记录一下个人看了一些Flink文章后的理解与个人关注点,目录如下,
0. Overview
1. 基本概念
2. 并行Dataflow
3. 基本模块
- JobManager
- TaskManagers
- Client
4. 组件栈
- Deployment层
- Runtime层
- API层
- Libraries层
5. 内部原理
- 容错机制
- 调度机制
- 迭代机制
- 反压机制
6. Reference
Overview
基于Flink 1.4。
先来看看大数据计算引擎的发展路线,
- 第一代,hadoop的MapReduce
- 第二代,DAG框架的Tez,Oozie
- 第三代,Job内部的DAG支持,以及强调实时计算,spark
- 第四代,迭代,流,批,SQL
基本概念
source -> transformation -> sink
- stream是算子的中间结果数据
- transformation是一个操作,它对一个或多个输入stream进行计算处理,输出一个或多个结果stream
- streaming dataflow是一个执行中的flink程序,启动于一个或多个source,结束于一个或多个sink

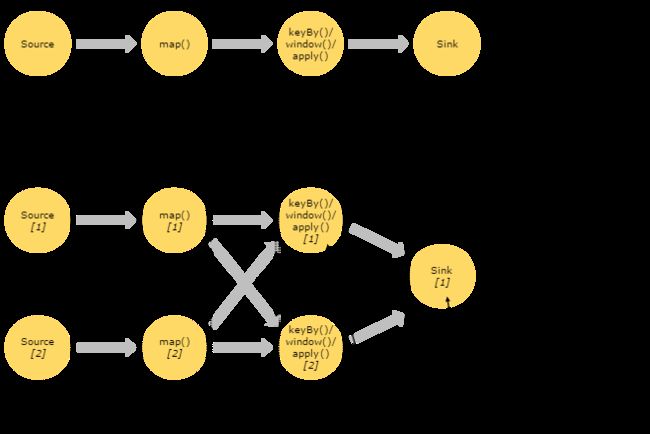
并行Dataflow
一个stream可以被分成多个stream分区(stream partition)。
一个operator可以被分成多个operator subTask。
基本模块
flink类似spark,是一个基于master-slave风格的架构。
运行时runtime主要有2个进程,一个是JobManagers,另一个是TaskManagers;client不属于运行时和程序执行的一部分,而是用于准备dataflow并将其发送到JobManager。

jobManager(master)是flink系统的协调者,负责接收flink job,调度组成job的多个task的执行;手机job的状态信息,管理flink集群中从节点taskManager,
- registerTaskManager,在Flink集群启动的时候,TaskManager会向JobManager注册
- submitJob,Flink程序内部通过Client向JobManager提交Flink Job,其中在消息SubmitJob中以JobGraph形式描述了Job的基本信息
- cancelJob,请求取消一个Flink Job的执行,CancelJob消息中包含了Job的ID
- updateTaskExecutionState,TaskManager向JobManager请求更新状态信息
- requestNextInputSplit,运行在TaskManager上面的Task,请求获取下一个要处理的输入Split
- jobStatusChanged,表示Flink Job的状态发生的变化
taskManager是一个actor(akka),负责执行计算的worker,在其上执行flink job的一组task。每个taskManager负责管理其所在节点上的资源信息,如mem, disk, network,在启动的时候将资源状态向jobManager汇报,
- 注册阶段,TaskManager会向JobManager注册,发送registerTaskManager消息
- 可操作阶段,接收并处理与Task有关的消息,如SubmitTask、CancelTask、FailTask
client,当用户提交一个flink程序时,会首先创建一个client,该client首先会对用户提交的flink程序进行预处理,并提交到flink集群中,
- client需要从用户提交的flink程序配置中获取jobManager的地址,并建立到jobManager的连接,将flink job提交给jobManager
- client会将用户提交的flink程序组装成一个jobGraph,并且是以jobGraph的形式提交。一个jobGraph是一个flink dataflow,它是由多个jobVertex组成的DAG。JobManager会将一个JobGraph转换映射为一个ExecutionGraph
组件栈
Flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件,
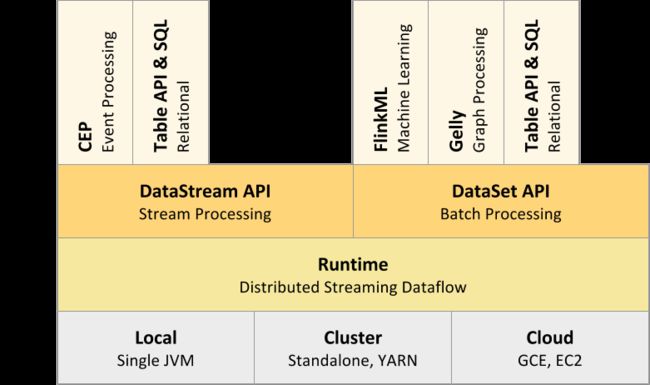
- Deployment层,涉及了Flink的部署模式

