大数据入门学习笔记(肆)-分布式资源调度YARN
文章目录
- YARN产生背景
- YARN概述
- YARN架构
- Yarn 基本思想
- Yarn 计算资源抽象
- YARN执行流程
- 分步流程图
- Yarn各个组件之间的心跳信号
- Yarn资源隔离策略
- Yarn容错处理
- Yarn调度器和调度算法
- FIFO调度器
- Capacity Scheduler资源调度器
- Capacity Scheduler配置
- Capacity Scheduler资源分配算法
- Fair Scheduler资源调度器
- Fair Scheduler - FAIR资源分配算法
- Capacity Scheduler和Fair Scheduler对比
- YARN环境搭建
- Yarn常用命令介绍
- 提交作业到YARN上执行
- 常见基于Yarn的计算框架
- MapReduce On Yarn
- Spark
- Spark On Yarn
YARN产生背景
- MapReduce1.x存在的问题:单点故障&节点压力大不易扩展,如下图:
-
单点故障:整个集群里只有一个JobTracker,一旦挂掉,整个架构就无法完成作业运行
-
节点压力大不易扩展:JobTracker要来自TaskTracker的rpc请求(心跳)和client的提交查询请求;随着集群的扩展,当集群越来越大的时候TaskTracker就会成为一个瓶颈不易扩展,压力很大
- 每个Slave机器可运行的最大Map tasks数量和Reduce tasks数量固定
-
不能够支持除了mapreduce意外的框架:JobTracker承载的任务比较多;整个架构只能支持mapreduce作业,不支持storm,spark作业。
- 难以共享集群资源
- Spark Strom Impala

(MapReduce:Master/Slave架构,1个JobTracker带多个TaskTracker)
-
JobTracker: 负责资源管理和作业调度,任务分配
-
TaskTracker:定期向JT汇报本节点的健康状况、资源使用情况、作业执行情况;接收来自JT的命令:启动任务/杀死任务
在1中;资源叫slot;每台节点只有获取到了slot才可以启动多少个map和多少个reduce;不能够指定cpu资源;启动后也不可更改资源。比较粗糙;难以共享集群资源。

MapReduce V1 执行job流程


2. 资源利用率(CPU;内存;存储IO-集群之间的数据交互)&运维成本,如下图:

3. 催生了YARN的诞生
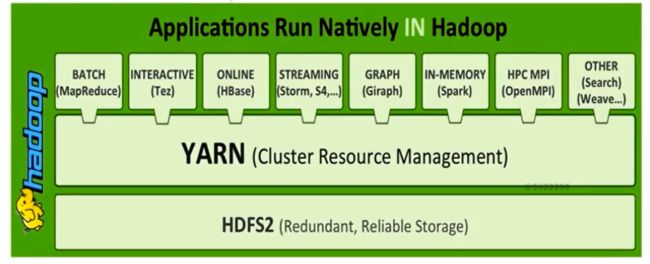
YARN:不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度
XXX on YARN的好处:(XXX: Spark/MapReduce/Storm/Flink)
与其他计算框架共享集群资源,按资源需要分配,进而提高集群资源的利用率
YARN概述
- 从Hadoop 2.0开始出现了Yarn
- Yet Another Resource Negotiator (另一个种资源协调者)
- 通用的资源管理系统
- 为上层应用提供统一的资源管理和调度

ResurceManager(RM):
RM是一个全局的资源管理器,集群只有一个,负责整个系统的资源管理和分配,包括处理客户端请求、启动/监控APP master、监控nodemanager、资源的分配与调度。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
- 为上层应用提供统一的资源管理和调度
调度器
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。需要注意的是,该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。此外,该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
YARN架构

YARN架构:
- ResourceManager: RM(通常会另外部署一个standby来解决单点故障)
- 一个集群只有一个,全局的资源管理器
- 处理客户端的请求: 提交一个作业、杀死一个作业
- 监控Node Manger,汇总上报的资源
- 根据请求分配资源
- NodeManager: NM
- 每个从属节点一个
- 管理自身所属节点的资源
- 监控资源使用情况(cpu, memory, disk,network)并向Resource Manager汇报
- 接收并处理来自RM的各种命令:启动Container
- 处理来自AM的命令
- 单个节点的资源管理
- ApplicationMaster: AM
- 每个应用程序对应一个:MR、Spark,负责应用程序的管理
- 为应用程序向RM申请资源(core、memory),分配给内部task
- 需要与NM通信:启动/停止task,task是运行在container里面,AM也是运行在container里面
- Container
- 封装了CPU、Memory等资源的一个容器
- 是一个任务运行环境的抽象
- Client
- 提交作业
- 查询作业的运行进度
- 杀死作业
通常NodeManager会和DataNode混合部署,why?
可以从内存、cpu、磁盘的使用来讲。

