前言
一般来说,使用一个框架是不需要分析它的源代码的,首先一款优秀的开源框架作者都对其进行了很好的封装,其次分析一款开源框架的源代码还是有点费劲的,那我为什么还要对OKHttp源码进行分析呢?如果我们只是进行简单的网络请求,那么OK,不看源代码也不影响你使用,但是如果有一些特殊需求让你在源代码的基础上加一些功能,如果不熟悉源码是很难进行的,比如上篇文章上传文件进度功能,这是阅读源码的好处之一。另外,一款优秀的开源框架内部的实现流程和设计思想还是非常值得我们去借鉴的,每一次源码的阅读何尝不是与大神们进行的一次心灵交互呢。
1 .源码分析流程
上篇文章我们已经讲述了OKHttp的优点和使用方式,所以在本篇文章我就不再对这部分内容进行赘述。
首先来回复一下一个HTTP请求流程
客户端:构建请求报文、发送请求报文
服务器:接收请求报文、解析请求报文
服务器:构建响应报文、发送响应报文
客户端:接收响应报文、解析响应报文
为了不占用过多篇幅,源码分析的过程中我会忽略一些类似于setter、getter之类的方法,只贴出核心代码
2 .Request和Response
2.1 Request
结合HTTP请求流程,我们第一步首先要构建一个HTTP请求报文,也就是Request,所以我就首先分析Request的源代码
public final class Request {
final HttpUrl url;//请求url
final String method;//请求方法
final Headers headers;//请求头字段
final @Nullable RequestBody body;//请求体
final Object tag;//请求标识
private volatile CacheControl cacheControl; // Lazily initialized.
Request(Builder builder) {
this.url = builder.url;
this.method = builder.method;
this.headers = builder.headers.build();
this.body = builder.body;
this.tag = builder.tag != null ? builder.tag : this;
}
...
...
...
}
Request具备的属性差不多就是这些,内部是通过建造者设计模式进行构建,url、method、headers、body这几个属性我们大家应该都很熟悉,这里我就着重说一下tag代表的含义,在上篇文章取消请求的代码中有用到Request的tag属性,所以tag就是一个是否取消请求的标识。
HttpUrl 和Headers 内部都是对url和head信息进行封装,也没啥技术含量,感兴趣的同学可以自己打开源码看看。下面我们来分析一下RequestBody源码
RequestBody
public abstract class RequestBody {
//获取contentType,需要实现类实现
public abstract @Nullable MediaType contentType();
//获取报文长度,默认为1,一般子类需要重写
public long contentLength() throws IOException {
return -1;
}
//进行数据的写入,BufferedSink相当于输出流
public abstract void writeTo(BufferedSink sink) throws IOException;
//构建一个RequestBody对象
public static RequestBody create(
final @Nullable MediaType contentType, final ByteString content) {
return new RequestBody() {
@Override public @Nullable MediaType contentType() {
//返回类型
return contentType;
}
@Override public long contentLength() throws IOException {
//返回长度
return content.size();
}
@Override public void writeTo(BufferedSink sink) throws IOException {
//将数据写入
sink.write(content);
}
};
}
...
...
...
}
RequestBody内部有两个抽象方法contentType()和writeTo(),需要实现类实现,contentType就是MediaType类型,writeTo()中要传入一个BufferedSink 类型对象,BufferedSink 是OKHttp封装的一个输出流,同时contentLength()一般需要重写,用来返回RequestBody的长度。在RequestBody内部也实现了几个重载的create()方法,用来创建RequestBody对象,代码中我也贴出了其中一个,它实现了两个抽象方法并重写了contentLength(),在writeTo()中通过sink.write(content)将数据写入到服务器。其他几个create()方法大都类似,就不一一讲解。
请求/响应报文的源代码基本差不多,都是head和body封装解析,所以Response源码我就不贴出来解析了,按着Request源码的分析思路相信大家是可以看懂的。
3 .RealCall和Dispatcher
请求报文封装好了,下面就要进行发送了,会使用OKHttp的同学知道,Request构建完毕后会通过OKHttpClient获取一个Call类型对象,通过Call类型对象进行网络的请求,所以请求部分源码下面我就从Call进行分析。
3.1 RealCall
public interface Call extends Cloneable {
...
}
我们看到Call是一个接口,我们来找一下它的实现类。我们打开mOkHttpClient.newCall(request);的源码
@Override
public Call newCall(Request request) {
return new RealCall(this, request, false /* for web socket */);
}
这个方法返回了一个RealCall类型对象,所以OKHttp网络请求的发起点就是RealCall,下面我们来慢慢揭开RealCall"神秘的面纱" (゜-゜)
下面我先贴出RealCall核心代码
final class RealCall implements Call {
...
