关于可持久化并查集的学习和思考
鉴于noip比赛前集训时SAKER前辈教了我这个蒟蒻可持久化线段树以来,我懂得了如何维护一个支持历史查询的线段树。于是我就开始异想天开了:可不可以快速维护一个支持历史查询的数组呢?
就在这时,我上网看到了一个新的算法:可持久化并查集。先用例题来讲吧:
BZOJ3674:可持久化并查集加强版
Description:
自从zkysb出了可持久化并查集后……
hzwer:乱写能AC,暴力踩标程
KuribohG:我不路径压缩就过了!
ndsf:暴力就可以轻松虐!
zky:……
n个集合 m个操作
操作:
1 a b 合并a,b所在集合
2 k 回到第k次操作之后的状态(查询算作操作)
3 a b 询问a,b是否属于同一集合,是则输出1否则输出0
请注意本题采用强制在线,所给的a,b,k均经过加密,加密方法为x = x xor lastans,lastans的初始值为0
0
题目分析:
本题要求强制在线操作,于是我们很容易想到暴力:维护m个大小为n的fa数组,在每做完一步后都记录一下每个点的fa,(可以使用路径压缩),然后该返回第k步的时候就返回那个数组,时间为O(n*m)。
然而这样会超时,炸空间。要在规定时间内求解我们有三种算法:
一. 分块(这不是本文要重点讨论的算法)
分块算法是一种比较常见的算法。对于本题,我们只需要维护sqrt(m)个大小为n的fa数组,分别记录在完成sqrt(m),2*sqrt(m)……m步后fa数组的状态。然后要跳回去的时候只需要O(sqrt(m))的时间就行了,这样可以使用路径压缩。时空复杂度均为O(m*sqrt(m))左右。
二. 可持久化线段树,且不使用路径压缩。
我们来看一下,如果不使用路径压缩的话,对于每一次合并,我们只会改变fa数组中的一个值(注意:每一次改的地方都不同),其他的值都和它们的历史版本一样:
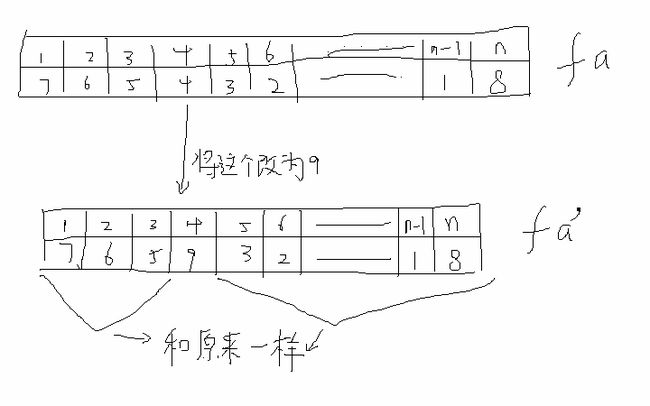
也就是说,我们要快速地让1到3,5到n快速地指向它的历史版本。不使用路径压缩的可持久化并查集,本质上就是要维护一个支持单点修改和历史版本查询的数组。
经过在下翻阅众多网上大神的做法,他们基本上都开了一棵可持久化线段树,这棵线段树的非叶子节点i只负责维护lson和rson,不维护除此之外的任何信息,它的作用是方便我们在修改的时候快速地将[Li,Ri]这一段O(1)地指向它的历史版本。
我们可以使用启发式合并,这样找一个节点所在集合的根,就需要查询log(n)次线段树,而每一次时间都是log(n),故时间为O(m*log^2(n)),空间为m*log(n)。
接下来就是本人的一些思考:时间为O(m*log^2(n)),线段树的常数又这么大,时间和分块没什么区别呀。该线段树每一次查询保证是log(n)的,每一次查询只有查询到叶子节点才能得出答案,能不能让常数小一点呢?