Yarn 基本思想
- 在MapReduce V1中
- JobTracker = 资源管理器 + 任务调度器
- 在Yarn中做了切分
- 资源管理
- 让ResourceManager负责
- 任务调度
- 让ApplicationMaster负责
- 每个作业启动一个
- 根据作业切分任务tasks
- 向Resource Manager申请资源
- 与NodeManager协作,将分配申请到的资源给内部任务tasks
- 监控tasks运行情况,重启失败的任务
- 让ApplicationMaster负责
- 资源管理
- JobHistoryServer
- 每个集群每种计算框架一个
- 负责搜集归档所有的日志
Yarn 计算资源抽象
- 在Yarn中,计算资源被抽象为Container
- 每个Container描述:
- 可使用的CPU资源和内存资源
- 执行命令
- 环境变量
- 外部资源
- 如何获得运行各个任务的Container?
- 由ApplicationMaster向ResourceManager申请
- ApplicationMaster本身也运行在一个Container,这个Container由ResourceManager向自身申请启动
- 如何启动运行?
- 向Container所属的Node Manager发起运行

上图中一个core并不代表一个cpu;它是衡量cpu计算能力的一个单位;比如早期的物理机cpu计算能力差就按照1:1来算core,一个cpu相当于一个core;而后期新买的物理机计算能力强1:2来算core,一个cpu相当于两个core。
YARN执行流程

- 用户向yarn提交一个作业
- RM为该作业分配第一个container(AM)
- RM会与对应的NM通信,要求NM在这个container上启动应用程序的AM
- AM首先向RM注册,然后AM将为各个任务申请资源,并监控运行情况;AM采用轮训的方式通过RPC协议向RM申请和领取资源;AM所需要的资源有多少个core有多个memory到RM进行申请,申请到后返回给AM
- AM申请到资源以后,便和相应的NM通信,要求NM启动任务,任务都是以Container方式运行的。
- NM启动我们作业对应的task;有几个task就启动几个Container
- 任务开始计算进入MapReduce阶段
分步流程图
1、client将程序打包提交到RM运行。

2、RM找一台空闲的机器启动一个Container,为了启动AM(一个Container启动一个AM)。

3、Container进而启动AM,每来一个作业都会启动一个AM

4、AM向RM汇报已到位,开始切分任务启动多少个map和reduce所需要的资源,封装成ResourceRequest对象来提交给RM;RM获取对象后并如果资源不够不会立刻给出所有资源,因为集群是繁忙的,当前可能只有20g的空闲内存,RM会慢慢收集其他作业释放的资源,直到100G。(如何解决这个等待策略,可以通过优先级来解决)
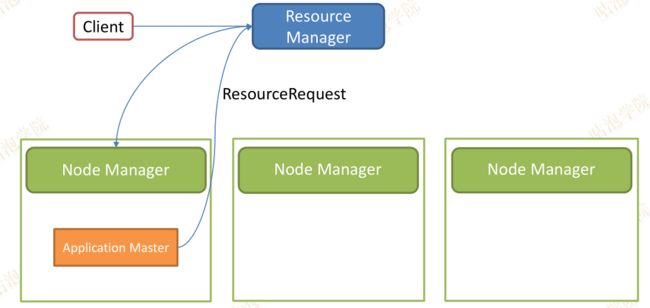
5、当RM把资源分配个AM的时候,当前的AM就可以启动当前任务;联系有空闲资源的nodemanager来完成任务;把请求封装到COntainerLaunchContext对象里传递给NodeManager。

6、NodeManager接受到请求之后就会把Container启动起来。

7、运行当前的Task
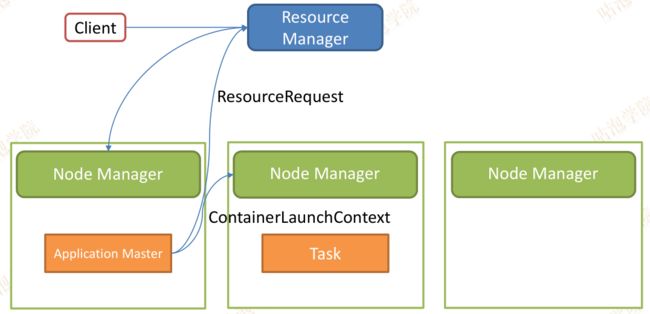
8、因为有若干个map,所以ApplicationMaster向空闲的NodeManager会继续申请资源。
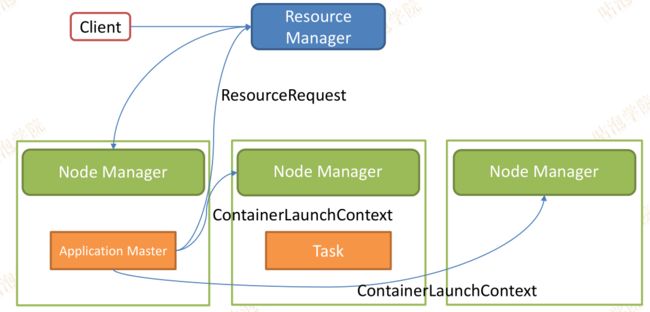
9、task里运行的map还是reduce都是由AM来指挥的。

