【论文】轻量级网络squeezenet论文的详细翻译
前言:
整体上翻译了squeezenet:AlexNet-level accuracy with 50X fewer paramenters and 0.5MB model size.这篇论文,便于英文基础不好的同行进行阅读,由于时间仓促,难免有很多错误,请在评论区指出错误并提出宝贵意见,我会及时修正。
论文地址:aqueezenet论文
SQUEEZENET: ALEXNET-级别精度50X 较少的参数和 < 0.5MB模型大小
摘要
深卷积神经网络 (CNNs) 最近的研究主要集中在提高精度。对于给定的精度级别, 通常可以确定多个 CNN 体系结构, 以达到该精度级别。同样的精度, 较小的 CNN 架构提供至少三优点:
(1) 较小的 CNNs 在分布式训练过程中需要跨服务器进行更少的通信。
(2) 较小的 CNNs 需要更少的带宽, 将一个新的模型从云端导出到自动汽车。【译者注:这是针对自动驾驶汽车来说的】
(3) 较小的 CNNs 提供了在 fpga 和其他内存有限的硬件上部署的可行性。
综上, 我们提出了一个叫做 SqueezeNet 的小型 CNN 架构。SqueezeNet 在 ImageNet 上达到 AlexNet 级精度, 参数减少50x【译者注:即参数减少50倍,下同】。此外, 使用模型压缩技术, 我们可以将 SqueezeNet 压缩到小于 0.5MB (比AlexNet小510×).
SqueezeNet 体系结构可在此处下载: https://github.com/DeepScale/SqueezeNet
1 简介和研究动力
最近对深卷积神经网络 (CNNs) 的研究主要集中在提高计算机视觉数据集的精确度上。对于给定的精度级别, 通常可以用不同的 CNN 体系结构来实现了该精度级别。而具有更少参数的 CNN 体系结构具有以下几个优点:
· 更高效的分布式训练。服务器之间的通信是分布式 CNN 训练的可扩展性的重要限制因素。对于分布式数据并行训练, 通信开销与模型中的参数数目成正比 (Iandola 等, 2016)。简而言之, 小模型由于需要较少的通信量而得以快速地训练。
· 向客户端导出新模型时的开销更小。为了优化自主驾驶技术, 特斯拉等公司定期将新的训练模型从服务器复制到客户的车上。此做法通常称为远程更新。消费者报告发现, 特斯拉的自动驾驶仪半自主驱动功能的安全性随着最近的更新而逐步提高 (消费者报告, 2016)。然而, 今天典型的 CNN/DNN 模型频繁的远程更新可能需要大量的数据传输。与 AlexNet相比, 这将需要从云服务器传输240MB的数据量到汽车上。较小的模型只需要传输较少的数据量, 这使得频繁更新变得更加可行。
可行的 FPGA 和嵌入式部署。 fpga 通常有小于 10MB的 onchip 内存, 并且不存在外部存储。因此, 一个足够小的模型可以直接存储在 fpga 上, 而不是被内存带宽所限制 (邱等, 2016), 而视频帧流通过 FPGA 实时。此外, 当在特定于应用程序的集成电路 (ASICs) 上部署 CNNs 时, 一个足够小的模型可以直接存储在芯片上, 而较小的模型可以使 ASIC 适合于较小的模型。例如, Xilinx Vertex-7 FPGA 的芯片内存最大为 8.5 mb (即 68 Mbits), 不提供外部存储空间。
较小的 CNN 架构有太多的优点。考虑到这一点, 我们的研究目标聚焦于在准确度不下降的情况下设计一个需要更少参数的CNN网络结构,我们发现了这样的一个体系结构, 我们称之为SqueezeNet。此外, 我们提出了一个更具有流程化的方法来搜索新的 CNN 架构的设计空间。
论文的其余部分按如下方式组织。在第2部分中, 我们回顾相关的工作。然后, 在3和4节中, 我们描述和评估 SqueezeNet 体系结构。之后, 我们将注意力转向了解 CNN 建筑设计方案如何影响模型的大小和准确性。我们通过探索 SqueezeNet 体系结构的设计空间来获得这种理解。在5节中, 我们设计了CNN 微体系结构的空间探索, 我们将其定义为各个层和模块的组织和维度。在6节中, 我们对cnn 宏观体系结构进行了设计空间探索, 我们将其定义为 cnn 中层次结构的高层组织。最后, 我们在7节总结。简而言之, 3 和4节对于 CNN 研究人员以及只想将 SqueezeNet 应用于新应用程序的从业者都很有用。其余部分针对的是打算设计自己的 CNN 架构的高级研究人员。
2 相关工作
2.1 模型压缩
