本文作者是菜哥和他的朋友们队的于畅同学,他们的项目 TiPrometheus 已经被 Prometheus adapter 合并。该项目分两个小项目,分别解决了时序数据的存储与计算问题。存储主要兼容 Prometheus 语法和数据格式,实现了精确查询、模糊查询,完全兼容现有语法。所有数据仅存在 TiKV 中。计算主要通过 TiKV 调用 Lua 实现,通过 Lua 动态扩展实现数据计算的功能。
项目简介
既然你关注了 TiDB, 想必你一定是个关注 Infrastructure 的硬汉(妹)子。监控作为 Infra 不可或缺的一环,其核心便是 TSDB(time series database) 。
TSDB 是一种以时间为主要索引的数据库,主要用来存储大量以时间为序列的指标数据,数据结构也比较简单,通常包括特征信息,指标数据和 timestamp。常见的 TSDB 包括 InfluxDB, OpenTSDB, Prometheus。
而 Prometheus 是一整套监控系统,时序数据库是它的存储部分,下面这张架构图来自于 Prometheus 官方,简单概括了其架构和生态的组成。
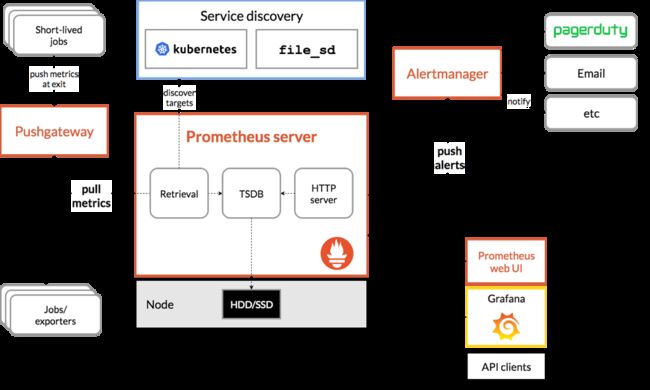
Prometheus 还支持一个图上没有体现的功能 Remote Storage,可以进行远程的读写,对查询是透明的。这个功能主要是用来做长存储。我们的项目就是实现了一个基于 TiKV 的 TSDB 来做 Prometheus 的 Remote Storage。
核心实现
Prometheus 记录的数据结构分为两部分 label, samples。label 记录了一些特征信息。samples 包含了指标数据和 timestamp。
"labels": [{
"job": "node",
"instance": "123.123.1.211:9090",
}]
"samples":[{
"timestamp": 1473305798
"value": 0.9
}]
label 和时间范围结合,可以查询到需要的 value。
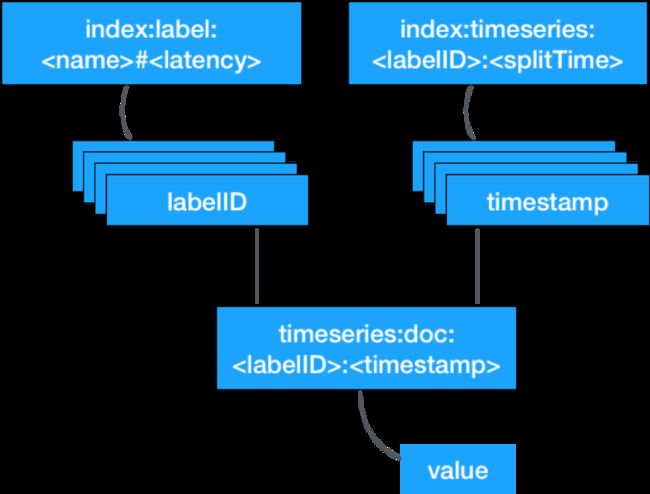
为了查询这些记录,我们需要构建两种索引 label index 和 time index,并以特殊的 key 存储 value。
label index
每对 label 为会以 index:label: 为key,labelID 为 value 存入。新的记录会追加到 value 后面。这是一种搜索中常用的倒排索引。
time index
每个 sample 项会以 index:timeseries: 为 key,timestamp 为 value。splitTime为时间切片的起始点。新的 timestamp 会追加到 value 后面。
doc 存储
我们将每一条 samples 记录以 timeseries:doc: 为 key 存入 TiKV,其中 labelID 是 label 全文的散列值。
下面做一个梳理
写入过程
生成 labelID
构建 label index,
index:label:# "labelID,labelID" 构建 time index,
index:timeseries:: "ts,ts" 写入时序数据,
timeseries:doc:: "value"
查询过程
根据倒排索引查出 labelID 的集合,多对 label 的查询会对 labelID 集合求交集。
根据 labelID 和时间范围内的时间分片查询包含的 timestamp。
根据 labelID 和 timestamp 查出所需的 value。
扯完这些没用的我们来聊些正经的。
我们为什么要做这样一个项目
在 2018 年下半年,PingCAP 组织的 Hackathon,当时作为萌新即将参加比赛,想着一定要文体两开花,弘扬开源文化。
