Ideas For Weakly Supervised Object Localization
Ideas For Weakly Supervised Object Localization
最近开始跟着师兄做弱监督学习和医疗影像,近日阅读了几篇文章,与 Object Localization 相关,它们都是基于 Learning Deep Features for Discriminative Localization 这篇文章提出的 class activation maps (CAM),只使用了 image-level 的图片标注,训练一个分类模型,即可达到与 Fully Supervised Object Localization 媲美的效果。
那么何为 CAM 呢?
CAM
前几年的深度学习模型 AlexNet, VGGNet 和 GoogLeNet 等,在一系列卷积层后接几层的全连接层,这样可以提高分类性能,但这部分却是占了整个模型的大部分参数,同时,全连接层的使用要求模型的输入尺寸需一致,这会带来诸多不便。在这之前,已经有人用 Global Max Pooling 来将最后一层卷积层的输出 S ∈ R H × W × C S\in R^{H\times W\times C} S∈RH×W×C 统一变换为 S ′ ∈ R 1 × 1 × C S'\in R^{1\times1\times C} S′∈R1×1×C,这样无论输入的尺寸如何,最后的分类层(全连接层)参数都可以统一设置为 W ∈ R C × K W\in R^{C\times K} W∈RC×K, K K K 为总的类别数。而这篇文章中,使用的是 Global Average Pooling,作者提到的优点,咱也不敢问咱也不敢猜,但其主要目的还是能够推导出 class activation maps (CAM)。
记 f k ( x , y ) f_k(x,y) fk(x,y) 为最后一层卷积层第 k 个卷积核,则 F k = ∑ x , y f k ( x , y ) F^k=\sum_{x,y}f_k(x,y) Fk=∑x,yfk(x,y) 为该卷积核的输出。对于类别 c 的 Softmax 输入为 S c = ∑ k w k c F k S_c=\sum_kw_k^cF_k Sc=∑kwkcFk,其中 w k w_k wk 是对应 F k F^k Fk 的权重,将 S c S_c Sc 展开:
S c = ∑ k w k c ∑ x , y f k ( x , y ) = ∑ x , y ∑ k w k c f k ( x , y ) S_c=\sum_kw_k^c\sum_{x,y}f_k(x,y)=\sum_{x,y}\sum_kw_k^cf_k(x,y) Sc=k∑wkcx,y∑fk(x,y)=x,y∑k∑wkcfk(x,y)
我们将 M c M_c Mc 定义为在 ( x , y ) (x,y) (x,y) 处对于类别 c 的 class activation map:
M c ( x , y ) = ∑ k w k c f k ( x , y ) M_c(x,y)=\sum_kw_k^cf_k(x,y) Mc(x,y)=k∑wkcfk(x,y)
因此, S c S_c Sc 可以表示为 ∑ x , y M c ( x , y ) \sum_{x,y}M_c{(x,y)} ∑x,yMc(x,y) ,即 M c ( x , y ) M_c(x,y) Mc(x,y) 可以表示在 ( x , y ) (x,y) (x,y) 处特征对类别 c 的重要程度。可以看看下面这个图,非常直观:

非常棒的一点是:代码是开源的!
- caffe version
- pytorch version
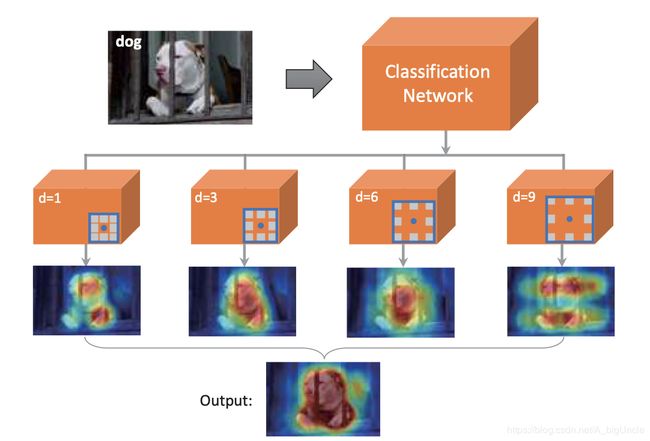
现在了解 CAM 后,我们不难想到,既然分类模型能够通过 CAM 定位到识别特定类别的区域(上图中较亮部分),那么我们其实可以通过这个区域生成 BBox 来完成 Object Localization 任务。而我近期阅读的几篇文章里,也正是用到了这个想法,现在写出来分享一下。