10、每个task会以心跳机制来向ApplicationMaster来汇报作业当前的运行情况。有特别情况会进行重启,或者进行全部作业重启,这些都是ApplicationMaster来管理的。

Yarn各个组件之间的心跳信号
- Application Master与Resource Manager心跳
- AM->RM
- 对Container的资源需求(CPU和Memory)和优先级
- 已用完等待回收的Container列表
- RM->AM
- 新申请到的Container
- 已完成Container的状态
- AM->RM
- Application Master与Node Manager心跳
- AM -> NM
- 发起启动Container请求
- NM -> AM
- 汇报Container状态
- AM -> NM
- Node Manager与Resource Manager心跳
- NM->RM
- Node Manager上所有的Container状态
- RM->NM
- 已删除和等待清理的Container列表
- NM->RM
Yarn资源隔离策略
- 内存资源隔离
- 基于线程监控方案(优点:如果瞬间超过设定上限不会立马被kill掉)
- 基于cgroups(linux里的资源轻量级方案,如果超过上限会立马被kill掉)
- CPU资源隔离
- 默认不对CPU资源进行隔离
- 基于cgroups

Yarn容错处理
- 失败类型
- 程序失败 进程奔溃 硬件问题
- 如果作业失败了
- 作业异常均会汇报给Application Master
- 通过心跳信号检查挂住的任务
- 一个作业的任务失败比例超过配置,就会认为该任务失败
- 如果Application Master失败了
- Resource Manager接收不到心跳信号时会重启Application Master
- 如果Node Manager失败了
- Resource Manager接收不到心跳信号时会将其移出
- Resource Manager通知Application Master,让Application Master决定任务如何处理
- 如果某个Node Manager失败任务次数过多,Resource Manager调度任务时不再其上面运行任务
- 如果Resource Manager运行失败
- 通过checkpoint机制,定时将其状态保存到磁盘,失败的时候,重新运行
- 通过Zookeeper同步状态和实现透明的HA
Yarn调度器和调度算法
- 集群资源调度器需要解决:
- 多租户(Multi-tenancy):
- 多用户同时提交多种应用程序
- 资源调度器需要解决如何合理分配资源。
- 可扩展性(Scalability):增加集群机器的数量可以提高整体集群性能。
- 多租户(Multi-tenancy):
- Yarn使用队列解决多租户中共享资源的问题

- 支持三种资源调度器
- FIFO
- Capacity Scheduler
- Fair Scheduler
FIFO调度器
- 所有向集群提交的作业使用一个队列
- 根据提交作业的顺序来运行(先来先服务)
- 优点:
- 简单易懂
- 可以按照作业优先级调度
- 缺点:
- 资源利用率不高
- 不允许抢占
Capacity Scheduler资源调度器
- 设计思想:
- 资源按照比例分配给各个队列

- 资源按照比例分配给各个队列
- 特点
- 计算能力保证
- 以队列为单位划分资源,每个队列最低资源保证。
- 灵活性
- 当某个队列空闲时,其资源可以分配给其他的队列使用。
- 支持优先级
- 单个队列内部使用FIFO,支持作业优先级调度
- 多租户
- 综合考虑多种因素防止单个作业、用户或者队列独占资源。
- 每个队列可以配置一定比例的最低资源配置和使用上限。
- 每个队列有严格的访问控制,只能向自己的队列提交任务。
- 基于资源的调度
- 支持内存资源调度和CPU资源的调度。
- 支持抢占(从2.8.0版本开始)
- 计算能力保证
Capacity Scheduler配置

Capacity Scheduler资源分配算法
- 选择队列
• 从根队列开始,使用深度优先算法找出资源占用率最低的叶子队列 - 选择作业
• 默认按照作业优先级和提交时间顺序选择 - 选择Container
• 取该作业中最高优先级的Container,如果优先级相同会选择满足本地性的Container:Node Local >Rack Local > Different Rack