萌生了四个想法:
TiKV TSDB
Machine Learning on TiSpark
魔改 TiKV + Lua 做成 mapreduce
geo 全文检索
核心想法
能做出来,符合参赛要求。
确实能解决生产问题而不是一个比赛项目。
摸了摸头发,觉得 ML on TiSpark 太硬核,根本做不完。
TiHaoop 也太硬核,也做不完。
geo 没在厂里的生产中遇到什么问题。
最后辗转反侧思考一番,拍脑袋决定双线操作,做基于 TiKV 的 TSDB 和 TiKV + Lua,完成时序检索功能的同时,增加更丰富的算子(比赛前两天才想好做什么)。
比赛过程
周五
原计划,提前看看 rust,作为 rust 萌新。
于是前一天和同事借了本 rust 书,准备一天速成 rust。
后来发现还是看电视剧更管用。
Day1(周六)
周六参加比赛的时候,原以为会有个很长的开场致辞,所以决定 10 点再去。
到了现场,发现大家已经开始撸代码了???
整体过程还算顺利,但其中也遇到了一些问题。
Prometheus 的依赖和 TiKV 的一些依赖不兼容,于是 fork 一份 Prometheus 依赖,野路子改两行,兼容了。
下午 5 点的时候,时序基本实现了,但联调发现有数据读写不一致的情况。因菜哥的一个 bug 导致,然后开始了漫长的 debug,一共历时 5 个小时(特别说明,我们组叫菜哥和他的朋友们)。
晚 10 点,准备回家了,不准备再 debug 了,一个 bug 查了 5 个小时。作为娱乐队,熬夜写代码是不可能。
各回各家,各找各妈。
Day2(周日)
开始漫长的半天精通 Lua 虚拟机 + rust。
也遇到了一些问题,比如为什么 TiKV 编译这么慢???一天只有 24 次编译机会???
下午 2 点,作为第一个讲的团队,我们及时生成了一个 PPT ,毕竟 PPT 工程师的基础还在。
一周后的周一
之前写的渣代码,简单写了个 README。抱着尝试的心态,给 Prometheus adapter 提了个 PR。
然后,居然被合进去了!!!
一下午写的代码居然被合进去了!!!
成果
彻底打通了 TiKV 和 Prometheus。
为 TiKV 的时序存储和计算提供了一个思路(之前做过 TiDB 存储时序数据)。
为 Prometheus 的长存储提供了一个还算好用的方案(M3 其实还可以,Thanos 是分片机制,不能算真正意义的分布式存储)。
已在公司生产环境试用,需要经过大数据量的测试,如果没问题计划替代现有方案。
感悟
参加 Hackathon,和周末加两天班没有太大的区别。
最先开始来,只是想混个奖品,比如说书包。去年参加 DevCon 给的布袋用了一年,还没坏,今年准备再领一个。
见到了很多年龄比我们小,但技术又还不错的小伙伴,比如兰海他们组,udf 那个组。也见到了一些年龄稍长的参赛者。
他们的存在,让我们在充满杂事的日常工作中又有了继续奋斗的动力。
似乎,当时选择这个行业没有错,而不仅仅是一份工作。
Just for fun。
感谢
感谢唐刘老师和申砾老师的指导。
感谢 PingCAP 举办了这场大型网友见面活动,收获颇丰。
项目地址:https://github.com/bragfoo/TiPrometheus (代码比较渣,思路供参考)
打个广告:
由菜哥和他的朋友们翻译的书:《Go 语言并发之道》已登陆京东、淘宝。
非常棒一本 Go 语言书籍,搜索即可购买。
参考资料:
- https://fabxc.org/tsdb/
- https://docs.influxdata.com/influxdb/v1.7/concepts/storage_engine/
- https://github.com/prometheus/prometheus/tree/release-1.8/storage
