从Hinton开山之作开始,谈知识蒸馏的最新进展

作者 | 孟让
转载自知乎
导读:知识蒸馏是一种模型压缩常见方法,模型压缩指的是在teacher-student框架中,将复杂、学习能力强的网络学到的特征表示“知识”蒸馏出来,传递给参数量小、学习能力弱的网络。本文对17、18年知识蒸馏的最新进展进行简评,作者把内容分成2到3部分,以下是第一部分。
蒸馏可以提供student在one-shot label上学不到的soft label信息,这些里面包含了类别间信息,以及student小网络学不到而teacher网络可以学到的特征表示‘知识’,所以一般可以提高student网络的精度。
开山之作:Hinton发表在NIPS2014文章:[1503.02531] Distilling the Knowledge in a Neural Network(https://arxiv.org/abs/1503.02531)
一. Attention Transfer

Attention Transfer , 传递teacher网络的attention信息给student网络。首先,CNN的attention一般分为两种,spatial-attention,channel-attention。本文利用的是spatial-attention.所谓spatial-attention即一种热力图,用来解码出输入图像空间区域对输出贡献大小。文章提出了两种可利用的spatial-attention,基于响应图的和基于梯度图的。

Activation-based
基于响应图(特征图),取出CNN某层输出特征图张量A,尺寸:(C, H, W).定义一个映射F:

将3D张量flat成2D.这个映射的形式有三种供选择:

1. 特征图张量各通道绝对值相加:
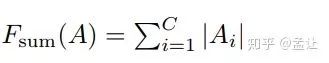
2. 特征图张量各通道绝对值p次幂相加:

3. 取特征图张量各通道绝对值p次幂最大值:

对以上这些映射对应的特征图统计量可视化,可以发现,attention map不仅与输入图像中预测物体有low-level上的关联,而且与预测准确度也有关系。不同映射可视化效果也有所差异。


attention transfer的目的是将teacher网络某层的这种spatial attention map传递给student网络,让student网络相应层的spatial attention map可以模仿teacher,从而达到知识蒸馏目的。teacher-student框架设计如下:

AT loss是teacher和student对应的attention map取L2 LOSS.文章也指出,p次幂取2为佳,所得attention map也要先归一化。总loss:
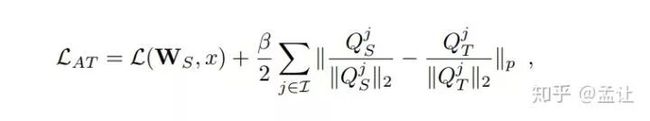
Gradient-based

求出loss对输入x的梯度,如果输入某像素出梯度很大,表明损失函数对该点敏感度高,Paying more attention。teacher-student loss 写成;
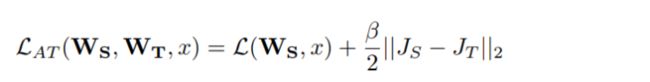
反传过程:
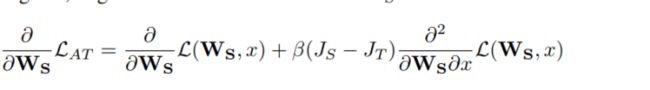
训练过程:先计算teacher,student梯度attention map和两者MSE,以及student的前传loss,然后再反向传播。文章还提出了一种加强flip不变性的方法,即对一个输入图片,求出损失对其梯度的attention map之后(即flip图片所得梯度attention map),优化两者MSE,减少损失:
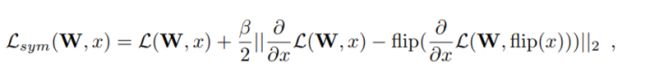
二. FSP matrix

