【论文阅读笔记】Finding Tiny Faces in the Wild with Generative Adversarial Network
论文链接:http://openaccess.thecvf.com/content_cvpr_2018/CameraReady/0565.pdf
引用:
@InProceedings{Bai_2018_CVPR, author = {Bai, Yancheng and Zhang, Yongqiang and Ding, Mingli and Ghanem, Bernard}, title = {Finding Tiny Faces in the Wild With Generative Adversarial Network}, booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2018} }
原文阅读
摘要
人脸检测的挑战:无约束条件下的小脸检测
原因分析:细节信息缺失、模糊
解决问题的方向:GAN生成清晰高分辨率的人脸
现有方法:SR-GAN/cycle-GAN串行实现超分辨率、细化
本文改进:(1) 联合实现超分辨率、细化;(2)引入新的损失函数,恢复细节+同时分辨真假脸和是非脸
数据集:WIDER FACE
简介
研究趋势:约束场景下取得了很大的进步,但是无约束场景下存在很多挑战
原因:尺度、清晰度、角度、表情、光照等都存在显著变化
参考综述文章:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.702.833&rep=rep1&type=pdf
主要挑战:(1) 大量细节信息缺失,使得较难分辨人脸和相似背景(部分脸、手);(2) 传统CNN网络下采样导致大部分空间信息丢失,使得像素点太少无法表示小脸
解决方法:(1) 双线性插值上采样,a. 计算成本增加,推断时间增加,b. 较小的方法系数,如2X,也会造成失真;(2)中间卷积特征图,a. 权衡性能和效率,b. 浅层但细粒度中间层区分度不够,增加假阳性结果。上述方法都没有考虑模糊和光照影响
本文方法和贡献:基于GAN的端到端的卷积神经网络。(1) 两个子网络:生成网络、判别网络;(2) 生成网络是两个子网络的连接(SRN+RN),SRN用于小脸图像的上采样,在较大的放大系数下,如4X,能够减少失真,提高结果图像的质量,但是仍然存在模糊和细节信息缺失问题;RN解决SRN存在的问题,恢复缺失信息,生成清晰且高分辨率的图像。(3) 判别网络,设计新的损失函数同时区分真假脸和是非脸,分类损失能够指导生成更清晰的人脸,使得分类更容易。
相关工作
人脸检测
人工设计特征:单尺度+金字塔;不足:(1) 耗时,(2) 特征表达能力差
CNN:Faster RCNN在FDDB数据集上效果显著,但在低分辨人脸图像上性能下降。原因:深层卷积特征的空间分辨率低,无法处理小脸。解决方法:对输入图像做上采样,(1) 内存和计算消耗大,(2) resize操作引入结构变化
SRN
超分辨率方法:需要前提假设(下采样核已知),基于CNN的超分辨率方法在无约束场景并不适用。
细化方法:传统去模糊方法(deblur method),依赖先验模型解决不适定问题,先验假设为自然图像的梯度是重尾分布;基于CNN去模糊:显式核估计,若不准确则导致大量的阶梯形失真(振铃现象)。
超分辨率和细化方法的结合(困难):已有方法是通过bicubic插值降采样+已知模糊核。
本文方法是第一次尝试联合实现超分辨率和细化无约束下的模糊小脸
GAN
GAN广泛应用,在超分辨率中也有较好的结果,但是与自然图像相比,无约束人脸图像为各种角度、光照、模糊,因此人脸图像的超分辨率更有挑战。特别是在低分辨率的人脸图像中,SRGAN得到的图像模糊且细节缺失,在人脸分类中效果并不好。
本文针对这些问题做了改进。
本文方法
GAN
损失函数:
最小化目标函数:
本文损失函数定义:
网络结构
生成网络包括上采样子网络和细化子网络,其中,前者将低分辨率输入图像转化为超分辨率图像,由于模糊小脸细节信息缺失,以及MSE损失的影响,超分辨率图像通常也是模糊的,因此,本文设计了细化子网络对超分辨率图像进行细化。
判别网络在通用的GAN判别网络中加入了分类分支,使得判别器能够分类是/非脸,同时区分真/假脸。