我们先假设用链表储存fa数组,这样当我们修改fa[x]的值的时候,我们需要O(x)的时间与和时间成正比的空间,如图:

我们要修改fa[3],就要一路开新的节点,最后让fa[3]的后继指向4。
那么问题很明显了,我们要在不改变链表储存方式的前提下,尽可能快速地到达任意一个节点,于是本人想到可以把这个链表变得“紧凑”一些,成为一棵树:
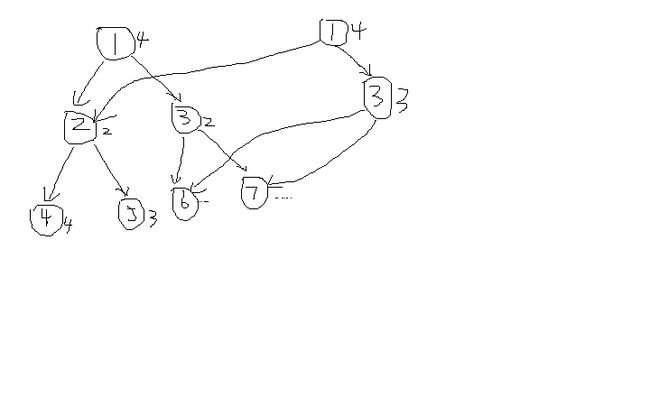
注意,这和线段树不同,它的每一个节点就是原链表中的一个元素。这样我们要修改元素x的时候,时空均为O(floor(log(x))+1)。
那么怎样走才能到5号节点呢?我们发现(5)10=(101)2,故最开始是1,即为一号节点,第二位是0,故往左子树走,接下来是1,走右子树。我们可以发现,2的子树转化成二进制位后都是10开头的,因为2往下走一层,无非就是在2的二进制位后面加了一个0或1,故这样走正确性显然。
然而这只是常数级别的优化罢了,相当于线段树的常数变成树状数组的常数而已。
三. 使用路径压缩。
理论时空是O(m*n*log(n)),然而实际运行只比启发式合并慢那么一点点……
附bzoj3674CODE(已AC):
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
const int maxn=200100;
const int maxl=20;
struct data
{
int lson,rson,id,val,_Size;
} tree[maxn+2*maxn*maxl];
int Root[maxn];
int cur;
int w[maxn];
int n,m,lt,nt,lans;
void Build(int x)
{
tree[x].id=x;
tree[x].val=x;
tree[x]._Size=1;
int left=x<<1;
if (left<=n)
{
tree[x].lson=left;
Build(left);
}
int right=left|1;
if (right<=n)
{
tree[x].rson=right;
Build(right);
}
}
data Query(int root,int L,int x)
{
if (x==L) return tree[root];
if (x&(1<<(w[x]-w[L]-1))) return Query(tree[root].rson,L*2+1,x);
else return Query(tree[root].lson,L*2,x);
}
data Find_fa(int x)
{
data y=Query(Root[lt],1,x);
while (y.id!=y.val) y=Query(Root[lt],1,y.val);
return y;
}
void Update(int root,int L,int x,int nid,int v)
{
if (L==x)
{
if (nid==0) tree[root].val=v;
else tree[root]._Size=v;
return;
}
if (x&(1<<(w[x]-w[L]-1)))
{
data temp=tree[ tree[root].rson ];
tree[root].rson=++cur;
tree[cur]=temp;
Update(cur,L*2+1,x,nid,v);
}
else
{
data temp=tree[ tree[root].lson ];
tree[root].lson=++cur;
tree[cur]=temp;
Update(cur,L*2,x,nid,v);
}
}
void Add(int x,int y)
{
data fx=Find_fa(x);
data fy=Find_fa(y);
if (fx.val==fy.val)
{
Root[nt]=Root[lt];
return;
}
if (fx._Size>fy._Size) swap(fx,fy);
Root[nt]=++cur;
tree[cur]=tree[ Root[lt] ];
Update(cur,1,fx.id,0,fy.id);
tree[++cur]=tree[ Root[nt] ];
Root[nt]=cur;
Update(cur,1,fy.id,1,fx._Size+fy._Size);
}
int main()
{
freopen("c.in","r",stdin);
freopen("c.out","w",stdout);
scanf("%d%d",&n,&m);
Build(1);
Root[1]=1;
cur=n;
lt=1,nt=1;
lans=0;
w[1]=1;
for (int i=2; i