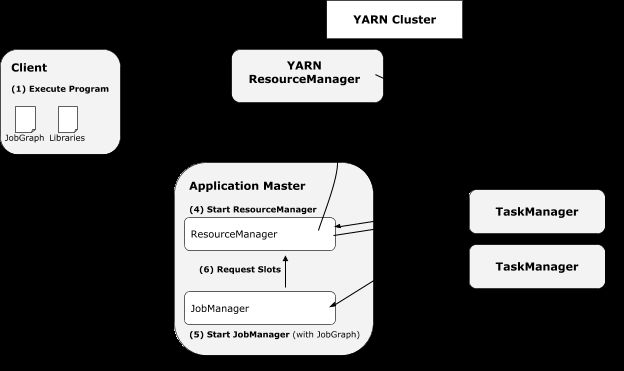
启动flink yarn session的时候,
- 最左边的模块
Flink YARN Clientcheck requested resources (containers and memory) are available,检查资源可得性 - Client uploads a jar that contains Flink and the configuration to HDFS,上传代码和配置
- Client request a
YARN containerto start theApplicationMaster(AM,单个作业的资源管理和任务监控模块,以前是一个全局的JobTracker负责的,现在每个作业都一个),启动yarn AM - AM starts allocating the containers for Flink’s TaskManagers, which will download the jar file and the modified configuration from the HDFS
客户端client负责向ResourceManager(RM)提交ApplicationMaster,并查询应用程序运行状态,ApplicationMaster(AM)负责向ResourceManager申请资源(以Container形式表示),并与NodeManager(NM)通信以启动各个Container,此外,ApplicationMaster还负责监控各个任务运行状态,并在失败是为其重新申请资源。
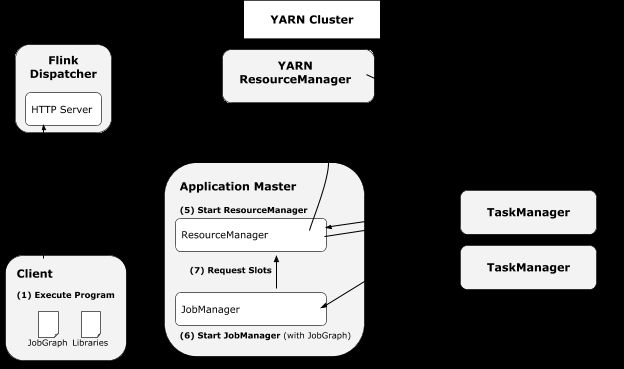
flink RM Dispatcher,用于统一发布Job并监控实例的运行。但是可以选择是否使用Dispatcher。

- Runtime层,提供了支持Flink计算的全部核心实现
- API层,实现了面向无界streaming的流处理和面向有界Batch的批处理接口
- Libraries层,Flink应用框架层,CEP复杂事件处理、Table基于SQL-like的关系操作、FlinkML机器学习、Gelly图处理
内部原理
容错机制
Flink基于Checkpoint机制实现容错,它的原理是不断地生成分布式Streaming数据流Snapshot。在流处理失败时,通过这些Snapshot可以恢复数据流处理。

checkpoint, snapshot, stream aligning, exactly once, at least once
调度机制
在jobManager,会接收到client提交的jobGraph形式的flink job,并将其转换映射为executionGraph
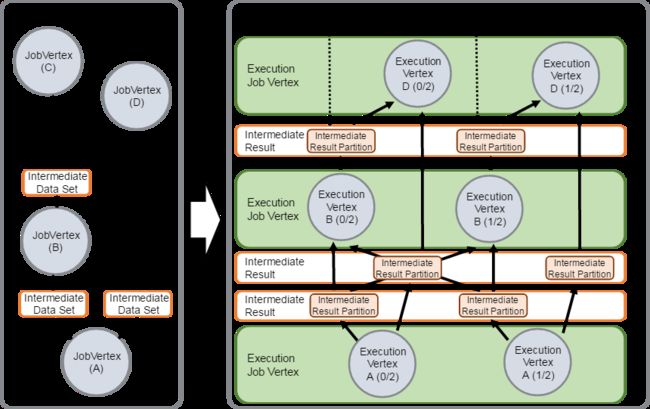
- jobGraph是一个job的用户逻辑视图表示,将一个用户要对数据流进行的处理表示为单个DAG图
- executionGraph是jobGraph的并行表示,也就是实际jobManager调度一个job在taskManager上运行的逻辑视图,也是一个DAG
上图用户提交的Flink Job对各个Operator进行的配置(从下往上),即data source的并行度设置为4(最底层1个data source,但是其parallel=4),MapFunction的并行度也为4(中间层),ReduceFunction的并行度为3(顶层)。
迭代机制
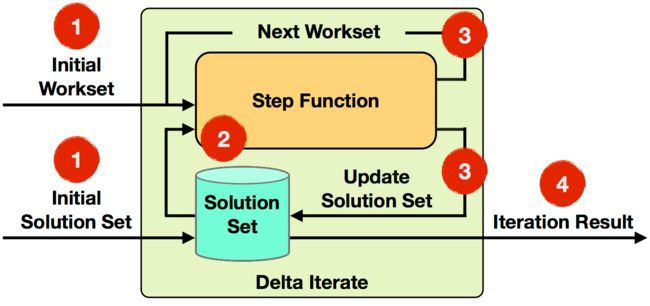
机器学习和图计算应用,都会使用到迭代计算。flink通过迭代operator中定义step函数来实现迭代算法,包括Iterate和Delta Iterate两类,