Fair Scheduler资源调度器
- 设计思想
- 资源公平分配
- 具有与Capacity Scheduler相似的特点
- 树状队列
- 每个队列有独立的最小资源保证
- 空闲时可以分配资源给其他队列使用
- 支持内存资源调度和CPU资源调度
- 支持抢占
- 不同点
- 核心调度策略不同
- Capacity Scheduler优先选择资源利用率低的队列
- 公平调度器考虑的是公平,公平体现在作业对资源的缺额
- 单独设置队列间资源分配方式
- FAIR(默认used memory/min share)
- DRF(主资源公平调度)
- 单独设置队列内部资源分配方式
- FAIR DRF FIFO
- 核心调度策略不同
Fair Scheduler - FAIR资源分配算法
- 总体流程与Capacity Scheduler一致
- 1.选择队列
- 2.选择作业
- 3.选择Container
- 选择选择队列和作业使用公平排序算法
- 实际最小份额
minShare = Min(资源需求量,配置minShare) - 是否饥饿
isNeedy = 资源使用量< minShare - 资源分配比
minShareRatio = 资源使用量/Max(minShare, 1) - 资源使用权重比
useToWeightRatio = 资源使用量/权重
权重在配置文件中配置
- 实际最小份额
- 参考 FairShareComparator实现类

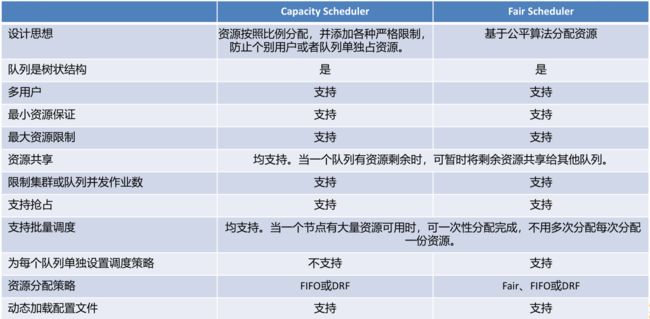
Capacity Scheduler和Fair Scheduler对比
YARN环境搭建
接大数据入门学习笔记(叁)- 布式文件系统HDFS文章里的HDFS搭建
YARN环境搭建
- mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
-
启动YARN相关的进程
sbin/start-yarn.sh -
验证
jps
ResourceManager
NodeManager
或者浏览器:
http://hadoop000:8088

-
停止YARN相关的进程
sbin/stop-yarn.sh
Yarn常用命令介绍
• yarn application
• 列出所有Application
yarn application -list
• 根据Application状态过滤
yarn application -list -appStatus ACCEPTED
• Kill掉Application
yarn application -kill
• yarn logs
• 查询Application日志
yarn logs -applicationId
• 查询Container日志
yarn logs -applicationId \
-containerId \
-nodeAddress
端口是配置文件中yarn.nodemanager.webapp.address参数指定
• yarn applicationattempt
• 列出所有Application尝试的列表
yarn applicationattempt -list
• 打印ApplicationAttemp状态
yarn applicationattempt -status
• yarn container
• 列出所有Container
yarn container -list
• 打印Container状态
yarn container -status
• yarn node
• 列出所有节点
yarn node -list -all
• yarn rmadmin
• 加载队列配置
yarn rmadmin –refreshQueues
• yarn queue
• 打印队列信息
yarn queue -status
• yarn classpath
• 打印Hadoop Jar包路径
提交作业到YARN上执行
提交mr作业到YARN上运行:
下列目录是Hadoop源码中的example
/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
//以这个命令进行提交作业
hadoop jar
待补充。。。
//pi 2 3 为参数 待补充。。。
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3
当我们再次执行该作业时,会报错:
FileAlreadyExistsException:
Output directory hdfs://hadoop001:8020/output/wc already exists
常见基于Yarn的计算框架
MapReduce On Yarn

Spark
- 基于内存的大数据计算引擎
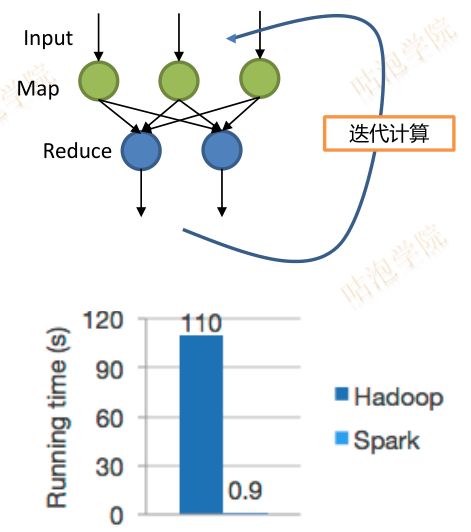
- MapReduce不适合的计算场景:
- 迭代式作业
- 机器学习,图算法需要迭代运行Mapper和Reducer多次
- 交互式作业
- 交互式数据分析,尤其是涉及到机器学习算法
- 流式作业
- 无穷无尽的流式数据,需要不断的对数据进行聚合计算
- 迭代式作业
- Spark提供了一种新的数据抽象RDD弹性分布式数据集,可以将数据存储在内存中,而不是存储到HDFS上,使得快速迭代计算成为可能。


Spark On Yarn
