ResNet网络解析和代码实现
ResNet网络解析和代码实现
ResNet(Residual Neural Network)在2015年由Kaiming He等人提出的,通过特殊的网络结构设计,训练出了152层的深度神经网络,并在ImageNet比赛classification任务上获得了冠军(top-5错误率 3.57%)。ResNet的提出打破了深度网络无法训练的难题,不仅模型的准确率得到提高,而且参数量也比VGG少,之后也有很多网络的设计都借鉴了ResNet的思想,如Google InceptionV4,DenseNet等,使网络性能得到进一步的提升。
1.背景与灵感
1)通常认为神经网络的深度对网络的性能影响很大,越深的网络往往能得到更好的性能,但随着网络的加深,由于存在信息损失严重和梯度消失等问题,训练难度也加大。
2)在不断加深网络的深度时,会出现Degradation的问题,即准确率会先上升,然后逐渐饱和,继续加深可能会导致准确率下降。这不是过拟合的问题,因为模型在训练集和测试集上的误差都会加大(通常产生过拟合是因为网络过分学习了训练集的特征而降低了其泛化能力,造成训练集的准确率很高,而测试集的准确率很低)。
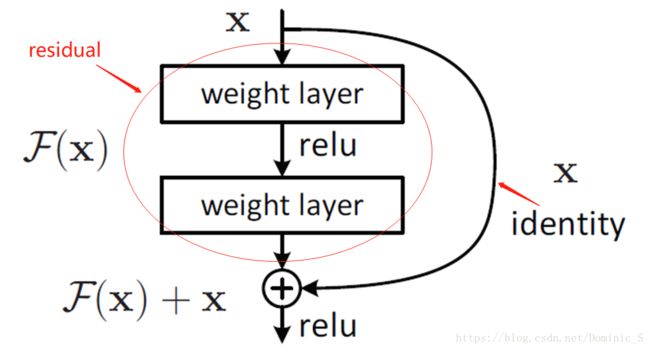
ResNet提出的残差模块能解决以上的问题。既然网络加深到一定程度会造成饱和和准确率下降,那在特征传递的过程中,就让后续网络层的传递媒介影响降低,使用全等映射,将输入直接传递给输出,这样至少能保证网络性能不下降。
如上图所示,ResNet的残差学习模块在对特征进行传递的时候,提供了两条道路,一条是经过residual映射,得到F(x),另一条路则是直接传递x本身,合并之后再进行激活,传递到下一个模块。当网络已经达到最优,网络的后续训练将会限制residual映射部分,当residual被限制为0时,就只剩下全等映射的x,网络也就不会因为深度的加深造成准确率下降了。
假设期望的输出是H(x),则训练时F(x)=H(x)-x,其中x是有全等映射的支路传递过去的,而F(x)是有residual映射传递的,网络的训练将对F(x)部分的权重进行优化更新,学习的目标不再是完整的输出H(x),而是输出与输入的差别H(x)-x,F(x)即是所谓的残差。
由于ResNet使用了分支的方法,其中一条支路将上一层的输入直接传递到下一层,使得的信息得到了更多的保留,减轻了深层网络信息丢失和损耗的问题,这种结构成为shortcut或skip connections。
2.网络结构

在ILSVRC 2015比赛获胜的解决方案是深度为152层的方案,但另外两个方案50-layer和101-layer更经常被引用和借鉴。
网络由三大块组成。首先通过一个普通的卷积层[7x7x64],stride=2,对输入图片进行特征提取,并将尺寸缩小为原来的1/2,然后接上[3x3]的最大池化,stride=2,进一步缩小feature map的尺寸,然后就送入各个残差模块。论文中以类似于conv2_x的方式对网络进行命名(上表中的layer name),同一个Block中,如conv2_x中有多个残差模块连接。最后,网络使用全局池化进行规整,再使用softmax进行分类(ImageNet比赛分类任务有1000个分类)。
网络层数计算
以比赛获胜的152-layer方案为例,每个Block中残差模块的数量分别是3、8、36、3,而每个残差模块中都包含了3层卷积,故残差模块的总层数为(3+8+36+3)*3=150,再加上第一层的卷积和最后一层的分类,总共是152层,其他几个网络方案的计算类似(激活和池化不计算在内)。
3.残差模块
1)残差模块结构
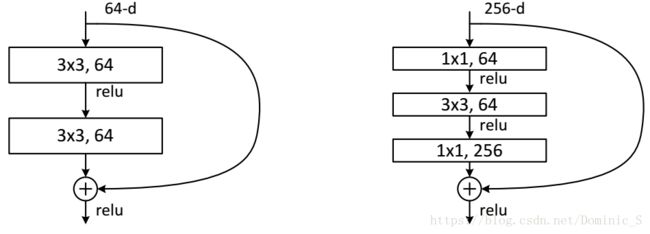
论文中提出两种残差模块,其中左边的模块使用两个[3x3]的卷积核,右边的结构先用[1x1]卷积操作将通道数降维成64,在[3x3]卷积操作后再用[1x1]卷积将通道数升到256,经历了先降维再升维,这种结构称为bottleneck design,带来的好处是可以降低参数的数量。和Inception V3类似,ResNet在深度加深的同时不断使用步长为2的层来缩减feature map的空间尺寸,同时增加输出的通道数,最后达到2048。
2)尺寸匹配
上图的残差模块的输出中,y=F(X)+x,即经过residual映射的feature map和原输入的feature map x相加,运算可以执行的条件是这两部分的空间尺寸和channel数相同(这点与Inception网络不同,Inception在进行分支合并时是采用通道拼接的方式(tf.concat),只要保证空间尺寸相同即可)。
通道数不同: 如果两部分的通道数不同,则需要通过卷积操作调整x的channel数进行匹配,即y=F(X)+Wx,其中W为卷积操作。
空间尺寸不同: 若空间尺寸不同(因为残差模块中[3x3]的卷积层stride可能是2,即经过该residual变换后空间尺寸减小为原来的1/2),则需要对输入的x使用降采样(subsample),stride根据实际情况设置。
4.代码实现
1)bottleneck——残差模块
参数列表:
inputs 输入,depth 输出通道数,depth_bottleneck 残差的第1、2层输出通道数,stride 步长
def bottleneck(inputs, depth, depth_bottleneck, stride, outputs_collections = None, scope = None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank = 4)
preact = slim.batch_norm(inputs, activation_fn = tf.nn.relu, scope = 'preact')