生成网络
(1) 包含两小步反卷积层,每个卷积层用学得的卷积核将图像上采样2X;(2) 连接一个细化子网络;(3) 除最后一层,使用BN和ReLU
步骤:上采样子网络将图像变为4X超分辨率图像(由于离相机较远或移动,图像存在模糊现象),细化子网络将模糊的超分辨率图像变为清晰的超分辨率图像
判别网络
(1) VGG19后端网络;(2) 将conv5层的最大池化去掉;(3) 将全卷积层替换为两个全卷积分支
步骤:输入超分辨率图像,输出该图像是真脸的概率,以及是人脸的概率
损失函数
传统逐像素损失和对抗损失,并将VGG特征匹配损失(计算效率问题)替换为分类损失,指导生成网络从模糊小脸中恢复细节信息
逐像素损失
通过逐像素计算MSE损失使模糊小图接近真值。
当生成图像与真实超分辨率图像损失像素级别的损失不断降低时,MSE优化问题往往缺失高频信息,产生过于平滑的纹理,这也是图像模糊的原因之一。
对抗损失
对抗损失鼓励网络生成更尖锐的高频细节信息,去欺骗判别网络,
表示重建图像是真实超分辨率图像的概率。
分类损失
第一,判断生成的超分辨率图像和真实的超分辨率图像是否是人脸;第二,促使生成网络产生更清晰的图像。
目标函数
为了better gradient behavior, 修改损失函数如下:
G生成器的损失函数:对抗损失、MSE损失和分类损失。在高频细节、像素、语义级别使重建图像与真实图像更接近。
D判别器损失函数:分类损失和对抗损失。分辨超分辨率图像是否是人脸,并行判定超分辨率图像是否是真实的。另外,分类损失使重建图像更真实。
实验
数据来源
WIDER FACE:32203图像,61类场景,三级难度(50/30/10尺寸),划分为40%/10%/50%
实现细节
参数设置
,Adam优化
生成器参数:零均值0.02方差高斯分布初始化,偏置为0;为了避免局部最优,首先使用基于MSE的SR网络初始化。
判别器参数:后端网络层,VGG19基于ImageNet预训练;全连接层,零均值0.1方差高斯分布初始化,偏置为0。
基准MB-FCN检测器:基于ResNet50网络,在ImageNet上预训练,超参数使用论文中设置的超参数。
处理技巧
训练数据:使用基线检测器从WIDER Face数据集中裁切人脸和非人脸训练集;对高分辨率图像进行下采样得到低分辨率图像,对低分辨率图像进行4X双三次插值
测试:裁切600个ROI,输入GAN网络给出最终检测结果
训练过程:3 epochs10e-4),3 epochs(10e-5),交替训练生成器和判别器。
对照实验
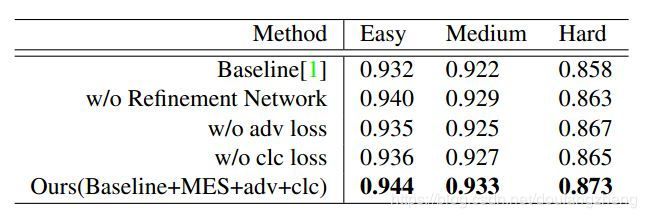
GAN
1 v.s. 5:MB-FCN
困难数据集中,AP高1.5%,因为MB-FCN网络对图像进行了下采样,丢失了大量的细节信息,如16*16的图像,c4特征图为1*1
细化网络
2 v.s. 5:细化网络
增加细化网络,困难数据集上,AP提升1%,其他数据集也提升约0.4%。因为细化网络能够减少光照和模糊的影响。
对抗损失
3 v.s. 5:AP提升1%,因为仅有分类和逐像素损失,图像会过平滑。更深入的观察发现,眼部区域的细节信息质量较差,即便该区域存在错误也会欺骗判别网络。
分类损失
4 v.s. 5:AP提升1%,因为分类损失能够指导生成器生成更细节的信息,从而使人脸判别更简单。我们发现,增加分类损失能够得到更清晰的轮廓,分析可知轮廓信息是在小而模糊的图像中判别器是/非脸的最重要的信息。

方法对比
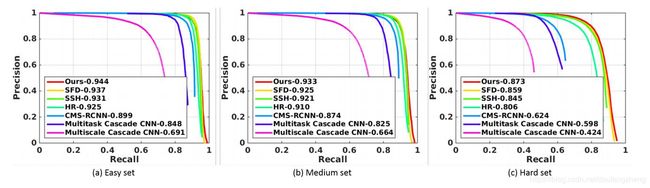

WIDER FACE:
困难数据集提升2%
与基于CNN的方法对比:(1) 上采样子网络,卷积操作中减少由于下采样带来的信息丢失,(2) 细化网络能得到细节信息和更清晰的图像,使判别更简单,(3) 分类损失能得到更清晰的人脸轮廓。
简单/中等数据集提升0.7%/0.9%:由于减轻了光照和模糊的影响
FDDB:
存在大量未标注数据,假阳性率太低时结果不准,因此我们对比假阳性样例为500时的真阳性率。
本文方法0.973,SFD是0.979,因为该方法人为增加了238个未标注样本
结果展示

结论
基于GAN提出无约束条件下小脸检测的新方法
生成网络中,设计新的网路结构,直接生成清晰超分辨率图像,端到端进行训练
判别网络中,增加分类分支,同时判定是/非脸、真/假脸
分类损失促进生成器生成更清晰的超分辨率图像