反压机制
flink使用了高效有界的分布式阻塞队列,就像java通用的blockingQueue。一个较慢的接收者会降低发送者的发送速率,因为一旦有界队列满了发送者会被阻塞。
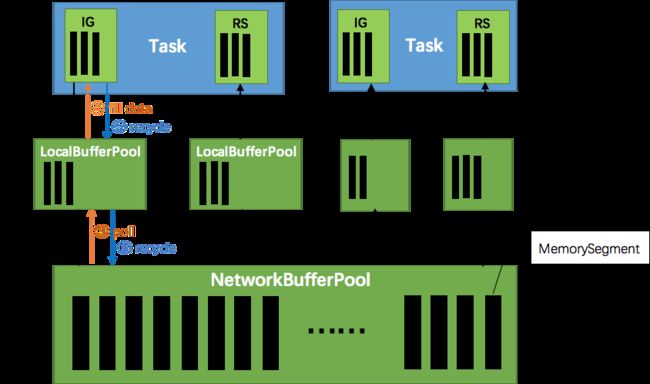
- 当netty接收端发送数据时,为了将netty中的数据拷贝到task中(往task写入数据),InputChannel会向其对应的缓冲池localBufferPool申请内存块,
- 如果localBufferPool也没有可用内存块且申请的数量还没到池子(队列)上限,则就向networkBufferPool申请内存块
- 如果localBufferPool已申请的数量达到上限了,或者networkBufferPool也没有可用内存块,此时task的netty channel会暂停读取,上游的发送端会立即响应停止发送,拓扑进入反压状态
- 当task线程写数据到resultPartition时(task数据往外写),也会向池子请求内存块,如果没有可用内存块时,也阻塞在请求内存块的地方,达到暂停写入的目的
- 在一个内存块被消费完成之后(在输出端是指内存块中的字节写入到netty channel;在输入端是指内存块中的字节被反序列化成对象),会调用buffer.recycle()方法,将内存块还给localBufferPool,如果localBufferPool中当前申请的数量超过了池子容量,则localBufferPool会将该内存块回收给networkBufferPool。如果没超池子容量,则继续留在localBufferPool中,减少反复申请的开销
backPressure在流式计算系统中用于协调上、下游operator的处理速度。因为在一个stream上进行处理的多个operator之间,它们的处理速度和方式可能非常不同,所以就存在上游operator如果处理速度过快,下游operator可能会堆积stream记录。因此,对下游operator处理速度跟不上的情况,如果下游operator能够将自己处理状态传播给上游operator,使得上游operator处理速度慢下来,从而缓解上述问题。

JobManager会反复调用Task运行所在线程的Thread.getStackTrace(),默认情况下,JobManager会每隔50ms触发对每个Task依次进行100次堆栈跟踪调用,根据调用调用结果来确定Backpressure,通过计算得到一个比值radio来确定当前运行Job的Backpressure状态。在Web界面上可以看到这个Radio值,它表示在一个内部方法调用中阻塞(Stuck)的堆栈跟踪次数,例如,radio=0.01,表示100次中仅有1次方法调用阻塞。Flink目前定义了如下Backpressure状态:
- OK: 0 <= Ratio <= 0.10
- LOW: 0.10 < Ratio <= 0.5
- HIGH: 0.5 < Ratio <= 1
Reference
- Apache Flink Documentation
- Apache Flink:特性、概念、组件栈、架构及原理分析
- Flink on Yarn(HA配置)
- 如何编写YARN应用程序
- Flink 原理与实现:如何处理反压问题
- 新一代大数据处理引擎 Apache Flink