大数据入门学习笔记(捌)- Hadoop项目实战
文章目录
- 用户行为日志概述
- 日志数据内容:
- 数据处理流程
- 项目需求
- 测试
- 功能实现
用户行为日志概述
用户行为日志:用户每次访问网站时所有的行为数据(访问、浏览、搜索、点击…)
用户行为轨迹、流量日志
日志数据内容:
百条测试数据链接地址:https://download.csdn.net/download/bingdianone/10800924
每行日志如下:
117.35.88.11 - - [10/Nov/2016:00:01:02 +0800] “GET /article/ajaxcourserecommends?id=124 HTTP/1.1” 200 2345 “www.imooc.com” “http://www.imooc.com/code/1852” - “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36” “-” 10.100.136.65:80 200 0.616 0.616
- 访问的系统属性: 操作系统、浏览器等等
- 访问特征:点击的url、从哪个url跳转过来的(referer)、页面上的停留时间等
- 访问信息:session_id、访问ip(访问城市)等
数据处理流程
-
数据采集
Flume: web日志写入到HDFS -
数据清洗
脏数据
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
清洗完之后的数据可以存放在HDFS(Hive/Spark SQL) -
数据处理
按照我们的需要进行相应业务的统计和分析
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架 -
处理结果入库
结果可以存放到RDBMS、NoSQL -
数据的可视化
通过图形化展示的方式展现出来:饼图、柱状图、地图、折线图
ECharts、HUE、Zeppelin
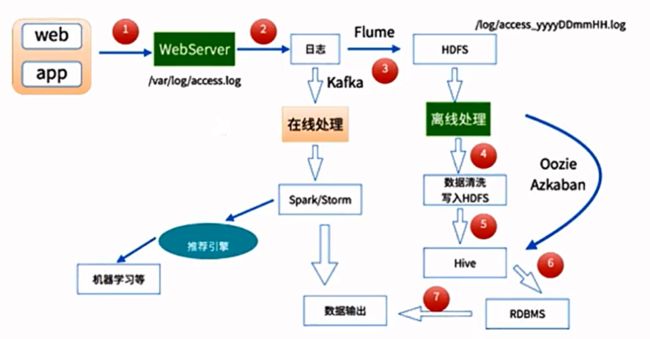
本实战只有mapreduce清洗和处理离线数据
项目需求
需求:统计一个网站访问日志的浏览器访问次数
- 根据日志信息抽取出浏览器信息
https://github.com/LeeKemp/UserAgentParser
这个插件是可以满足本条需求;需要下载编译

编译:

