多核学习
研究图像分类,在图像特征提取方面想做一些工作,从特征融合入手,特征融合手段主要分为前期融合与后期融合两种。
前期融合:
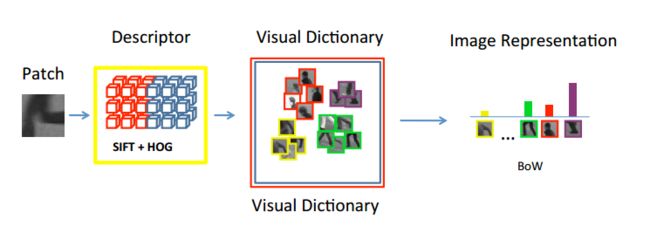
后期融合:
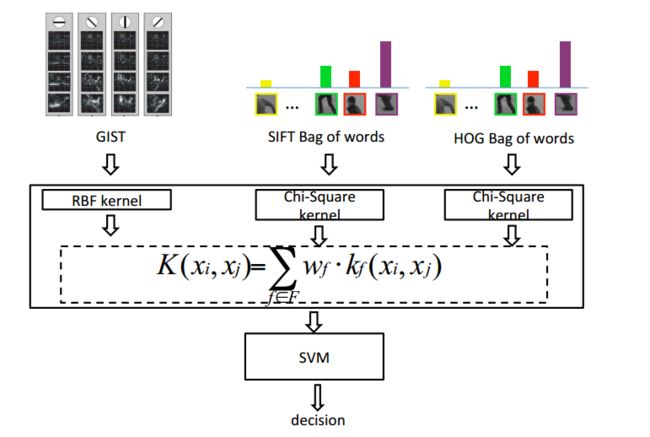
在看文章《On Feature Combination for Multiclass Object Classification》时,后期融合方法(MKL)时发现这两篇文章,很有启发:
一、多核学习在图像分类中的应用
1摘要
分类在搜索引擎中的应用非常广泛,这种分类属性可以方便在rank过程中针对不同类别实现不同的策略,来更好满足用户需求。本人接触分类时间并不长,在刚用SVM做分类的时候对一个现象一直比较困惑,看到大家将各种不同类型特征,拼接在一起,组成庞大的高维特征向量,送给SVM,得到想要的分类准确率,一直不明白这些特征中,到底是哪些特征在起作用,哪些特征组合在一起才是最佳效果,也不明白为啥这些特征就能够直接拼在一起,是否有更好的拼接方式?后来了解到核函数以及多核学习的一些思想,临时抱佛脚看了点,对上面的疑问也能够作一定解释,正好拿来和大家一起探讨探讨,也望大家多多指点。本文探讨的问题所列举的实例主要是围绕项目中的图像分类展开,涉及SVM在分类问题中的特征融合问题。扩展开来对其他类型分类问题,理论上也适用。
关键词: SVM 特征融合 核函数 多核学习
2基本概念阐述
SVM:支持向量机,目前在分类中得到广泛的应用
特征融合:主要用来描述各种不同的特征融合方式,常见的方式有前期融合,就是前面所描述的将各个特征拼接在一起,后期融合本文后面会提到
核函数:SVM遇到线性不可分问题时,可以通过核函数将向量映射到高维空间,在高维空间线性可分
多核学习:在利用SVM进行训练时,会涉及核函数的选择问题,譬如线性核,rbf核等等,多核即为融合几种不同的核来训练。
3应用背景
在图片搜索中,会出现这样的一类badcase,图像的内容和描述图像的文本不一致,经常会有文本高相关,而图像完全不一致的情况。解决这类问题的一个思路就是综合利用图像的内容分类属性和文本的query分类属性,看两者的匹配程度做相应策略。
4分类方法的选取
下面就可以谈到本文的重点啦,那是如何对图像分类的呢?
对分类熟悉的同学,马上可能要说出,这还不easy,抽取各种特征,然后一拼接,随便找个分类器,设定几个参数,马上分类模型文件就出来啦,80%准确率没问题。
那这个方法确实不错也可行,但是有没有可以改进的地方呢?
这里可能先要说明下图像分类的一些特殊性。
图像的分类问题跟一般的分类问题方法本质上没太大差异,主要差异体现在特征的抽取上以及特征的计算时间上。
图像特征的抽取分为两部分,一部分是针对通用图像的特征,还有一部分则是针对特定类别抽取的特征。这些特征与普通的文本特征不一致的地方在于,一个图像特征由于存在分块、采样、小波变换等,可能维度就已经很高。譬如常见的MPEG-7标准中提到的一些特征,边缘直方图150维,颜色自相关特征512维等。在分类过程中,如果将这些特征拼接在一起直接就可能过千维,但是实际在标注样本时,人工标注的正负样本也才几千张,所以在选择分类器时,挑选svm,该分类器由于可以在众多分类面中选择出最优分界面,以及在小样本的学习中加入惩罚因子产生一定软边界,可以有效规避overfitting。
在特征的计算时间上,由于图像处理涉及的矩阵计算过多,一个特征的计算时间慢的可以达到0.3秒,所以如何挑选出既有效又快速的特征也非常重要。
5两种特征融合方式的比较
那刚才的方法有什么问题呢?