我们工作的首要目标是确定一个模型, 它的参数很少, 同时保持精度。为了解决这个问题, 可行的做法是采取现有的 CNN 模型, 并以有损的方式压缩它。事实上, 在一些研究团体已经开始围绕着这个思路进行了探索,并发表了几种方法。一个由Denton et al提出的相当简单的方法,是将奇异值分解 (SVD) 应用于预训练CNN模型 (2014)。Han et发名了一种网络修剪方法,即从一个预训练模型开始, 然后用零替换低于某个阈值的参数, 形成一个稀疏矩阵, 最后在稀疏 CNN 上执行一些训练迭代 (han等, 2015b)。最近, han et通过将网络修剪与量化 (8 比特或更少) 和霍夫曼编码结合在一起, 以创建一种称为深压缩的方法 (EIE, 2015a), 并进一步设计了一个名为EIE的硬件加速器,它直接运行在压缩的模型之上, 实现了提高模型运行速度和节省大量运算资源的效果。
2.2 CNN 微结构
从LeCun et al.在二十世纪八十年代下旬推广CNNs 数字识别应用以来 (LeCun 等, 1989),卷积网络已在人工神经网络中使用了至少25年在神经网络中, 卷积过滤器通常有3个维度, 以高度、宽度和通道为关键尺寸。当应用到图像时, CNN 过滤器通常在第一层 中有3个通道(即 RGB) , 并且在随后的每一层中,过滤器的通道数与 Li −1 CNN卷积的个数相同。早期的工作由 LeCun et al。(LeCun et 等, 1989) 使用 5x5xChannels[1] 卷积, 最近的 VGG (Simonyan & Zisserman, 2014) 体系结构广泛使用3x3卷积模型, 如网络在网络 (林等, 2013) 和 GoogLeNet 的建筑 (Szegedy 等, 2014;约飞 & Szegedy, 2015;Szegedy 等, 2015;2016) 在某些层中使用1x1 卷积。
而在CNNs网络结构越来越深的大趋势下, 手动选择每个层的过滤尺寸变得很麻烦。为了解决这一问题, 提出了由多个卷积层组成的各种更高级别的构建块或模块。例如, GoogLeNet 文件提出了初始化模块, 它由许多不同的卷积组成, 通常包括1x1 和 3x3, 加上有时 5x5 (Szegedy et, 2014), 有时1x3 和 3x1 (Szegedy 等)。2015). 然后将许多这样的模块组合起来, 也许还有其他的(ad-hoc)层来组成一个完整的网络. 我们使用CNN 微体系结构【CNN microarchitecture】一词来引用各个模块的特定组织和维度。
2.3 CNN 宏观结构
虽然微体系结构是指单个层和模块, 但我们将CNN macroarchitecture定义为多个模块的系统级组织, 使其成为一个端到端的 CNN 架构。
也许在最近的文献中广泛研究的 CNN macroarchitecture 主题是网络中深度(即层数) 的影响。Simoyan 和 Zisserman 提出了层数大概在12到19层的VGG (Simonyan & Zisserman, 2014) 网络, 并在论文中指出, 更深的网络在ImageNet-1k 数据集上回获得更高的准确性 (Den等, 2009)。k. He et. 提出了更深层次的 CNNs ,网络层数多达30层, 同样在ImageNet数据集上也获得了更高的精度 (He等, 2015a)。
跨多个层或模块的连接选择是 CNN macroarchitectural 研究的一个新兴领域。残差网络 (ResNet) (He等, 2015b) 和HighwayNetworks (Srivastava等, 2015)都建议使用跳过多个层的连接, 例如将第3层的激活层连接到第6层的激活层上。我们将这些连接称为旁路连接。对于一个34层的CNN网络结构,ResNet 的作者提供了有旁路连接和没有旁路连接的比较,添加旁路连接使Top-5 ImageNet数据集上的准确度增加了2个百分点。
2.4 网络设计空间探索