安装到本地maven仓库
将依赖加入pom文件中
<dependency>
<groupId>com.kumkeegroupId>
<artifactId>UserAgentParserartifactId>
<version>0.0.1version>
dependency>
- 针对不同的浏览器进行统计操作
测试
环境参考,接上博文大数据入门学习笔记(叁)- 布式文件系统HDFS 中的环境
package com.kun.hadoop.project;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
/**
* UserAgent测试类
*/
public class UserAgentTest {
public static void main(String[] args) {
String source="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36";
UserAgentParser userAgentParser = new UserAgentParser();
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser();//浏览器
String engine = agent.getEngine();//引擎
String engineVersion = agent.getEngineVersion();//引擎版本
String os = agent.getOs();//操作系统
String platform = agent.getPlatform();//平台
boolean mobile = agent.isMobile();//移动
System.out.println(browser+ ","+engine+ ","+engineVersion+ ","+os+ ","+platform+ ","+mobile);
//Chrome,Webkit,537.36,Windows 7,Windows,false
}
}
/**
* 本地测试聚合计算浏览器分类个数
* @throws Exception
*/
@Test
public void testReadFile() throws Exception{
String path="D:\\SoftWare\\myGit\\hadoop-train\\100-access.log";
BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(new File(path)))
);
String line="";//此字符串不代表null值
Map<String, Integer> browserMap = new HashMap<String, Integer>();//浏览器类型和出现次数
UserAgentParser userAgentParser = new UserAgentParser();
while (line!=null){
line = reader.readLine();//一次读入一行数据
if (StringUtils.isNotBlank(line)){//判断这一行是否为空
String source = line.substring(getCharacterPosition(line, "\"", 7)+1);
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser();//浏览器
String engine = agent.getEngine();//引擎
String engineVersion = agent.getEngineVersion();//引擎版本
String os = agent.getOs();//操作系统
String platform = agent.getPlatform();//平台
boolean mobile = agent.isMobile();//移动
Integer browserValue=browserMap.get(browser);
if(browserValue!=null){
browserMap.put(browser,browserMap.get(browser)+1);
}else{
browserMap.put(browser,1);
}
System.out.println(browser+ ","+engine+ ","+engineVersion+ ","+os+ ","+platform+ ","+mobile);
/*
部分结果
Unknown,Unknown,null,Unknown,Android,true
Unknown,Unknown,null,Linux,Linux,false
Chrome,Webkit,537.36,Windows 7,Windows,false
*/
}
}
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
for(Map.Entry<String, Integer> entry:browserMap.entrySet()){
System.out.println(entry.getKey()+":"+entry.getValue());
}
/*
Unknown:78
Chrome:20
Firefox:2
*/
}
/**
* 测试自定义方法
*/
@Test
public void testGetCharacterPosition(){
String value="117.35.88.11 - - [10/Nov/2016:00:01:02 +0800] \"GET /article/ajaxcourserecommends?id=124 HTTP/1.1\" 200 2345 \"www.imooc.com\" \"http://www.imooc.com/code/1852\" - \"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36\" \"-\" 10.100.136.65:80 200 0.616 0.616\n";
int characterPosition = getCharacterPosition(value, "\"", 7);
System.out.println(characterPosition);//158
}
/**
* 获取指定字符串中指定标识的字符串出现的索引位置
* @param value
* @param operator
* @param index
* @return
*/
private int getCharacterPosition(String value,String operator,int index){
Matcher matcher = Pattern.compile(operator).matcher(value);
int mIdx=0;
while (matcher.find()){
mIdx++;
if(mIdx== index){
break;
}
}
return matcher.start();
}
功能实现
package com.kun.hadoop.project;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 使用MapReduce聚合计算浏览器分类个数
*/
public class LogApp {
/**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
LongWritable one = new LongWritable(1);
private UserAgentParser userAgentParser ;
//Called once at the beginning of the task.只会创建一次
@Override
protected void setup(Context context) throws IOException, InterruptedException {
new UserAgentParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据:其实就是一行日志信息
String line = value.toString();
String source = line.substring(getCharacterPosition(line, "\"", 7)+1);
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser();//浏览器
// 通过上下文把map的处理结果输出
context.write(new Text(browser), one);
}
@Override//销毁对象userAgentParser
protected void cleanup(Context context) throws IOException, InterruptedException {
userAgentParser=null;
}
}
/**
* 获取指定字符串中指定标识的字符串出现的索引位置
*/
private static int getCharacterPosition(String value,String operator,int index){
Matcher matcher = Pattern.compile(operator).matcher(value);
int mIdx=0;
while (matcher.find()){
mIdx++;
if(mIdx== index){
break;
}
}
return matcher.start();
}
/**
* Reduce:归并操作
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values) {
// 求key出现的次数总和
sum += value.get();
}
// 最终统计结果的输出
context.write(key, new LongWritable(sum));
}
}
/**
* 定义Driver:封装了MapReduce作业的所有信息
*/
public static void main(String[] args) throws Exception{
//创建Configuration
Configuration configuration = new Configuration();
// 准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath, true);
System.out.println("output file exists, but is has deleted");
}
//创建Job
Job job = Job.getInstance(configuration, "wordcount");
//设置job的处理类
job.setJarByClass(LogApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//设置map相关参数
job.setMapperClass(LogApp.MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(LogApp.MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
注意:打包的时候pom文件的更改
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.kun.hadoopgroupId>
<artifactId>hadoop-trainartifactId>
<version>1.0-SNAPSHOTversion>
<name>hadoop-trainname>
<url>http://www.example.comurl>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<hadoop.version>2.6.0-cdh5.7.0hadoop.version>
<maven.compiler.source>1.7maven.compiler.source>
<maven.compiler.target>1.7maven.compiler.target>
properties>
<repositories>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>com.kumkeegroupId>
<artifactId>UserAgentParserartifactId>
<version>0.0.1version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.11version>
<scope>testscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<archive>
<manifest>
<mainClass>mainClass>
manifest>
archive>
<descriptorRefs>
<descriptorRefs>jar-with-dependenciesdescriptorRefs>
descriptorRefs>
configuration>
plugin>
plugins>
build>
project>
打包命令:mvn assembly:assembly

传到服务器运行即可;注意集群运行方式前面mapreduce章节有介绍。
其他需求雷同上诉方法
如 操作系统、浏览器内核、终端类型等等都可以通过UserAgent解析的依赖拿到。