仔细想想,大致存在以下几点问题:
1. 你所提取的所有特征,全部串在一起,一定合适么?如果我想知道哪些特征组合在一起效果很好,该怎么办?
2. 用svm进行学习时,不同的特征最适合的核函数可能不一样,那我全部特征向量串在一起,我该如何选择核函数呢?
3. 参数的选取。不同的特征即使使用相同的核,可能最适合的参数也不一样,那么如何解决呢?
4. 全部特征都计算,计算时间的花销也是挺大的
对于刚才的问题,如果用前期融合,可能是用下面方式来解决:
1. 根据经验,觉得在样本中可能表现不错的特征加进来,至于组合么,全部串在一起,或者选几个靠谱的串一起,慢慢试验,慢慢调,看哪些特征有改进就融合在一起
2. 也是根据经验,选取普遍表现不错的RBF核,总之结果应该不会差
3. 交叉验证是用来干嘛的?验证调优参数呗,全部特征融合在一起,再来调,尽管验证时间长,不要紧,反正模型是离线训练的,多调会也没关系。
那是否有更好的选择方案呢?
多核学习(MKL)可能是个不错的选择,该方法属于后期融合的一种,通过对不同的特征采取不同的核,对不同的参数组成多个核,然后训练每个核的权重,选出最佳核函数组合来进行分类。
先看下简单的理论描述:
普通SVM的分类函数可表示为:
其中为待优化参数,物理意义即为支持向量样本权重,用来表示训练样本属性,正样本或者负样本,为计算内积的核函数,为待优化参数。
其优化目标函数为:
其中用来描述分界面到支持向量的宽度,越大,则分界面宽度越小。C用来描述惩罚因子,而则是用来解决不可分问题而引入的松弛项。
在优化该类问题时,引入拉格朗日算子,该类优化问题变为:
其中待优化参数在数学意义上即为每个约束条件的拉格朗日系数。
而MKL则可认为是针对SVM的改进版,其分类函数可描述为:
其中,表示第K个核函数,则为对应的核函数权重。
其对应的优化函数可以描述为:
在优化该类问题时,会两次引入拉格朗日系数,参数与之前相同,可以理解为样本权重,而则可理解为核函数的权重,其数学意义即为对每个核函数引入的拉格朗日系数。具体的优化过程就不描述了,不然就成翻译论文啦~,大家感兴趣的可以看后面的参考文档。
通过对比可知,MKL的优化参数多了一层其物理意义即为在该约束条件下每个核的权重。
Svm的分类函数形似上是类似于一个神经网络,输出由中间若干节点的线性组合构成,而多核学习的分类函数则类似于一个比svm更高一级的神经网络,其输出即为中间一层核函数的输出的线性组合。其示意图如下:
在上图中,左图为普通SVM示例,而全图则为MKL示例。其中为训练样本,而为不同的核函数,为支持向量权重(假设三个训练样本均为支持向量),为核权重,y为最终输出分类结果。
6实验过程:
以实际对地图类别的分类为例,目前用于分类的特征有A,B,C,D,E,F,G(分别用字母代表某特征),这些特征每个的维数平均几百维。
准备工作:
1. 人工标注地图类别正负样本,本次标注正样本176张,负样本296张
2. 提取正负训练样本图片的A~G各个特征
3. 归一化特征
4. 为每个特征配置对应的核函数,以及参数
工具:
Shogun工具盒:http://www.shogun-toolbox.org/,其中关于该工具的下载,安装,使用实例都有详细说明。该工具除了提供多核学习接口之外,几乎包含所有机器学习的工具,而且有多种语言源码,非常方便使用。
结果测试:
经过大约5分钟左右的训练,输出训练模型文件,以及包含的核函数权重、准确率。
在该实例中,7个特征分别用七个核,其权重算出来为:
0.048739 0.085657 0.00003 0.331335 0.119006 0.00000 0.415232,
最终在测试样本上准确率为:91.6%
为了节省特征抽取的时间,考虑去掉权重较小的特征A、C、F,
拿剩下4个核训练,几分钟后,得到核函数权重如下:
0.098070 0.362655 0.169014 0.370261,
最终在测试样本上准确率为:91.4%