和之前知识蒸馏的文章不同之处在于之前文章往往是把teacher的某层的输出作为student的mimic目标,这篇文章将teacger网络层与层之间的关系作为student网络mimic的目标。这篇文章介绍的这种知识蒸馏的方法类似风格迁移的gram矩阵。
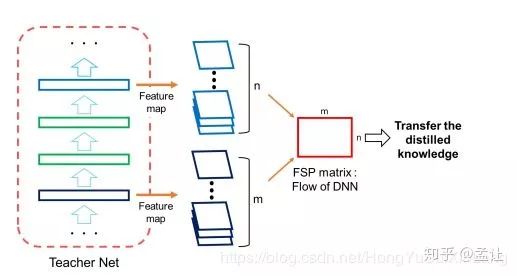
文章提出的描述层与层之间关系的方法FSP matrix,是某层特征图与另外一层特征图之间的偏心协方差矩阵(即没有减去均值的协方差矩阵)。如F1层特征图配置(H,W,M)M为通道数。F2层特征图配置(H,W,N)。得到一个M * N的矩阵G。G(i,j)为F1第i通道与F2第j通道的elemet-wise乘积之和:
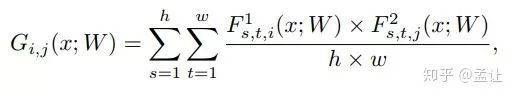
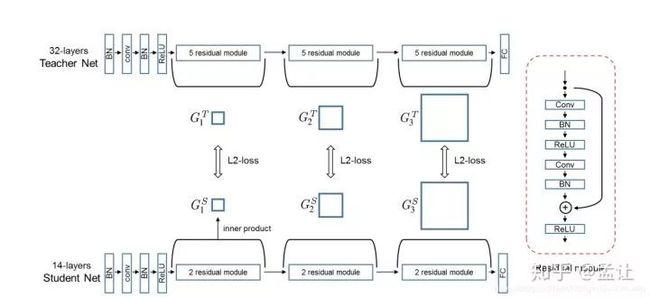
文章中FSP矩阵的损失函数是L2loss,把网络层数分成n个block,每个block计算一个FSP,要求teacher与student的对应FSP具有相同spatial size.teacher-student结构如图:
损失函数如下:

我的对文章的感想是,文章有意思的地方在于“授之以鱼不如授之以渔”。韩国人写的文章,多少有些东方师道哲学影响。
三. DarkRank: Accelerating Deep Metric Learning via Cross Sample Similarities

这篇文章提出了一种适合度量学习(如检索,Re-id,人脸识别,图像聚类)的知识蒸馏方法。所传递的知识就是度量学习所度量的样本间相似度,用learn to rank来传递知识。所以先说一些Related works。
Learn To Rank
L2R,有监督排序算法,广泛应用于文本信息检索领域。给定一个query,学习一个模型对一组样本根据相似度排序。常用的排序学习分为三种类型:PointWise,PairWise和ListWise。PointWise将L2R看作一种回归问题,对每个样本打分,优化(如L2 loss)各样本分数与query之间的相似度。PairWise将L2R转化为二分类问题,针对一对样本,如果这对样本与query中排序一致则模型输出1,否则输出0。ListWise直接优化整组样本,可以看作对所有候选排序的分类。如 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-2007-40.pdf
(PDF) Listwise approach to learning to rank - Theory and algorithm(https://www.researchgate.net/publication/221345286_Listwise_approach_to_learning_to_rank_-_Theory_and_algorithm)
本文就是基于listwise的方法。该方法根据candidates(排列候选项)与query之间相似度对每个candidate打分,并计算概率。
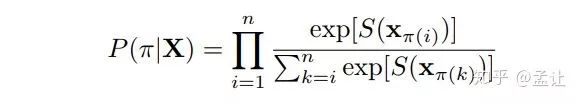
其中π为一组样本索引的排序。xi为一个样本。S(x) 是模型对样本的打分。然后是熟悉的交叉熵:

