blog可能排版更好点
拖了一个多星期了 都快拖到Final Presentation DDL了 我这个懒癌晚期都看不下去了
好 究竟是道德的沦丧还是人性的扭曲?欢迎来到这一期的「奇葩说之中华田园犬大解密」
在了解了基本的RNN家族之后
我们把步子迈得大一点 直接对准目前检索式 chatbots研究前沿
首先 QA系统分为任务型,非任务型两大类
任务型就是像Siri这种,需要识别用户派遣的任务,然后完成相应的任务
而非任务则是主要是闲聊机器人,购物客服机器人
非任务按Answer的生成方式 又可以分为 检索式 生成式
目前工业上落地的(效果好的)就是检索式
所以我们为了学术 (找工作) 来研究检索式对话Chatbots
检索式QA 和 生产式QA 最大的区别 就是 检索式 只需要做encode 而生成式不仅仅要encode 还要decode
这个应该很好理解 检索式 只需要 把query+Context encode 到向量 然后计算Similarity,取最高的几个
但生成式 encode计算完之后 还得根据计算值decode成语句 返回给用户
这就是他们最大的区别 当然 我们这里讨论的是检索式
Base mind
检索式对话 顾名思义 就是从一堆语料库中 通过检索 来匹配到相近的对话 从而输出答案
注意 这里有两个关键词 一个是检索 另外一个是匹配
检索就是 检查索引 所以 检索的关键就是把词变成词向量 预处理成Index
匹配就是 根据词向量 计算出一个匹配值 最简单就是计算Cosine Distance 当然这样效果很一般
于是就有一堆学者提出一堆模型
常规的做法有利用RNN家族 获取句、文章粒度的信息
然后 就开始论文串讲了
上古时代
话说 盘古还没开天 女娲还没补石 后裔还没射日
那个时候 还没有Word2vector 更不用说小学五年级就可以学得TF 对词向量的计算 还都是传统的Hash优化思路
这个时候出现了一个名叫DSSM的模型[Po-Sen Huang et al. 2013] Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
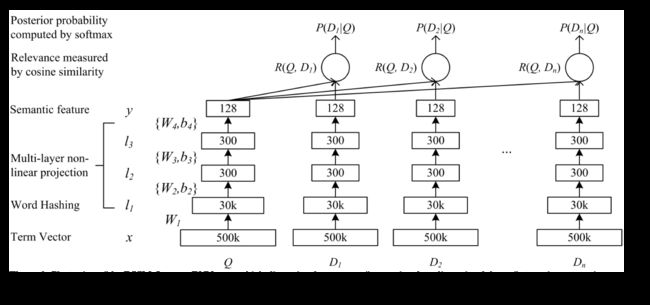
这个模型创新点有
- 利用
wordHash代替传统词袋模型 从而达到降维效果-
word Hash就是用把词前后加上#,然后每n个词做一个切割,比如说good->{#go,goo,ood,od#} - 每个切割分量作为一维向量
- 因为英文中单词数量级远大于n个字母组合的数量级
- 且这种方案的Hash碰撞率较小 3字母表示仅为
0.0044% - WordHash可以看做是
Word2Vector早期的方案 - 其基本思想每个词之间并非完全正交 然后应该没有那么多独立的维度 所以就可以压缩词向量大小
-
- 利用
全神经网络对句子进行处理得到相对应的句粒度向量- 文章利用三个隐藏层进行训练,第一个隐藏层为WordHash层有30K个节点,第二三层各有300个节点,输出层有128个节点,并使用随机梯度下降SGN训练
启蒙运动
随着word2Vec的提出 再加上NN方法在NLP中进一步运用 检索式QA有了不错的发展