...
...
@Override
public Response execute() throws IOException {
synchronized (this) {
//如果任务已经执行再次调用execute() 会抛出异常
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
try {
//将任务加入到Dispatcher中
client.dispatcher().executed(this);
//同步执行请求获取到响应结果
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} finally {
//任务结束从Dispatcher中移除
client.dispatcher().finished(this);
}
}
@Override public void enqueue(Callback responseCallback) {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
//将任务加入到Dispatcher中的线程池中执行
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
//取消任务
@Override public void cancel() {
retryAndFollowUpInterceptor.cancel();
}
/**
* NamedRunnable实现Runnable接口
* execute()方法为线程任务
*/
final class AsyncCall extends NamedRunnable {
private final Callback responseCallback;
AsyncCall(Callback responseCallback) {
super("OkHttp %s", redactedUrl());
this.responseCallback = responseCallback;
}
...
...
@Override protected void execute() {
boolean signalledCallback = false;
try {
//开始异步请求
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
//请求失败
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
//请求成功
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
responseCallback.onFailure(RealCall.this, e);
}
} finally {
//任务结束后从任务队列中移除
client.dispatcher().finished(this);
}
}
}
//开启拦截器
Response getResponseWithInterceptorChain() throws IOException {
...
...
}
}
RealCall内部封装了同步请求和异步请求,不管是同步还是异步都会将任务加入到Dispatcher中,Dispatcher内部维护了一个线程池,用于异步执行OKHttp中的网络请求操作,任务执行完毕后要将任务从Dispatcher中的任务队列中移除,关于Dispatcher下面我会详细讲解。代码中我们也能看到,真正执行网络请求操作是通过getResponseWithInterceptorChain()方法执行的,方法内创建了几个xxxInterceptor,Interceptor的意思是拦截器,是OKHttp的核心与精髓,后面我也会花大篇幅去详细讲解这几个拦截器。
3.2 Dispatcher
public final class Dispatcher {
private int maxRequests = 64;//执行最大任务数
private int maxRequestsPerHost = 5;//同一主机最大任务数
private @Nullable Runnable idleCallback;
/** Executes calls. Created lazily. */
private @Nullable
ExecutorService executorService;
//等待执行的异步任务队列
private final Deque readyAsyncCalls = new ArrayDeque<>();
//正在执行的异步任务队列
private final Deque runningAsyncCalls = new ArrayDeque<>();
//正在执行的同步任务队列
private final Deque runningSyncCalls = new ArrayDeque<>();
//自行定义线程池
public Dispatcher(ExecutorService executorService) {
this.executorService = executorService;
}
public Dispatcher() {
}
//创建线程池
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
//设置最大请求数
public synchronized void setMaxRequests(int maxRequests) {
if (maxRequests < 1) {
throw new IllegalArgumentException("max < 1: " + maxRequests);
}
this.maxRequests = maxRequests;
promoteCalls();
}
//设置同一主机最大请求数
public synchronized void setMaxRequestsPerHost(int maxRequestsPerHost) {
if (maxRequestsPerHost < 1) {
throw new IllegalArgumentException("max < 1: " + maxRequestsPerHost);
}
this.maxRequestsPerHost = maxRequestsPerHost;
promoteCalls();
}
synchronized void enqueue(RealCall.AsyncCall call) {
//当前执行任务量小于最大任务量&&当前同一主机名任务量小于同一主机名最大任务量
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
//加入到执行任务的队列
runningAsyncCalls.add(call);
//执行任务
executorService().execute(call);
} else {//加入到准备执行队列
readyAsyncCalls.add(call);
}
}
//取消所有任务
public synchronized void cancelAll() {
for (RealCall.AsyncCall call : readyAsyncCalls) {
call.get().cancel();
}
for (RealCall.AsyncCall call : runningAsyncCalls) {
call.get().cancel();
}
for (RealCall call : runningSyncCalls) {
call.cancel();
}
}
//进行任务的出队入队操作
private void promoteCalls() {
//正在执行的任务大于最大任务,直接返回
if (runningAsyncCalls.size() >= maxRequests) return;
//准备执行队列为空直接返回
if (readyAsyncCalls.isEmpty()) return;
//当执行的任务小于最大任务,则从准备队列中将任务取出并执行
for (Iterator i = readyAsyncCalls.iterator(); i.hasNext(); ) {
RealCall.AsyncCall call = i.next();
//同一主机同时执行任务数不能超出限定值
if (runningCallsForHost(call) < maxRequestsPerHost) {
//从准备队列移除
i.remove();
//加入正在执行队列
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
//将同步任务加入到队列
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}
//异步任务执行结束
void finished(RealCall.AsyncCall call) {
finished(runningAsyncCalls, call, true);
}
//同步任务执行结束
void finished(RealCall call) {
finished(runningSyncCalls, call, false);
}
//任务执行完毕
private void finished(Deque calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
//每一个任务执行完毕后都会尝试去执行新的任务
if (promoteCalls) promoteCalls();
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
...