也可以使用最大似然函数(MLE)
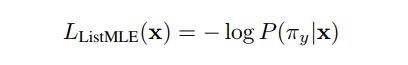
方法
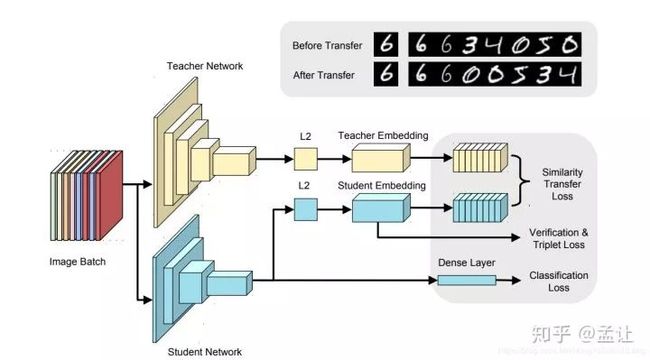
以上是teacher-student框架。文章的实现teacher为Incepton-BN,student为NIN-BN。使用Imagenet的FC层之前的pretrain model,所得特征图经过GAP(全局平均池化),后接FC层,这里加入large margin softmax loss,之后L2归一化,所得特征向量称为嵌入特征,输入到排序学习模块,然后将teacher样本间相似度知识传递给student。
以上过程:
Pretrain-->GAP-->FC-->Large Margin Softmax Loss-->L2-->Verification Loss & Triplet Loss-->Score-->Cross Sample Similarities Transfer
其中,large margin softmax loss为了是类间距离增大而类内距离减小,度量学习,使得度量空间更好。直接施加在FC层的特征输出。所得特征向量经过L2归一化处理之后,加入verification loss & triplet loss,同样是度量学习目的,获得更好的嵌入特征,从而得到更好的cross sample similarities知识。
Score是一个欧式距离。取batch中一个样本q作为query,其他样本作为candidates,使用欧氏距离作为样本相似度评分函数(文章实验表明α=3,β=3效果最佳):

cross sample similarities transfer:文章在ListNet,ListMLE启发下,提出soft/hard两种传递损失函数:

其中P()按照Learn to Rank中介绍的相关方法计算。这个soft transfer是一个KL散度。
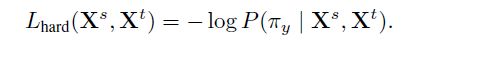
hard transfer是MLE.对比两种transfer发现soft是要考虑所有排序,而hard只需要考虑gt一种,计算效率高,效果也不差,所以使用hard transfer。当然,最直接的cross sample similiritiestransfer方法是把score直接取L2 loss。后文也做了对照。
文章在Re-id上做了KD,direct similarities transfer,Hard/soft transfer的对比实验。
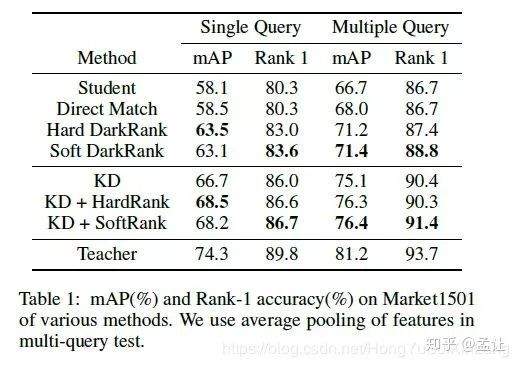
对照发现,仅仅用soft transfer cross sample similarities 知识效果并没有超过KD(T=4),但是结合KD之后提高了精度,说明这种方法传递了KD不包含的知识--cross sample similarities,一种排序,并不包含每个特征量级的大小,而且不要求传递双方特征维度一致。
原文链接:https://zhuanlan.zhihu.com/p/51563760
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
“只讲技术,拒绝空谈!”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。目前,大会早鸟票抢购中~扫码购票,领先一步!

推荐阅读
博士毕业最高201万!华为顶级薪酬招“天才少年”
单v100 GPU,4小时搜索到一个鲁棒的网络结构
别再说学不会:超棒的Numpy可视化学习教程来了!
再不要这样起变量名了!
17 岁成为 iOS 越狱之父,25 岁造出无人车,黑客传奇!
刚刚!为吊打谷歌,微软砸10亿美元布局AI,网友炸了!发帖上热门……
华为,百度豪投,这类程序员要再次上榜了!
百度入局, 一文读懂年交易过4亿「超级链」究竟是什么?
云计算将会让数据中心消失?