SLAM的前世今生
SLAM的前世
我之前从本科到研究生,一直在导航与定位领域学习,一开始偏重于高精度的惯性导航、卫星导航、星光制导及其组合导航。出于对实现无源导航的执念,我慢慢开始研究视觉导航中的SLAM方向,并与传统的惯性器件做组合,实现独立设备的自主导航定位。
定位、定向、测速、授时是人们惆怅千年都未能完全解决的问题,最早的时候,古人只能靠夜观天象和司南来做简单的定向。直至元代,出于对定位的需求,才华横溢的中国人发明了令人叹为观止的牵星术,用牵星板测量星星实现纬度估计。
1964年美国投入使用GPS,突然就打破了大家的游戏规则。军用的P码可以达到1-2米级精度,开放给大众使用的CA码也能够实现5-10米级的精度。
后来大家一方面为了突破P码封锁,另一方面为了追求更高的定位定姿精度,想出了很多十分具有创意的想法来挺升GPS的精度。利用RTK的实时相位差分技术,甚至能实现厘米的定位精度,基本上解决了室外的定位和定姿问题。
但是室内这个问题就难办多了,为了实现室内的定位定姿,一大批技术不断涌现,其中,SLAM技术逐渐脱颖而出。SLAM是一个十分交叉学科的领域,我先从它的传感器讲起。
▌离不开这两类传感器
目前用在SLAM上的Sensor主要分两大类,激光雷达和摄像头。(待会儿发的部分素材摘自官网、论文、专利,侵删)。

这里面列举了一些常见的雷达和各种深度摄像头。激光雷达有单线多线之分,角分辨率及精度也各有千秋。SICK、velodyne、Hokuyo以及国内的北醒光学、Slamtech是比较有名的激光雷达厂商。他们可以作为SLAM的一种输入形式。
这个小视频里展示的就是一种简单的2D SLAM。
这个小视频是宾大的教授kumar做的特别有名的一个demo,是在无人机上利用二维激光雷达做的SLAM。
而VSLAM则主要用摄像头来实现,摄像头品种繁多,主要分为单目、双目、单目结构光、双目结构光、ToF几大类。他们的核心都是获取RGB和depth map(深度信息)。简单的单目和双目(Zed、leapmotion)我这里不多做解释,我主要解释一下结构光和ToF。
▌最近流行的结构光和TOF
结构光原理的深度摄像机通常具有激光投射器、光学衍射元件(DOE)、红外摄像头三大核心器件。

这个图(下图)摘自primesense的专利。

可以看到primesense的doe是由两部分组成的,一个是扩散片,一个是衍射片。先通过扩散成一个区域的随机散斑,然后复制成九份,投射到了被摄物体上。根据红外摄像头捕捉到的红外散斑,PS1080这个芯片就可以快速解算出各个点的深度信息。
这儿还有两款结构光原理的摄像头。


第一页它是由两幅十分规律的散斑组成,最后同时被红外相机获得,精度相对较高。但据说DOE成本也比较高。
还有一种比较独特的方案(最后一幅图),它采用mems微镜的方式,类似DLP投影仪,将激光器进行调频,通过微镜反射出去,并快速改变微镜姿态,进行行列扫描,实现结构光的投射。(产自ST,ST经常做出一些比较炫的黑科技)。
ToF(time of flight)也是一种很有前景的深度获取方法。
传感器发出经调制的近红外光,遇物体后反射,传感器通过计算光线发射和反射时间差或相位差,来换算被拍摄景物的距离,以产生深度信息。类似于雷达,或者想象一下蝙蝠,softkinetic的DS325采用的就是ToF方案(TI设计的),但是它的接收器微观结构比较特殊,有2个或者更多快门,测ps级别的时间差,但它的单位像素尺寸通常在100um的尺寸,所以目前分辨率不高。以后也会有不错的前景,但我觉得并不是颠覆性的。
好,那在有了深度图之后呢,SLAM算法就开始工作了,由于Sensor和需求的不同,SLAM的呈现形式略有差异。大致可以分为激光SLAM(也分2D和3D)和视觉SLAM(也分Sparse、semiDense、Dense)两类,但其主要思路大同小异。