...
...
}
以上为Dispatcher的核心代码,内部维护了一个线程池和三个任务队列readyAsyncCalls、runningAsyncCalls、runningSyncCalls,分别用来存储准备执行的异步任务、正在执行的异步任务、正在执行的同步任务,因为其内部已存在任务队列,所以线程池阻塞队列使用的是SynchronousQueue。同时开发者也可以自行定义一个线程池通过构造函数传入。OkHttp也对对大执行的任务量和同一主机同时执行任务量有所控制,但开发者也可以调用对应的set方法进行调整。说一下promoteCalls(),这个方法控制着任务从装备状态到运行状态,每一行代码我基本都标有注释,希望大家仔细的看一遍,在这我就不多进行赘述了。
疑点:
Dispatcher中不仅存储了异步任务同时保存了同步任务,有些同学可能要问,Dispatcher不是用来异步执行任务的吗?同步任务干嘛也塞里面去了,初探Dispatcher源码的时候我也是一脸懵逼,通过观察同步执行的任务的
getResponseWithInterceptorChain()确实是在调用线程中执行的,确确实实是同步执行的,只是在任务执行前将Call类型对象加入到Dispatcher中,目的就是用来保存正在执行的同步任务,最后在取消同步任务的时候会用到。
任务的执行和管理差不多就这点内容,下面我们来分析OKHttp的精髓部分拦截器,你准备好了吗?
4 .拦截器
OKHttp中内置了5个拦截器,5个拦截器分工明确各司其职,基于责任链设计模式按顺序链式启动,高度解除耦合性的同时也增强了代码的阅读性,下面我用一张图来表示几个拦截的启动顺序:
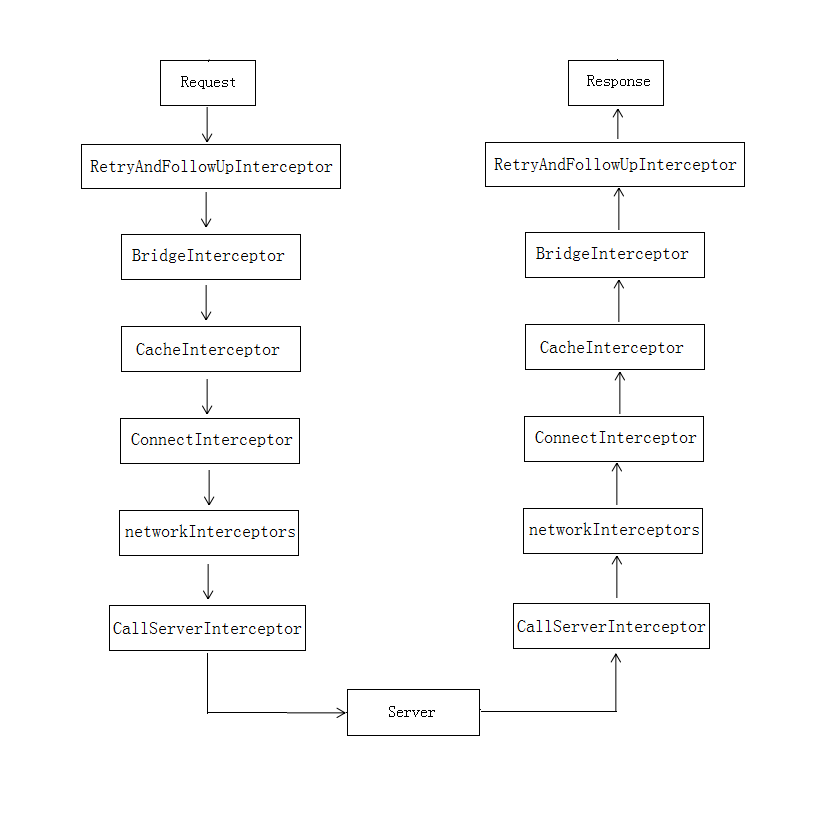
画这张图目的是让大家对拦截器的启动流程有一个基本的了解,所以图是我简化过的,省略了很多细节。整张图呈现出一个U型,跟我前面所说有的一样,基于责任链模式,按顺序链式启动,各司其职分工明确,Android中View的事件分发也是基于该设计模式。另外networkInterceptors是我们自定义的拦截器,其余五个是OKHttp内置的,一般来说,开发者基本不需要自行定义拦截器。
了解了拦截器的启动顺序后我们来逐个分析它们的源码。首先我们把getResponseWithInterceptorChain()源码给揪出来
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
return chain.proceed(originalRequest);
}
拦截器创建完毕后会传入到RealInterceptorChain这个类中,由其进行管理和启动拦截器,所以分析拦截器源码前需要搞懂RealInterceptorChain内部什么结构,有什么作用。
RealInterceptorChain
RealInterceptorChain是拦截器的一个管家,负责启动每个拦截器,并且为每个拦截器提供所需要的内容,我们来看看其核心代码:
public final class RealInterceptorChain implements Interceptor.Chain {
...