神经网络 (包括深度网络和卷积神经网络) 具有很大的设计空间, 比如说microarchitectures、macroarchitectures的设计和其他超参数的选择。自然而然地, 很多研究机构希望凭借直觉得到关于这些因素如何影响神经网络的准确性 (即设计空间的形状)。神经网络设计空间探索的大部分工作都侧重于开发自动化的方法, 以找到更高精度的神经网络体系结构。这些自动化方法包括贝叶斯优化 (Snoek et, 2012), 模拟退火 (Ludermir 等, 2006), 随机搜索 (Bergstra & Bengio, 2012) 和遗传算法 (Stanley & Miikkulainen, 2002)。值得赞扬的是,每一篇论文都提供了一个案例,在这个案例中,提出的DSE方法产生了一个NN体系结构,与一个具有代表性的基础神经网络相比,它的精确度的确更高。然而, 这些论文并没有试图提供关于神经网络设计空间形状的直觉。在本文的后面, 我们避开了自动化的方法-相反, 我们通过重构 CNNs 的方式, 这样就就可以做A/B的比较, 从而可以探索出CNN 架构是如何影响模型的大小和准确性的。
在下面的章节中, 我们首先提出和评估了 SqueezeNet 网络结构, 并没有模型压缩。然后, 我们探讨了微体系结构和 宏观体系结构中的设计选择对 SqueezeNet 型 CNN 架构的影响。
3 SQUEEZENET: 使用少量参数保持精度
在本节中, 我们首先概述了 CNN 体系结构的设计策略, 这些参数很少。然后, 我们介绍Fire模块这个我们的新构建块, 以构建整个CNN网络结构。最后, 我们使用我们的设计策略来构造SqueezeNet, 它主要由Fire模块组成。
3.1 结构设计策略
本文的首要目标是确定在保持准确性的同时, 有几个参数的 CNN 架构。为了实现这一点, 我们在设计 CNN 架构时采用了三个主要策略:
策略 1. 用1x1 滤镜替换3x3 滤镜。考虑到一定数量的卷积的预算, 我们将选择大量使用1x1卷积, 因为1x1 卷积的参数比3x3 过滤器少了 9X.
策略 2. 减少3x3 卷积输入通道的数量。假设有一个卷积层, 它完全由3x3 卷积组成。此层中参数的总数量为:(输入通道数) * (过滤器数) * (3 * 3)。因此, 为了在 CNN 中得到更少的参数, 不仅要减少3x3 过滤器的数量 (参见上面的策略 1), 还要减少3x3 卷积中输入通道的数量。我们使用squeeze层将输入通道的数量减少, 在下一节中我们将对其进行描述。
策略 3. 在网络中延迟下采样的时间, 以便卷积层具有较大的特征图。在卷积网络中, 每个卷积层输出一个特征图, 这些特征图的高度和宽度由以下内容控制: (1) 输入数据的大小 (如256x256 图像) 和 (2)在CNN 体系结构中缩减像素采样的层的选择。最常见的情况是, 下采样通过在某些卷积或池层中设置 ( > 1) 在 CNN 体系结构中进行设计 (例如 (Szegedy 等), 2014;Simonyan & Zisserman, 2014;Krizhevsky 等, 2012))。如果前边在网络中有很大的步长, 那么大多数图特征入将有小的激活映射。 反之, 如果网络中的前边的层都有1的步长, 并且超过1的步长集中在网络的后半部分 , 则网络中的许多层将具有大的激特征图。我们的直觉是, 在其他不变的情况下,大的特征图 (由延迟下采样产生) 可以导致更高的分类精度 。的确, K.He和 h. Sun 将延迟下采样率应用到四种不同的 CNN 体系结构中, 在每种情况下, 延迟下采样都会导致分类精度变高 (He& Sun, 2015).【这里所说的下采样应该就是指池化】
策略1和2是关于在尽可能保持模型准确度地情况下减少 CNN 的参数数量,。策略3是关于在有限的参数数量下最大化精度。接下来, 我们描述的Fire模块, 将使我们能够成功地使用战略 1, 2 和3。
3.2 Fire Model
我们定义Fire模块如下。一个Fire模块包括: 一个squeeze层 (只有1x1 卷积), 将其放入一个具有1x1 和3x3 卷积组合的expand层中(图1)。在Fire模块中随意使用1x1 过滤器是应用3.1节中的策略1。在一个Fire模块中有三个超参数: s1x1, e1x1和 e3x3。在Fire模块中, s1x1 是squeeze层 (所有 1x1) 中的过滤器数, e1x1是1x1 卷积在expand层的数量, e3x3 3x3卷积在expand层的数量,。当我们使用Fire模块时, 我们设置 s1x1 小于 (e1x1 e + 3x3 ), 因此, expand层有助于限制3x3卷积中输入通道的数量即3.1节中的策略 2。
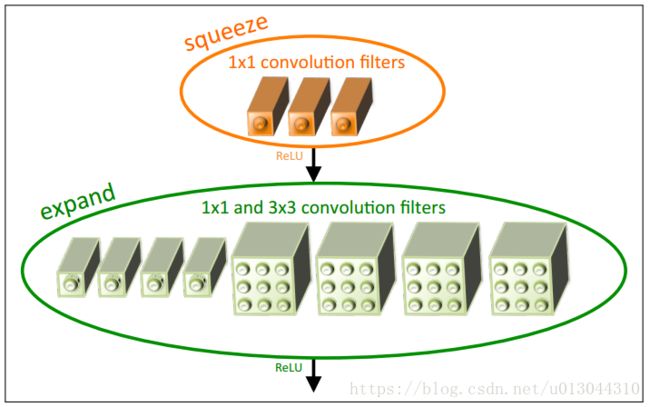
图 1: Microarchitectural 视图: 在Fire模块中组织卷积结构。在这个例子中, s1x1 = 3, e1x1 4, e 3x3 = 4。我们只展示卷积, 并没有展示激活层.