但回顾之前的DSSM模型 在计算出句粒度的向量之后就直接使用cosine distance 进行计算Similarity
直观感觉这样算效果不会太好 于是这个时期就有一些学者提出一些改进Similarity计算方法的模型
MV-LSTM
就有学者提出由构造对齐矩阵 然后再做池化的方式 计算句粒度之间相似度 的MV-LSTM模型[Shengxian Wan et al. 2015]

- 计算句子间的两两匹配度存入对齐矩阵 从细粒度描述句子间关系
- 利用
双向LSTM模型 减少因为RNN时序遍历的特性 导致模型结果更偏向于最后几个单词的现象 - Similarity不只直接做cosine计算 根据模型特性动态调整参数
- 处理最后一步使用多层感知机
MLP对得到的结果进行压缩和分类 因为效果较好 这个做法在之后的论文中被广泛采用
MM
MM = Matching Matrix
这个模型[Liang Pang et al. 2016]主要是从多个角度 构造对齐矩阵 然后讲多个对齐矩阵 类比图像处理 一起喂入CNN中进行 卷积池化操作 算是交互式QA的开山之作
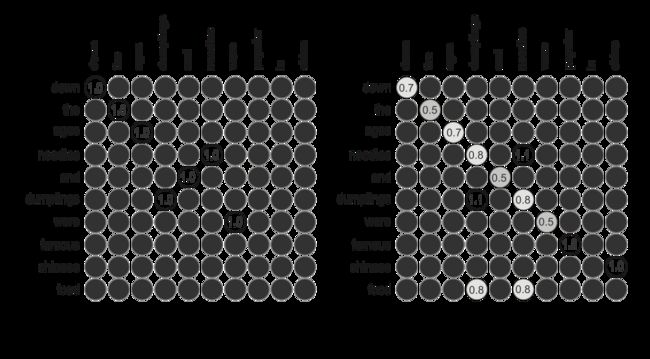
文章给出了三种对齐函数的计算方式 1. 存在判断: 该单词是否存在于另一个句子中 2. 点积 3. 余弦相似度

将多粒度分析出的对齐矩阵 通过多重卷积 进行训练
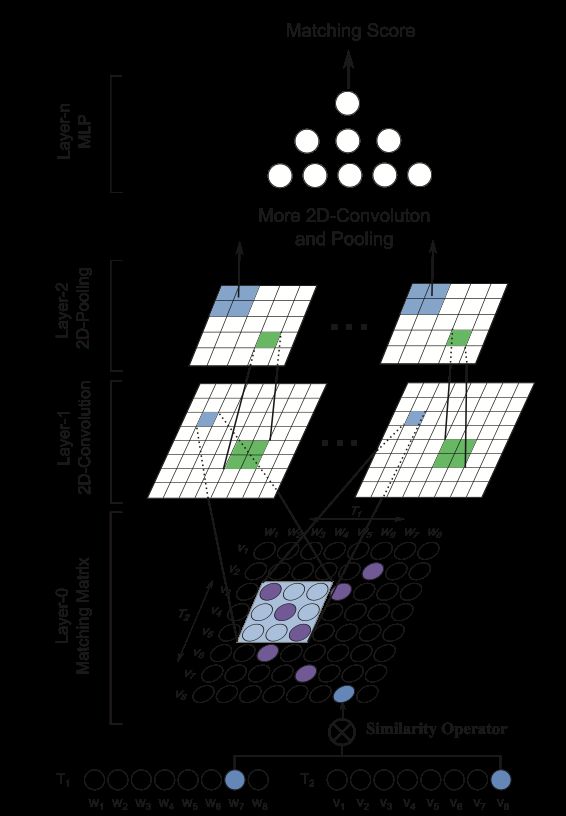
然后这种多粒度计算词、句之间关系的做法 之后发展成交互式QA 现广泛应用于检索式QA模型中
BiMPM
BiMPM = Bilateral Multi-Perspective Matching
在前面学者的基础上 进一步针对多角度句词匹配进行研究 提出BiMPM模型[Zhiguo Wang et al. 2017]
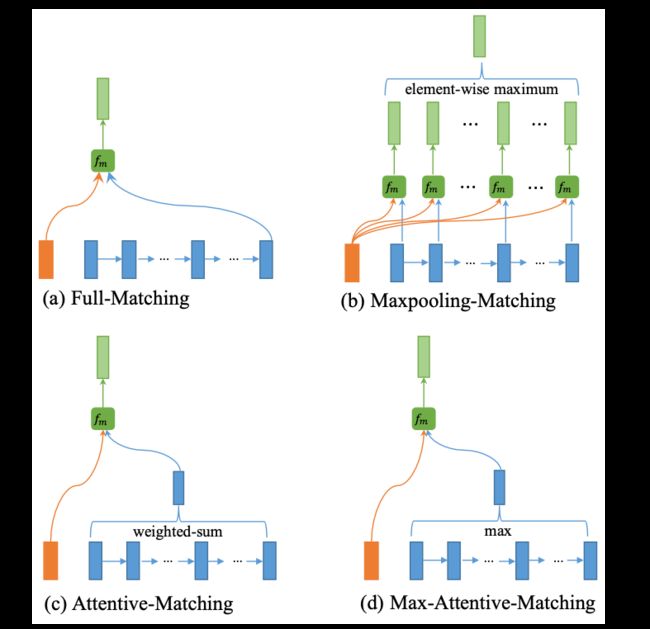
文章提出四种匹配方式
-
Full Matching: 每个单词 与 需要匹配的句子的最后一个隐藏层输出向量进行Cosine计算 -
MaxPooling Matching: 每个单词 与 需要匹配的句子的每一个单词进行Cosine计算 取Maximum -
Attentive Matching: 每个单词 与 需要匹配的句子的每一个单词行Cosine计算 然后用Softmax归一化作为attention权重然后再加权求和得到的结果再做一次Cosine -
Max Attentive Matching: 每个单词 与 需要匹配的句子的每一个单词行Cosine计算 然后用Softmax归一化 作为attention权重 然后再取最大值得到的结果再做一次Cosine
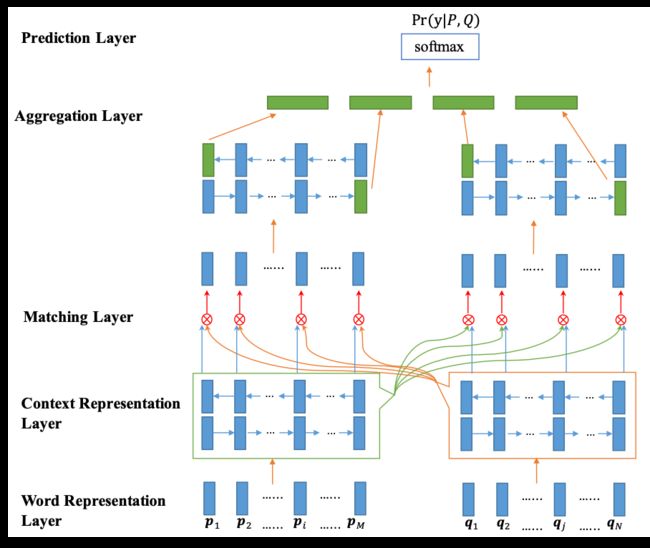
然后BiMPM还加上了双向处理 不仅考虑从Query 推出Answer 还考虑到Answer 推出 Query
工业革命
慢慢的大家发现 仅仅从词的角度 去进行检索式QA不能达到很好的效果
尤其是在多轮对话中效果并不好 于是能反映多角度关系且特别Work(这个很关键)的交互式就越来越流行