...
...
public RealInterceptorChain(List interceptors, StreamAllocation streamAllocation,
HttpCodec httpCodec, RealConnection connection, int index, Request request) {
this.interceptors = interceptors;
this.connection = connection;
this.streamAllocation = streamAllocation;
this.httpCodec = httpCodec;
this.index = index;
this.request = request;
}
@Override public Response proceed(Request request) throws IOException {
return proceed(request, streamAllocation, httpCodec, connection);
}
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException {
...
...
...
//创建一个新的RealInterceptorChain对象,将角标+1,用于启动下一个拦截器
RealInterceptorChain next = new RealInterceptorChain(
interceptors, streamAllocation, httpCodec, connection, index + 1, request);
//获取到当前拦截器
Interceptor interceptor = interceptors.get(index);
//启动拦截器
Response response = interceptor.intercept(next);
...
...
...
return response;
}
}
其中connection 、streamAllocation 、httpCodec 这些字段就是拦截器所需要的信息,大家先不要在意他们是什么,在后面我会详细讲解的,此处只需要关心拦截器的启动流程即可。procced()中首先创建了一个新的RealInterceptorChain 对象,将index+1,供下个拦截器使用,然后获取到当前的拦截器,执行当前拦截器的intercept(realInterceptorChain )启动拦截器,从此处可看出每个拦截器对应一个RealInterceptorChain 对象,会在intercept()合适的地方调用procced()启动下一个拦截器。启动大概就这么多内容,下面我们来分析第一个拦截器RetryAndFollowUpInterceptor
RetryAndFollowUpInterceptor
我们先来看一下简化后的intercept()的源码
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
//streamAllocation对象用于管理Socket连接,
//连接拦截器会用到,此处只是进行创建
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(request.url()), callStackTrace);
//当前重连的次数
int followUpCount = 0;
Response priorResponse = null;
while (true) {
//连接已经取消抛出异常
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response = null;
boolean releaseConnection = true;
try {
//开启下一个拦截器,并等待响应结果
response = ((RealInterceptorChain) chain).proceed(request, streamAllocation, null, null);
releaseConnection = false;
}
//请求出现异常后对异常进行分析,具体在recover()中进行
catch (RouteException e) {
...
} catch (IOException e) {
...
} finally {
...
}
// Attach the prior response if it exists. Such responses never have a body.
if (priorResponse != null) {
response = response.newBuilder()
.priorResponse(priorResponse.newBuilder()
.body(null)
.build())
.build();
}
//重连判断
Request followUp = followUpRequest(response);
//如果followUp==null说明不需要重连,所以直接将response返回给上一级
if (followUp == null) {
if (!forWebSocket) {
streamAllocation.release();
}
return response;
}
closeQuietly(response.body());
//重连不能超过20次
if (++followUpCount > MAX_FOLLOW_UPS) {
..
}
//因为产生重连的条件很多,比如重定向、连接失败等等。
//如果为连接失败进行重连的url是不变的,所以也没必要重新创建一个streamAllocation
//如果为重定向那么就以为这url发生了改变,必须重新构建streamAllocation
if (!sameConnection(response, followUp.url())) {
streamAllocation.release();
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(followUp.url()), callStackTrace);
} else if (streamAllocation.codec() != null) {
throw new IllegalStateException("Closing the body of " + response
+ " didn't close its backing stream. Bad interceptor?");
}
//将重新构建的请求体赋值
request = followUp;
priorResponse = response;
}
}
- 创建用于管理Socket的streamAllocation对象
- 开启一个循环用于重新连接
- 启动下一个拦截器,等待获取响应结果
- 如果请求中发生错误,会通过recover()方法判断是否可以重连
- 获取到response,通过followUpRequest(response )判断response header,方法返回null可直接返回给上一级,否则进行重新连接
- 重新连接时判断是重定向还是其他重连,如果是重定向说明url已经改变,所以要重新创建一个streamAllocation
错误分析方法recover():
private boolean recover(IOException e, boolean requestSendStarted, Request userRequest) {
streamAllocation.streamFailed(e);
// The application layer has forbidden retries.