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride = stride, normalizer_fn = None, activation_fn = None, scope = 'shortcut')
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride = 1, scope = 'conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride, scope = 'conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride = 1, normalizer_fn = None, activation_fn = None, scope = 'conv3')
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections, sc.name, output)
- 使用 slim.utils.last_dimension获取输入的最后一个维度,即输入通道数
- 对输入进行归一化(Batch Normalization),使用ReLU函数预激活
- 判断输入和输出的尺寸是否一致,若不一致就根据通道数不一致还是空间尺寸不一致两种情况,分别对输入的x相对应的处理,处理原理请见上述尺寸匹配介绍
- 定义residual,即残差,共有3层,分别是[1x1]卷积(stride=1),[3x3]卷积(stride可设置)和最后的[1x1]卷积(stride=1),其中前两个卷积的输出通道数都是depth_bottleneck,最后1个卷积输出通道数为depth,最终得到residual
- 最后将shortcut(输入x)和residual(F(x))相加,得到output(输出H(x)),使用slim.utils.collect_named_outputs将结果添加进collection并返回output作为函数结果。
2)ResNet 152-layer网络
def resnet_v2_152(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_152'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
对照上面的网络结构表格中152-layer可以看到,网络中有四个Block,对应代码中四个Block,其中每个Block中包含数量不等的残差模块。其中参数列表中(256, 64, 1)的结构对应的是一个三元的tuple,分别代表(depth, depth_bottleneck, stride)
3)主函数
def resnet_v2(inputs, blocks, num_classes = None, global_pool = True, include_root_block = True, reuse = None, scope = None):
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse = reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, bottleneck, stack_blocks_dense], outputs_collections = end_points_collection):
net = inputs
if include_root_block:
with slim.arg_scope([slim.conv2d], activation_fn = None, normalizer_fn = None):
net = conv2d_same(net, 64, 7, stride = 2, scope = 'conv1')
net = slim.max_pool2d(net, [3, 3], stride = 2, scope = 'pool1')
net = stack_blocks_dense(net, blocks)
net = slim.batch_norm(net, activation_fn = tf.nn.relu, scope = 'postnorm')
if global_pool:
net = tf.reduce_mean(net, [1, 2], name = 'pool5', keep_dims = True)
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn = None, normalizer_fn = None, scope = 'logits')
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope = 'predictions')
return net, end_points
- 对原始输入图片进行卷积和池化操作,将图片缩小为原来的1/4,然后送入残差模块
- 使用stack_blocks_dense函数进行整个网络的残差模块封装和生成(该函数是自定义的一个函数)
- 使用reduce_mean进行全局平均池化,效率比直接用avg_pool高
- 最后根据是否有分类数添加卷积、激活和分类器
以上只是简单对网络中核心的代码进行分析,ResNet_V2完整代码实现请参照这里(slim框架)
5.网络配置对比
以下是对VGG-19、直连的34层网络、ResNet的34层网络的结构对比图,其中图中将ResNet的残差结构全部展开。可以更直观的发现,和普通的直连卷积网络对比,ResNet有很多支路(跳阶结构),即下一层的输入可能来自于上一层的原始feature map+经过residual变化的feature map,这种结构保留了更多向前传递的信息。

参考文献
《Deep Residual Learning for Image Recognition》
《Tensorflow实战》