Multi-view model
说到交互式 必须 提到这篇论文Multi-view Response Selection for Human-Computer Conversation [Xiangyang Zhou et al. 2016]
虽然它不算完全使用了交互思想的论文 但算作给交互打开了一些思路
然后 看完这篇Paper LongLong Ago 才发现 这篇论文是我老师写的 (虽然他的名字 藏在最后)
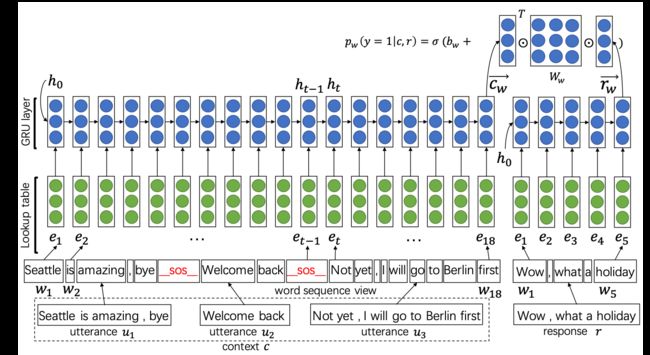
我们在研究多轮对话的时候 很简单的一个想法就是把多轮用一些标识符(比如说_SOS_)拼接成一句单句 然后这个单句就可以像上面一样计算对齐矩阵
但很显然 这样做 不会有太好的效果
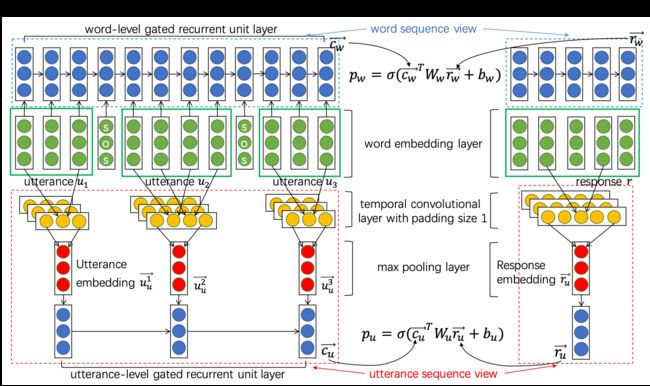
于是这篇Paper 提出通过多角度 (Word Level, Utterance Level)
Utterance是指利用CNN 进行卷积池化 得到Utterance Level的embedding squence 再经过一次Gated RNN (LSTM or GRU)过滤噪声
然后把两个维度得到的结果相加得到 最终的结果
很显然 直接相加得到的结果 不能准确的反映 多维度之间的关系 但多维度的思路对后面的论文很有帮助
SMN
SMN = Sequential Matching Network
然后 就到了大名鼎鼎的SMN [Yu Wu et al. 2017] (ym wuyu dalao)
SMN 把多粒度、基于交互的思想运用在多轮对话中

和前面的MM等模型一样 SMN采用了多粒度分析
- 一个对齐矩阵M1 是直接
Word Embedding得到的 对应的就是Word Pairs - 另外一个矩阵M2 是通过
GRU计算得到的 对应的是Segment Pairs
分别代表词粒度、句粒度
然后经过卷积、池化结合两个粒度的信息
然后再过一层GRU 过滤噪声 GRU得到的向量进行Match就可以获得匹配Score
这种多粒度的做法 保证了即使CNN很浅,也能抽取出比较high-level的特征,得到高质量的utterance embedding[9]
这篇文章 还对最后一个GRU进行优化 给出了分别利用1. 最后一个隐藏层结果 2. 中间每层的带权和 3. 结合attention的一种表示进行匹配的结果
得出dynamic 效果最优的结论
DUA
之前 我们 分析过RNNs家族的一些模型
在刚才的SMN模型中 利用了GRU获得时序信息
那么如果把GRU换成RNN的其他模型呢
就有学者提出DUA模型[Zhuosheng Zhang et al. 2018],把前面M1, M2分别换为GRU, self-attention

其实 上面这个图画的不好
- 一个对齐矩阵M1 是通过
GRU计算得到的 对应的是Segment Pairs - 另外一个矩阵M2 是先
self-attentation然后和embedding的结果拼起来 再过一次GRU- 这里的
slef-attentation没有使用position 所以没有带时序信息 于是用GRU捞一下有关时间的信息