这个是Sparse(稀疏)的
这个偏Dense(密集)的
▌SLAM算法实现的4要素
SLAM算法在实现的时候主要要考虑以下4个方面吧:
1. 地图表示问题,比如dense和sparse都是它的不同表达方式,这个需要根据实际场景需求去抉择
2. 信息感知问题,需要考虑如何全面的感知这个环境,RGBD摄像头FOV通常比较小,但激光雷达比较大
3. 数据关联问题,不同的sensor的数据类型、时间戳、坐标系表达方式各有不同,需要统一处理
4. 定位与构图问题,就是指怎么实现位姿估计和建模,这里面涉及到很多数学问题,物理模型建立,状态估计和优化
其他的还有回环检测问题,探索问题(exploration),以及绑架问题(kidnapping)。
这个是一个比较有名的SLAM算法,这个回环检测就很漂亮。但这个调用了cuda,gpu对运算能力要求挺高,效果看起来比较炫。
▌以VSLAM举个栗子

我大概讲一种比较流行的VSLAM方法框架。
整个SLAM大概可以分为前端和后端,前端相当于VO(视觉里程计),研究帧与帧之间变换关系。首先提取每帧图像特征点,利用相邻帧图像,进行特征点匹配,然后利用RANSAC去除大噪声,然后进行匹配,得到一个pose信息(位置和姿态),同时可以利用IMU(Inertial measurement unit惯性测量单元)提供的姿态信息进行滤波融合
后端则主要是对前端出结果进行优化,利用滤波理论(EKF、UKF、PF)、或者优化理论TORO、G2O进行树或者图的优化。最终得到最优的位姿估计。
后端这边难点比较多,涉及到的数学知识也比较多,总的来说大家已经慢慢抛弃传统的滤波理论走向图优化去了。
因为基于滤波的理论,滤波器稳度增长太快,这对于需要频繁求逆的EKF(扩展卡尔曼滤波器),PF压力很大。而基于图的SLAM,通常以keyframe(关键帧)为基础,建立多个节点和节点之间的相对变换关系,比如仿射变换矩阵,并不断地进行关键节点的维护,保证图的容量,在保证精度的同时,降低了计算量。
列举几个目前比较有名的SLAM算法:PTAM,MonoSLAM, ORB-SLAM,RGBD-SLAM,RTAB-SLAM,LSD-SLAM。
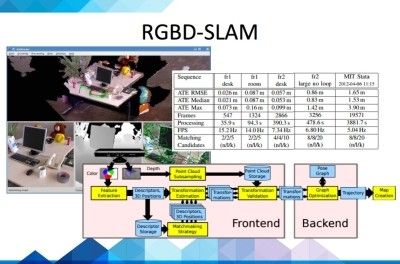


所以大家如果想学习SLAM的话,各个高校提高的素材是很多的,比如宾大、MIT、ETH、香港科技大学、帝国理工等等都有比较好的代表作品,还有一个比较有前景的就是三维的机器视觉,普林斯顿大学的肖剑雄教授结合SLAM和Deep Learning做一些三维物体的分类和识别, 实现一个对场景深度理解的机器人感知引擎。

http://robots.princeton.edu/talks/2016_MIT/RobotPerception.pdf 这是他们的展示。
总的来说,SLAM技术从最早的军事用途(核潜艇海底定位就有了SLAM的雏形)到今天,已经逐步走入人们的视野,扫地机器人的盛行更是让它名声大噪。同时基于三维视觉的VSLAM越来越显主流。在地面/空中机器人、VR/AR/MR、汽车/AGV自动驾驶等领域,都会得到深入的发展,同时也会出现越来越多的细分市场等待挖掘。