Unified DCNN Framework
Paper: (CVPR17)
ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases
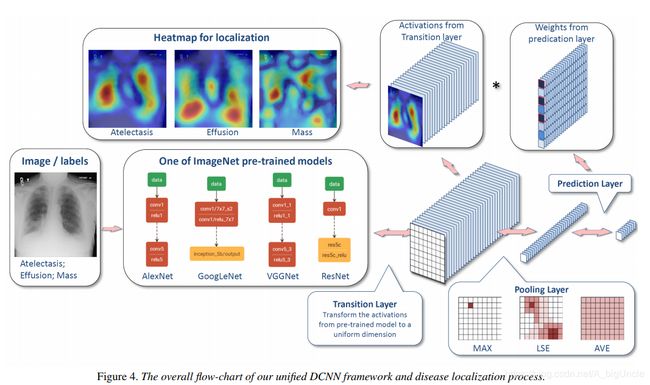
说实话,这个名字可能不太准确,不过在这篇文章中提出来的模型,确实没什么亮点,只是相比 CAM 这篇文章中用到的 GAP,它用的是 Log-Sum-Exp Pooling:
x p = 1 r ⋅ [ 1 S ⋅ ∑ ( i , j ) ∈ S e x p ( r ⋅ x i j ) ] x_p=\frac{1}{r}\cdot [\frac{1}{S}\cdot \sum_{(i,j)\in\mathbf{S}}exp(r\cdot x_{ij})] xp=r1⋅[S1⋅(i,j)∈S∑exp(r⋅xij)]
它的作用由超参数 r r r 来控制,当 r → 0 r\to0 r→0 相当于 GAP,而当 r → ∞ r\to\infin r→∞ 相当于 GMP,具体证明可以看我写的另一篇文章:Log-Sum-Exp Pooling。
Attention-based Dropout Layer (ADL)
Paper: (CVPR19)
Attention-based Dropout Layer for Weakly Supervised Object Localization

如果只使用 CAM,从前面文章中的图可以看到,其实模型还是聚焦于对分类最具判别信息的区域,这样得出的 BBox 还是没能圈出整个物体,如人的话只圈出人脸。为了让模型能识别对分类有帮助的但不那么明显的区域,最简单的想法就是将最显著的区域遮掉,这样会迫使模型去激活那些不那么显著但有用的区域。但是如果在训练过程中,总是将显著区域遮掉,那么模型可能会对无用区域过拟合导致分类性能下降,作者为了解决这个问题,随机选择是否启用遮挡。
AM
Paper: (MICCAI18)
Iterative Attention Mining for Weakly Supervised Thoracic Disease Pattern Localization in Chest X-Rays
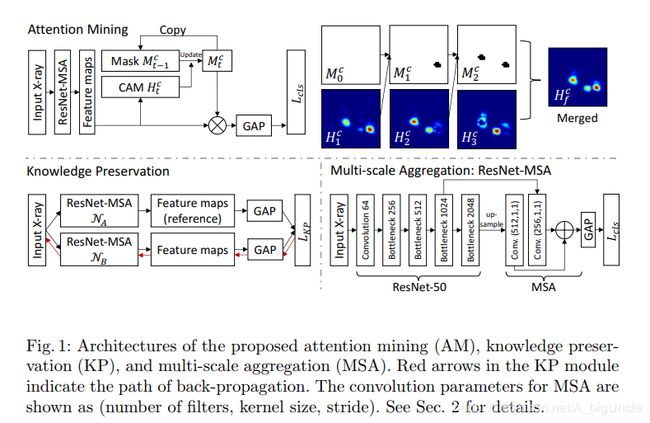
这篇文章中一个想法与上一篇一致,同样是让模型去学习那些不那么明显的区域,作者将其叫做 Iterative Attention Mining。记类别 c 对应初始掩码为 M 0 c M_0^c M0c,其值全置为1,模型会执行 T 次AM,每次的 CAM 通过以下方式生成:
H t c = ( X ⊙ M ^ t − 1 c ) w c H_t^c=(X\odot\hat{M}^c_{t-1})w^c Htc=(X⊙M^t−1c)wc
其中 X ∈ R N × W × H × D X\in R^{N\times W\times H \times D} X∈RN×W×H×D 为输入 AM 的特征图, N , W , H , D N, W, H, D N,W,H,D 分别对应 batch size,width,height 和 channel。对 H t c H_t^c Htc normalized 至 [ 0 , 1 ] [0,1] [0,1]并使用0.5作为阈值进行二值化,通过找到二值化后的 H t c H_t^c Htc 中全局最大值的连通图 R R R,然后生成下一步的掩码 M t c M_t^c Mtc,其除了 R R R 中值设为0,其它位置从上一步的掩码复制。生成的 CAMs 最后要合并成最终的热力图 H f c H_f^c Hfc,作者选择的方式是取平均,但后面生成的热力图都存在一些被挖掉的区域,所以需要将其填上, H f c H_f^c Hfc 由下式计算:
H f c = 1 T ∑ t = 1 T [ H t c + ∑ t ′ = 1 t − 1 ( H t ′ c ⊙ M ˉ t ′ c ) ] H_f^c=\frac{1}{T}\sum_{t=1}^T[H_t^c+\sum_{t'=1}^{t-1}(H^c_{t'}\odot\bar{M}^c_{t'})] Hfc=T1t=1∑T[Htc+t′=1∑t−1(Ht′c⊙Mˉt′c)]
其中, M ˉ t c = ( 1 − M t c ) \bar{M}^c_t=(1-M^c_t) Mˉtc=(1−Mtc)
2019.08.24 更新
这几个星期又读了十来篇文章,主要是弱监督学习和半监督学习的,其中有一些是做目标检测、语义/实例分割的,但是就方法思路来看,大家都是基于前面提到的 CAM 进行各种改进,于是乎我决定记录下来作为思路补充吧。
Dilated Convolution
Paper: (CVPR18)
Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi-Supervised Semantic Segmentation
Dilated Convolution 这种卷积其实并不是这篇文章首次提出的,文章题目中也说到了 revisiting,什么是 Dilated Convolution 呢,请看下面一个动图(蓝色为Input,青色为Output):
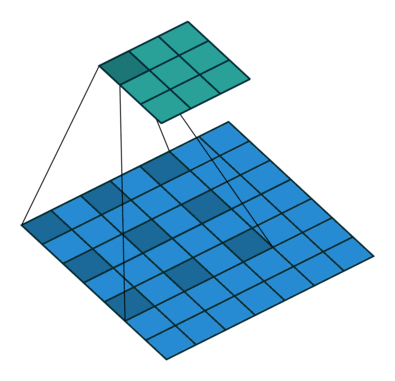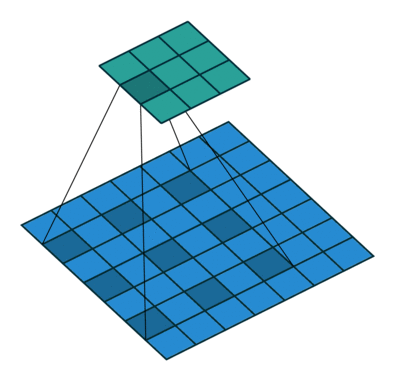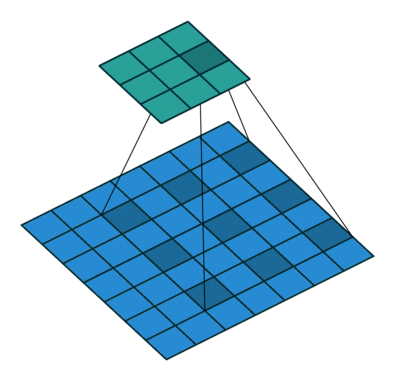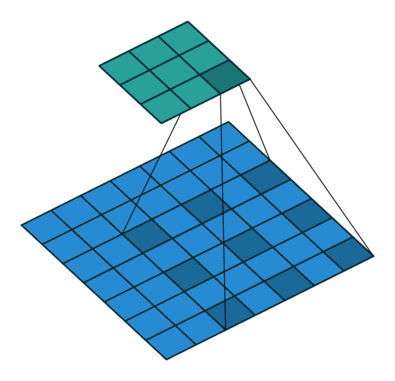
其一个重要的作用就是增大感受野,具体的解析可以看看逼乎上的 如何理解空洞卷积(dilated convolution)?
上面这个卷积动图来自Github上的一个项目:Convolution arithmetic,强烈推荐~
先看看文章提出的模型:
其实也就是在 Backbone 后面接了多种 dilated rates 的 Dilated Convolution,直观上来说,这种卷积在不用叠加多层 3x3 的普通卷积情况下增大 feature map 单个像素的感受野,这样做的好处是参数量少了,也使网络更易优化。作者的观点是,在提取的 feature map 上,那些 non-discriminative 的区域上的像素,通过 Dilated Convolution 的大感受野,能够获取在它旁边 discriminative 区域的信息,并使该像素被激活。在提取到多个 CAM 后,作者将其融合得到最终的 CAM。
说到这里,可能有些同学想到了 Non-local Neural Networks,non-local 可以捕获长距离(空间、时间)的语义信息,这两篇文章都是出自 CVPR18,不存在借鉴之嫌,只能说殊途同归吧。
SPG
Paper: (ECCV18)
Self-produced Guidance for Weakly-supervised Object Localization

上面这个图中,分为几个模块:A、B、C,其中 A 是分类网络的一部分,B 的输入为从 A 中的各层提取不同 level 的 feature maps,输出为不同质量的 guidance maps,C 的输入为 B 输出的不同 guidance maps 融合后的 map,对 A 的进行辅助监督。B、C模块其实就是在辅助 Image-level Labels 来训练网络,挖掘一些 non-discriminative 的区域以提取更完整的物体轮廓。 这里辅助监督信号是像素级别的,我个人认为如果用在 localization 任务上太重了,但是这篇文章是做语义分割的,就另当别论了。
总结
上面几篇文章中,还有一些别的创新点值得一提,但写着写着总觉得很累,后面再补补吧,后续会继续看一些图像分割的文章,到时也会记录一下,与大家分享。