数据采集引擎Sqoop和Flume
涉及到的知识点:
- Sqoop的安装和配置,及常用命令
- Flume的安装和配置,及使用
Sqoop
数据采集引擎Sqoop的特点:
- 采集的是关系型数据库中的数据(批量)
- 一般用于离线计算
- 基于JDBC
- 用于在Oracle <-> Sqoop <-> HDFS、HBase、Hive间进行数据交换
Sqoop的安装和配置
(1)安装
tar -zxvf sqoop-1.4.5.bin__hadoop-0.23.tar.gz -C ~/training/
(2)配置环境变量
vi ~/.bash_profile
SQOOP_HOME=/root/training/sqoop-1.4.5.bin__hadoop-0.23
export SQOOP_HOMEPATH=$SQOOP_HOME/bin:$PATH
export PATHsource ~/.bash_profile
(3)将Oracle的驱动jar放到sqoop的lib目录(因为我们需要链接到Oracle获取它的模拟数据92万条)。jar包是C:\oracle\product\10.2.0\db_1\jdbc\lib下的ojdbc14.jar,拷贝到/root/training/sqoop-1.4.5.bin__hadoop-0.23/lib下即可
Oracle使用注意点:用户名、表名、列名必须大写
Sqoop的使用
Sqoop的可用命令如下:
| 命令 | 说明 |
|---|---|
| codegen | 根据数据块中的表结构生成对应的JavaBean |
| create-hive-table | 根据Oracle的表结构创建Hive的表结构 |
| eval | 在Sqoop中执行SQL |
| export | 从HDFS中导数据到关系数据库中 |
| help | 帮助信息 |
| import | 将数据库表的数据导入到HDFS中,本质就是MapReduce程序 |
| import-all-tables | 导入某个用户下所有的表 —-> 默认导入到: /user/root |
| job | 用来生成一个sqoop的任务,生成后,该任务并不执行,除非使用命令执行该任务。 |
| list-databases | (1)针对Oracle:当前数据库中所有的用户名(2)针对MySQL: 所有的数据库的名字 |
| list-tables | 打印出关系数据库某一数据库的所有表名 |
| merge | 将HDFS中不同目录下面的数据合在一起,并存放在指定的目录中 |
| metastore | 记录sqoop job的元数据信息 |
| version | 显示sqoop版本信息 |
下面我们对于常见命令进行列举:
(1)codegen
根据Oracle数据库中的EMP员工表生成bean类。
sqoop codegen –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SCOTT -password tiger –table EMP –outdir /root/sqoop
生成之后,我们通过cat命令查看一下EMP.java(太长了,只截了一部分):
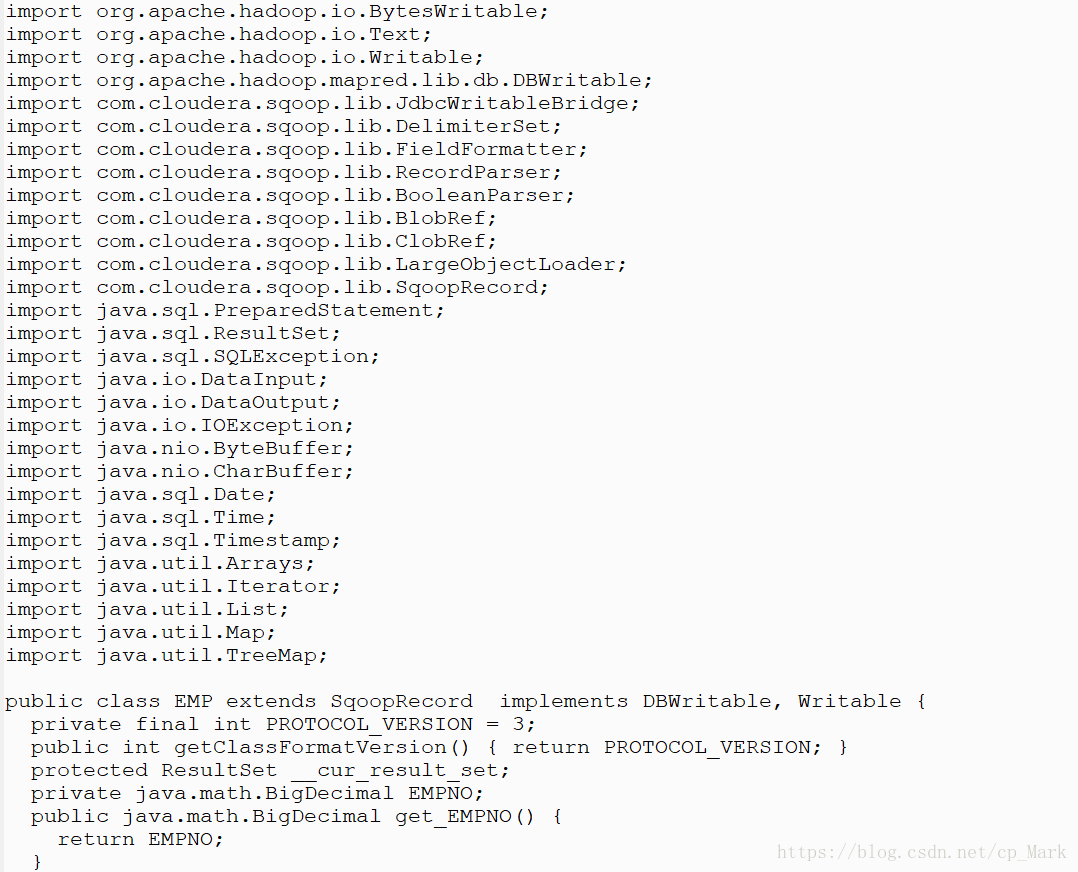
(2)create-hive-table
根据Oracle数据库中的EMP员工表生成Hive表。
sqoop create-hive-table –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SCOTT -password tiger –table EMP –hive-table emphive
结果如下:

(3)eval
查询EMP表中部门号=10的数据。
sqoop eval –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SCOTT –password tiger –query ‘select * from emp where deptno=10’
结果如下:

(4)import
- 导入EMP表 员工表
sqoop import –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SCOTT –password tiger –table EMP –target-dir /sqoop/import/emp1
结果如下:

- 导入EMP表,指定导入列
sqoop import –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SCOTT –password tiger –table EMP –columns ENAME,SAL –target-dir /sqoop/import/emp2
结果如下:
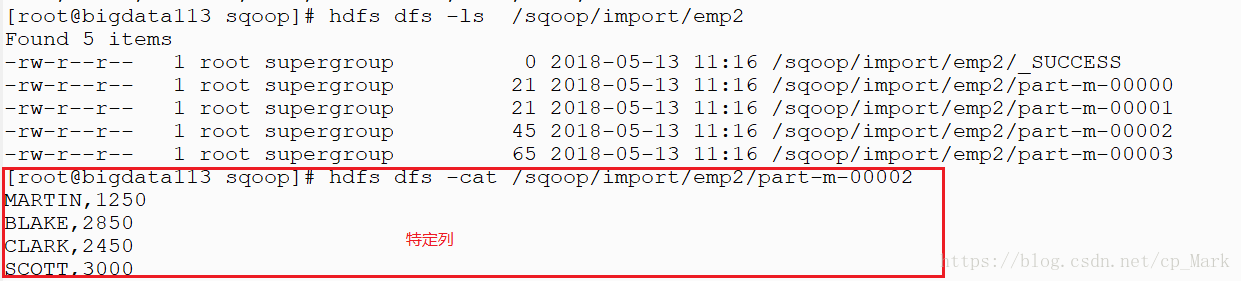
* 导入订单表:sh用户 sales表(订单表:92万)
sqoop import –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SH –password sh –table SALES –target-dir /sqoop/import/sales
此时报错:
![]()
因为SALES没有主键,所以导入失败,可以这么做:
sqoop import –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SH –password sh –table SALES –target-dir /sqoop/import/sales -m 1
九十几万条太多就不截图了。
(5)import-all-tables
导入SCOTT用户下的所有表(默认导入到: /user/root)。
sqoop import-all-tables –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SCOTT –password tiger
结果如下:

