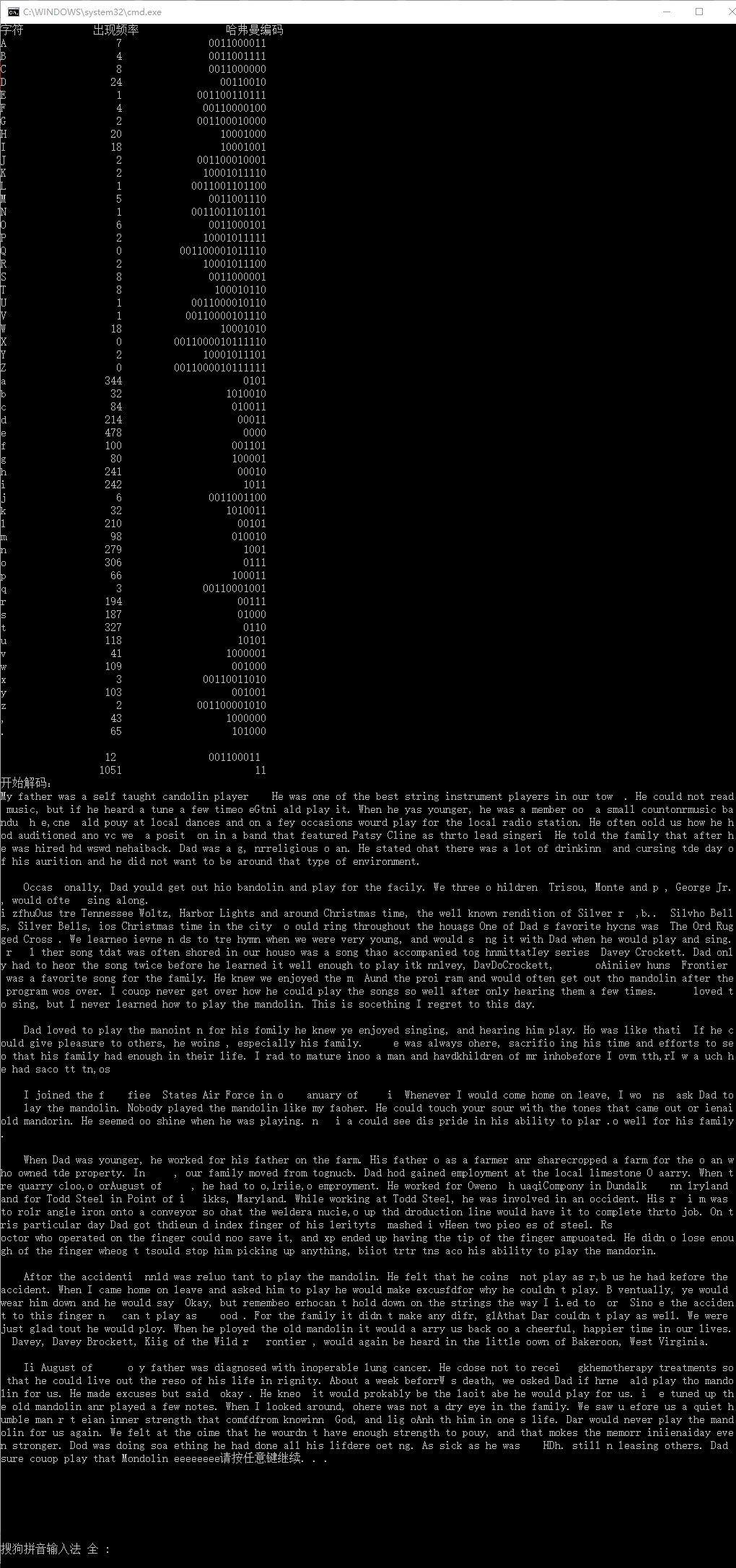
![]()
可以看到整篇文章的确进行了压缩(从6KB->3KB)。这里出现了一个小问题,最后多输出了eeeeeeee。由于我们是以64位为一个单元进行写入的,当最后一个单元不满64时,我们以0进行填充,而e的编码为0000,所以最后一个单元剩余的内容都被解析成了e。
解决方法可以在增加一个字符“截止符”,并和其他字符一起计算Huffman码,当写完最后一个单元的时候将截止符也写入,解码过程中若碰到“截止符”则跳出函数,不再解码。