基于tf-slim框架的DenseNet实现
TF-slim是tensorflow用于定义、训练、评估复杂模型的一个新的轻量级的高级API(tensorflow.contrib.slim)。最近正好研究了一下DenseNet,这里基于tf-slim框架并结合论文实现一个DenseNet网络,并用来进行训练。tf-slim框架代码可见github:https://github.com/tensorflow/models/tree/master/research/slim。
论文中作者对于不同的数据集,其DenseNet网络结构可能有所不同。例如,对于ImageNet以外的数据集,DenseNet包含3个dense blocks,而每一个dense block又有相同数量的网络层。对于ImageNet数据集,作者使用了DenseNet-BC这一结构,它包含了4个dense blocks。初始卷积层深度为2k(k是一个超参数,论文中称之为增长率,表示dense block中每一层的输出通道数),卷积核大小为7x7,步长为2。具体的网络配置见下表,这里以DenseNet-121为示例讲解其实现过程。
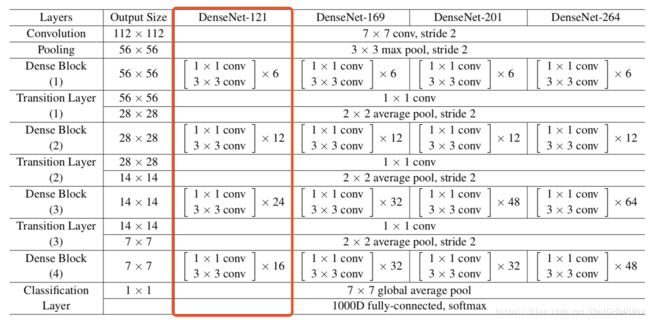
DenseNet-121包含4个dense block,各dense block内部的网络层数依次为6,12,24,16。dense block内部网络层的连接方式为dense connectivity(稠密连接),这也是DenseNet的核心创新点。
def bn_act_conv_drp(current, num_outputs, kernel_size, scope='block'):
"""
Args:
num_outputs: 输出通道数
"""
current = slim.batch_norm(current, scope=scope + '_bn')
current = tf.nn.relu(current)
current = slim.conv2d(current, num_outputs, kernel_size, scope=scope + '_conv')
current = slim.dropout(current, scope=scope + '_dropout')
return current
def block(net, layers, growth, scope='block'):
"""
Args:
layers: dense block包含的网络层数
growth: 增长率
"""
for idx in range(layers):
"""
BN-ReLU-Conv(1x1)-DroupOut-BN-ReLU-Conv(3x3)-DroupOut
"""
bottleneck = bn_act_conv_drp(net, 4 * growth, [1, 1],
scope=scope + '_conv1x1' + str(idx))
tmp = bn_act_conv_drp(bottleneck, growth, [3, 3],
scope=scope + '_conv3x3' + str(idx))
net = tf.concat(axis=3, values=[net, tmp])
return net在dense block之间有一个转换层结构(transition layers),关于transition layers作者是这样描述的。
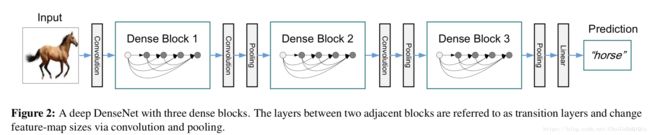

主要是作了卷积和池化操作,改变了feature map的size和深度。
def transition(net, num_outputs, scope='transition'):
net = bn_act_conv_drp(net, num_outputs, [1, 1], scope=scope + '_conv1x1')
net = slim.avg_pool2d(net, [2, 2], stride=2, scope=scope + '_avgpool')
return net ImageNet数据集上,作者使用的k也就是增长率为32,压缩率我这里用的是0.5。
def densenet(images, num_classes=1001, is_training=False,
dropout_keep_prob=0.8,
scope='densenet'):
"""Creates a variant of the densenet model.
images: A batch of `Tensors` of size [batch_size, height, width, channels].
num_classes: the number of classes in the dataset.
is_training: specifies whether or not we're currently training the model.
This variable will determine the behaviour of the dropout layer.
dropout_keep_prob: the percentage of activation values that are retained.
prediction_fn: a function to get predictions out of logits.
scope: Optional variable_scope.
Returns:
logits: the pre-softmax activations, a tensor of size
[batch_size, `num_classes`]
end_points: a dictionary from components of the network to the corresponding
activation.
"""
growth = 32
compression_rate = 0.5
def reduce_dim(input_feature):
return int(int(input_feature.shape[-1]) * compression_rate)
end_points = {}
with tf.variable_scope(scope, 'DenseNet', [images, num_classes]):
with slim.arg_scope(bn_drp_scope(is_training=is_training,
keep_prob=dropout_keep_prob)) as ssc:
net = images
net = slim.conv2d(net, 2*growth, 7, stride=2, scope='conv1')
net = slim.max_pool2d(net, 3, stride=2, padding='SAME', scope='pool1')
net = block(net, 6, growth, scope='block1')
net = transition(net, reduce_dim(net), scope='transition1')
net = slim.avg_pool2d(net, [2, 2], stride=2, scope='avgpool1')
net = block(net, 12, growth, scope='block2')
net = transition(net, reduce_dim(net), scope='transition2')
net = block(net, 24, growth, scope='block3')
net = transition(net, reduce_dim(net), scope='transition3')
net = block(net, 16, growth, scope='block4')
net = slim.batch_norm(net, scope='last_batch_norm_relu')
net = tf.nn.relu(net)
# Global average pooling.
net = tf.reduce_mean(net, [1, 2], name='pool2', keep_dims=True)
biases_initializer = tf.constant_initializer(0.1)
net = slim.conv2d(net, num_classes, [1, 1], biases_initializer=biases_initializer, scope='logits')
logits = tf.squeeze(net, [1, 2], name='SpatialSqueeze')
end_points['Logits'] = logits
end_points['predictions'] = slim.softmax(logits, scope='predictions')
return logits, end_pointsImplementation Details:
Be-fore entering the first dense block, a convolution with 16 (or twice the growth rate for DenseNet-BC) output channels is performed on the input images.
在进入第一个dense block之前,对输入数据做一个输出通道为16(对于DenseNet-BC结构,输出通道数要翻倍,也就是32)的卷积操作。
For convolutional layers with kernel size 3×3, each side of the inputs is zero-padded by one pixel to keep the feature-map size fixed.
对于每个卷积核大小为3x3的卷积层,以0填充的方式在每边增加一个像素,以保持特征图尺寸不变。
We use 1×1convolution followed by 2×2 average pooling as transitionl ayers between two contiguous dense blocks.
相邻两个dense block之间我们使用一个1x1的卷积层再接一个2x2的平均池化层作为转换层。
At the end ofthe last dense block, a global average pooling is performedand then a softmax classifier is attached.
在最后一个dense block之后,使用一个全局平均池化层,紧接着就是softmax分类器。