(6)list-databases
列出当前数据库下的所有用户名(因为我们是Oracle数据库)。
sqoop list-databases –connect jdbc:oracle:thin:@192.168.171.137:1521/orcl –username SYSTEM –password password
结果如下:

Flume
数据采集引擎Flume的特点:
- 实时采集日志
- 一般用于实时计算
Flume的体系结构图:

在上图中,Flume涉及的各种组件都有多种,我们通过官网去查看一下:
官网地址:http://flume.apache.org/FlumeUserGuide.html
可选Sources组件,如果都不满足,可以自定义:

可选channel组件:

可选sinks组件:
可选的组件其实不止这些,但是这些是目前我们需要的,它们组成一个agent。
Flume的安装和配置
安装命令:
tar -zxvf apache-flume-1.7.0-bin.tar.gz -C ~/training/
配置agent:
#bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
#定义agent名, source、channel、sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1
#具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /root/training/logs
#具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100
#定义拦截器,为消息添加时间戳
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#具体定义sink
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://192.168.171.113:9000/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events-
a4.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a4.sinks.k1.hdfs.rollInterval = 60
#组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1配置完成之后,启动flume:
bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
可以发现其实就是启动上面配置的a4,我们现在通过webconsole去查看一下目录:
HDFS:http://192.168.171.113:50070
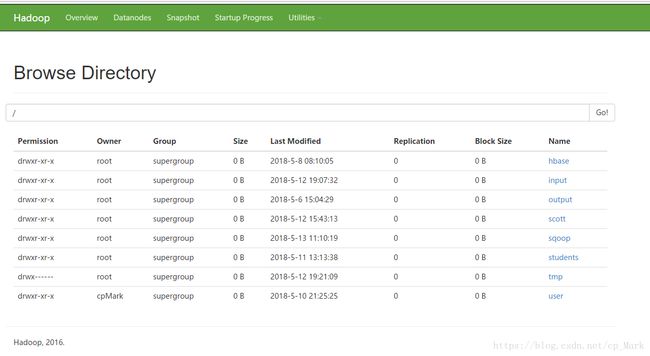
发现并没有我们配置的flume目录。现在我们将Hadoop下的logs目录下的日志复制到/root/training/logs中(上面配置的监听目录),再看下结果:
cp *.log ~/training/logs/
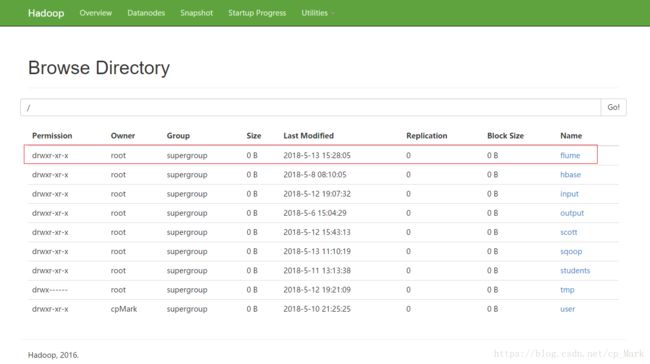
点击进去查看:

发现是一个临时文件,为什么是临时文件,什么时候会变成持久化文件呢?其实这是我们在配置a4时配置的:

从上面就可以看出,要么文件达到128M,要么过60s即可,现在再去看下:
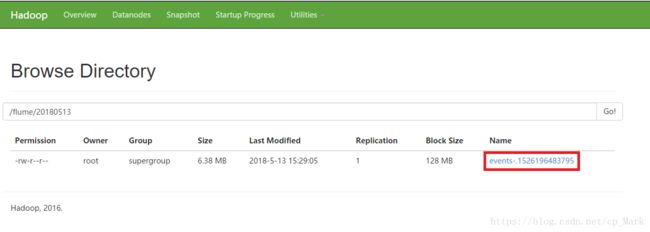
发现确实已经不再是临时文件。到这里Flume的使用就已经完成了,有需要可以去深入研究一下。