if (!client.retryOnConnectionFailure()) return false;
// We can't send the request body again.
if (requestSendStarted && userRequest.body() instanceof UnrepeatableRequestBody) return false;
// This exception is fatal.
if (!isRecoverable(e, requestSendStarted)) return false;
// No more routes to attempt.
if (!streamAllocation.hasMoreRoutes()) return false;
// For failure recovery, use the same route selector with a new connection.
return true;
}
有四种情况是不可以进行重试的,分别是:
- 协议错误 (ProtocolException)
- 中断异常(InterruptedIOException)
- SSL握手错误(SSLHandshakeException && CertificateException)
- certificate pinning错误(SSLPeerUnverifiedException)
判断重连方法followUpRequest(response)
/**
* 内部判断连接失败的原因
* 返回null代表无法重连
*/
private Request followUpRequest(Response userResponse) throws IOException {
if (userResponse == null) throw new IllegalStateException();
Connection connection = streamAllocation.connection();
Route route = connection != null ? connection.route() : null;
//获取状态码
int responseCode = userResponse.code();
//获取方法类型
final String method = userResponse.request().method();
switch (responseCode) {
case HTTP_PROXY_AUTH://407,表示代理未授权
...
return client.proxyAuthenticator().authenticate(route, userResponse);
case HTTP_UNAUTHORIZED://表示未授权,进行授权
return client.authenticator().authenticate(route, userResponse);
case HTTP_PERM_REDIRECT:
case HTTP_TEMP_REDIRECT://如果不是GET和HEAD方法不支持重定向
if (!method.equals("GET") && !method.equals("HEAD")) {
return null;
}
case HTTP_MULT_CHOICE:
case HTTP_MOVED_PERM:
case HTTP_MOVED_TEMP:
case HTTP_SEE_OTHER://300、301、302、303均允许重定向
if (!client.followRedirects()) return null;
//获取Location字段信息
String location = userResponse.header("Location");
//location为空不需要进行重定向
if (location == null) return null;
//获取重定向的url
HttpUrl url = userResponse.request().url().resolve(location);
if (url == null) return null;
//如果已配置,请不要在SSL和非SSL之间执行重定向。
boolean sameScheme = url.scheme().equals(userResponse.request().url().scheme());
if (!sameScheme && !client.followSslRedirects()) return null;
// 大多数重定向不包括请求主体。
Request.Builder requestBuilder = userResponse.request().newBuilder();
if (HttpMethod.permitsRequestBody(method)) {
//构建request
...
...
...
}
if (!sameConnection(userResponse, url)) {
//如果与重定向的地址不同,则去掉授权头部
requestBuilder.removeHeader("Authorization");
}
return requestBuilder.url(url).build();
case HTTP_CLIENT_TIMEOUT:
if (userResponse.request().body() instanceof UnrepeatableRequestBody) {
return null;
}
return userResponse.request();
default:
return null;
}
}
- 如果返回407或401表示未授权,进行授权后返回新请求体进行重连
- 如果返回307或308,除GET和HEAD方法外不能进行重定向
- 如果返回300、301、302、303代表可以进行重定向,获取新的url构建新的请求体重新连接
RetryAndFollowUpInterceptor核心源码大概就是这些,其中proceed()分隔开了请求前、响应后的逻辑。作用大概有三点:
- 创建StreamAllocation对象,传递给后面拦截器用于管理Socket使用
- 如果中途请求失败可以选择性进行重新连接
- 判断response的状态码选择性进行重新连接
结语
这几天公司挺闲没啥工作要做,所以从早晨9点多到现在一直在写这篇文章,除去午饭时间和午休也有五六个小时了,到现在是两眼冒星!!!之前我是翻过一遍OKhttp源码,但今天再次分析的时候感觉都忘记的差不多了,好几处都卡了老半天,所以说嘛:温故而知新。原本计划用两篇文章分析完OKHttp源码,但目前来看至少要三篇,后面还有四个拦截器以及StreamAllocation、HttpCodec等等。眼睛好痛,歇了歇了,下篇文章我们再见。