- 这里的
之后的就和SMN基本一致 实际效果比SMN更好一点
DAM
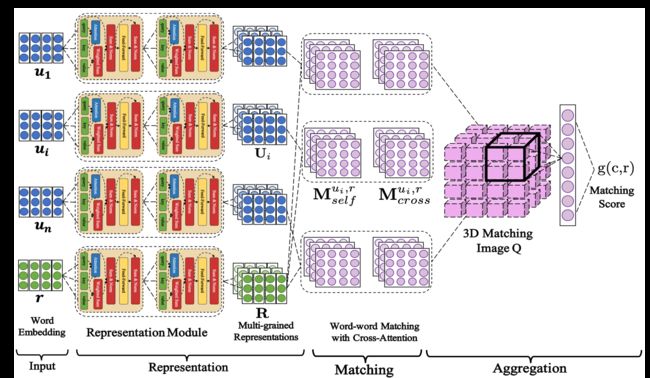
前面的SMN给了两层对齐矩阵 那么为啥选两层 不选三层 四层 100层 8848层呢
于是有dalao借助 transformer (其实 也就是 self-attentation 还记得Google Brain 那篇风骚的 Attention is All you need吧) 提出了Deep Attention Matching [Xiangyang Zhou et al. 2018]
构造了一些对齐矩阵
- 原始
word embedding矩阵 - 第一层
Attention: 多轮Contetxt和Response 每个词 - 第二层
Attention: 第一轮结果和新的Response
重复2.3H次 就可以得到1+2H层(H为Transformer 层数)对齐矩阵
再把这2H+1维对齐矩阵 喂到CNN中训练
DAM最核心的地方 在于2H层Attention的构造 Paper中给出了具体的解释证明 证明两个Attention 相互作用
目前DAM模型可以获得不错的结果
好 基本上 目前常用的模型 介绍完了 也许写完代码会有新的体会 匿了
---未完待续 期待下一个篇章---
Reference
- Learning Deep Structured Semantic Models for Web Search using Clickthrough Data [
Po-Sen Huang et al. 2013] - A Deep Architecture for Semantic Matching with Multiple Positional Sentence Representations[
Shengxian Wan et al. 2015] - Text Matching as Image Recognition [
Liang Pang et al. 2016] - Bilateral Multi-Perspective Matching for Natural Language Sentences [
Zhiguo Wang et al. 2017] - Multi-view Response Selection for Human-Computer Conversation [
Xiangyang Zhou et al. 2016] - Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots [
Yu Wu et al. 2017] - Modeling multi-turn conversation with deep utterance aggregation [
Zhuosheng Zhang et al. 2018] - Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network [
Xiangyang Zhou et al. 2018] - 小哥哥,检索式chatbot了解一下?
- 深度文本匹配发展总结