在这次训练中,就可以节约抽取A、C、F特征的训练时间,并且很快知道哪些特征组合在一起会有较好的结果。
实验的几点说明:
1. 该类别的分类,因为样本在几百的时候就已经达到不错效果,所以选取数目较少。
2. 该实验是针对每个特征选择一个核,且每个核配置固定参数,实际中如果时间允许,可以考虑每个特征选不同核,同一核可以选取不同参数,这样可以得到稍微更好的结果。
参考文章:
Large Scale Multiple Kernel Learning
SimpleMKL
Representing shape with a spatial pyramid kernel
参考代码:http://www.shogun-toolbox.org/doc/cn/current/libshogun_examples.html,
7个人经验与总结:
1. 多核学习在解释性上比传统svm要强。多核学习可以明显的看到各个子核中哪些核在起作用,哪些核在一起合作效果比较好。
2. 关于参数优化。曾经做过实验,关于同一特征选用同一核,但是不同参数,组合成多个核,也可以提升分类准确率。
3. 多核学习相比前期特征融合在性能上会有3%~5%左右的提升。
4. 通过特征选择,可以节约特征计算时间。
原文来源:http://stblog.baidu-tech.com/?p=1272
二、多核学习总结
什么是核:(核或正定核) 定义在上的函数是核函数,如果存在一个从到Hilbert空间的映射
(1.1)
使得对任意的,
(1.2)
都成立。其中表示Hilbert空间中的内积。
多核学习的本质就是用K个核函数凸组合代替上述的单个核函数且满足
k≥O且 ,k=1,2,...,K。可用来理解样本的哪个特征能更有效地区分样本。
多核学习的优点
当样本特征含有异构信息(Heterogeneous information),样本规模很大, 多维数据的不规则(Unnormaliseddata)或数据在高维特征空间分布的不平坦, 采用单个简单核进行映射的方式对所有样本进行处理并不合理。
多核学习的研究
多核模型是一类灵活性更强的基于核的学习模型, 在多核框架下, 样本在特征空间中的表示问题转化成为基本核与权系数的选择问题。
研究人员大都研究(1)核函数权系数的选择问题。如非平稳的多核学习方法, 局部多核学习方法,非稀疏多核学习方法等(2)多核学习理论。如早期的基于Boosting的多核组合模型学习方法, 基于半定规划(Semide¯nite programming, SDP) 的多核学习方法, 基于二次约束型二次规划(Quadratically constrained quadratic program, QCQP)的学习方法, 基于半无限线性规划(Semi-in¯nitelinear program, SILP)的学习方法, 基于超核(Hyperkernels)的学习方法, 以及近来出现的简单多核学习(Simple MKL)方法和基于分组Lasso思想的多核学习方法。
多核学习的算法流程
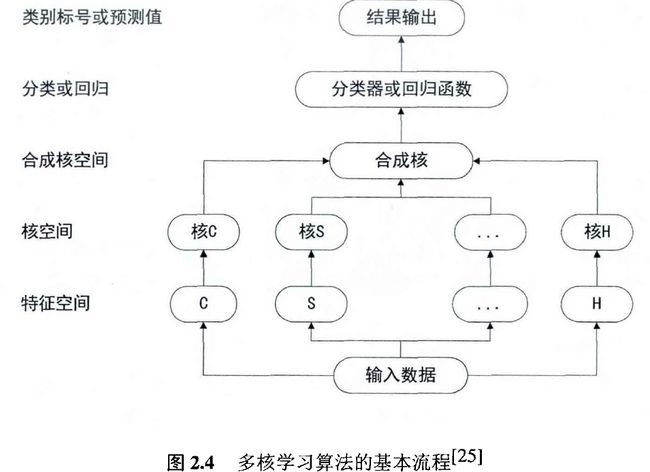
多核学习缺点:
尽管多核学习在解决一些异构数据集问题上表现出了非常优秀的性能,但不得不说效率是多核学习发展的最大瓶颈。首先,空间方面,多核学习算法由于需要计算各个核矩阵对应的核组合系数,需要多个核矩阵共同参加运算。也就是说,多个核矩阵需要同时存储在内存中,如果样本的个数过多,那么核矩阵的维数也会非常大,如果核的个数也很多,这无疑会占用很大的内存空间。其次,时间方面,传统的求解核组合参数的方法即是转化为SDP优化问题求解,而求解SDP问题需要使用内点法,非常耗费时间,尽管后续的一些改进算法能在耗费的时间上有所减少,但依然不能有效的降低时间复杂度。高耗的时间和空间复杂度是导致多核学习算法不能广泛应用的一个重要原因。
参考文献:多核学习方法
基于多核学习的高性能核分类方法研究