这个是occipital团队出的一个产品,是个很有意思的应用,国内卖4000+,大概一个月1000出货量吧(虽然不是很多,但是效果不错,pad可玩)虚拟家居、无人飞行/驾驶、虚拟试衣、3D打印、刑侦现场记录、沉浸式游戏、增强现实、商场推送、设计辅助、地震救援、工业流水线、GIS采集等等,都等待着VSLAM技术一展宏图
▌SLAM的今生——还存在着问题
多传感器融合、优化数据关联与回环检测、与前端异构处理器集成、提升鲁棒性和重定位精度都是SLAM技术接下来的发展方向,但这些都会随着消费刺激和产业链的发展逐步解决。就像手机中的陀螺仪一样,在不久的将来,也会飞入寻常百姓家,改变人类的生活。
不过说实话,SLAM在全面进入消费级市场的过程中,也面对着一些阻力和难题。比如Sensor精度不高、计算量大、Sensor应用场景不具有普适性等等问题。
多传感器融合、优化数据关联与回环检测、与前端异构处理器集成、提升鲁棒性和重定位精度都是SLAM技术接下来的发展方向,但这些都会随着消费刺激和产业链的发展逐步解决。就像手机中的陀螺仪一样,在不久的将来,也会飞入寻常百姓家,改变人类的生活。
(激光雷达和摄像头两种 SLAM 方式各有什么优缺点呢,有没有一种综合的方式互补各自的缺点的呢?)
激光雷达优点是可视范围广,但是缺点性价比低,低成本的雷达角分辨率不够高,影响到建模精度。vSLAM的话缺点就是FOV通常不大,50-60degree,这样高速旋转时就容易丢,解决方案有的,我们公司就在做vSLAM跟雷达还有IMU的组合。
(请问目前基于视觉的SLAM的计算量有多大?嵌入式系统上如果要做到实时30fps,是不是只有Nvidia的芯片(支持cuda)才可以?)
第一个问题,虽然基于视觉的SLAM计算量相对较大,但在嵌入式系统上是可以跑起来的,Sparse的SLAM可以达到30-50hz(也不需要GPU和Cuda),如果dense的话就比较消耗资源,根据点云还有三角化密度可调,10-20hz也是没有问题。
并不一定要用cuda,一些用到cuda和GPU的算法主要是用来加速SIFT、ICP,以及后期三角化和mesh的过程,即使不用cuda可以采用其他的特征点提取和匹配策略也是可以的。
▌最后一个问题
(今年8月,雷锋网将在深圳举办“全球人工智能与机器人创新大会”(简称:GAIR)。想了解下,您对机器人的未来趋势怎么看?)
这个问题就比较大了。
机器人产业是个很大的Ecosystem,短时间来讲,可能产业链不够完整,消费级市场缺乏爆点爆款。虽然大家都在谈论做机器人,但是好多公司并没有解决用户痛点,也没有为机器人产业链创造什么价值。
但是大家可以看到, 大批缺乏特色和积淀的机器人公司正在被淘汰,行业格局越来越清晰,分工逐渐完善,一大批细分市场成长起来。
从机器人的感知部分来说,传感器性能提升、前端处理(目前的sensor前端处理做的太少,给主CPU造成了很大的负担)、多传感器融合是一个很大的增长点。
现在人工智能也开始扬头,深度学习、神经网络专用的分布式异构处理器及其协处理器成为紧急需求,我个人很希望国内有公司能把这块做好。
也有好多创业公司做底层工艺比如高推重比电机、高能量密度电池、复合材料,他们和机器人产业的对接,也会加速机器人行业的发展。整个机器人生态架构会越来越清晰,从硬件层到算法层到功能层到SDK 再到应用层,每一个细分领域都有公司切入,随着这些产业节点的完善,能看到机器人行业的前景还是很棒的,相信不久之后就会迎来堪比互联网的指数式增长!
转自:http://www.leiphone.com/news/201605/5etiwlnkWnx7x0zb.html
很好的一篇文章 分享一下转自:https://blog.csdn.net/jaccen2012/article/details/55505646