3.3 SQUEEZENET 体系结构。
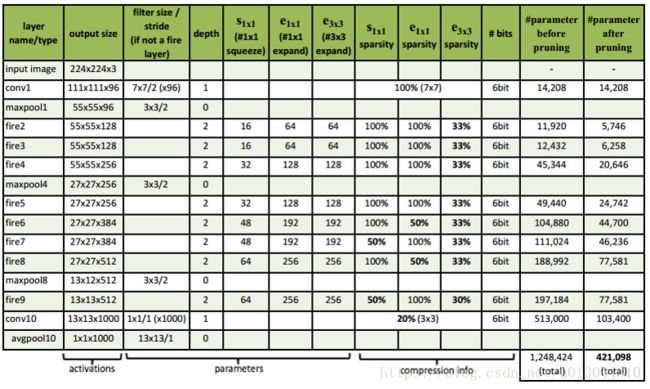
我们现在描述了 SqueezeNet CNN 的架构。我们在图2中说明了 SqueezeNet 从一个独立的卷积层 (conv1) 开始, 后跟8个Fire模块 (fire2-9), 最后 conv 层 (conv10) 结束。从开始到网络的末端,我们逐渐增加每个Fire模块的卷积的数量。
SqueezeNet 在层 conv1、fire4、fire8 和 conv10 之后执行最大池化, 其步长为 2;这些相对较晚地执行池化操作是在执行3.1节的策略3。我们在表1中展示了完整的 SqueezeNet 体系结构。

3.3.1 其他SQUEEZENET 细节
为了简洁起见, 我们省略了表1和图2中有关 SqueezeNet 的详细信息和设计选项的数量。我们提供以下这些设计选择。这些选择背后的直觉可以在下面引用的论文中找到。
(1)为了使 1∗11∗1 和 3∗33∗3 filter输出的结果又相同的尺寸,在expand modules中,给3∗33∗3 filter的原始输入添加一个像素的边界(zero-padding)。
(2)squeeze 和 expand layers中都是用ReLU作为激活函数
(3)在fire9 module之后,使用Dropout,比例取50%
(4)注意到SqueezeNet中没有全连接层,这借鉴了Network in network的思想 (5)训练过程中,初始学习率设置为0.04,在训练过程中线性降低学习率。更多的细节参见本项目在github中的配置文件。
(6)由于Caffee中不支持使用两个不同尺寸的filter,在expand layer中实际上是使用了两个单独的卷积层(1∗11∗1 filter 和 3∗33∗3 filter),最后将这两层的输出连接在一起,这在数值上等价于使用单层但是包含两个不同尺寸的filter。
在github上还有SqueezeNet在其他框架下的实现:MXNet、Chainer、Keras、Torch。
表 1: SqueezeNet 的体系结构尺寸。(此表的格式来自Inception2论文 )
4 评估SQUEEZENET
接下来,我们对SqueezeNet网络进行一个评估 。在2.1 节中提到的 CNN 模型压缩论文中, 目标是压缩一个 AlexNet 网络, 它使用 ImageNet (Deng et al.2009) (ILSVRC 2012) 数据集训练后可以对图像进行分类。因此, 在评估 SqueezeNet 时, 我们使用 AlexNet[4] 和相关的模型压缩结果作为比较的基准。
在表2中, 我们将最近的模型压缩结果 和SqueezeNet网络做一个对比。可以看到:SVD 方法可以将 AlexNet 模型压缩为以前的5x, 同时会使top-1 数据集上的精度降低到 56.0% (丹顿 et, 2014)。网络修剪实现了模型尺寸的9x 降低, 同时保持了 top-1数据集上 57.2%的精度和top-5数据集上 80.3% 的精度 (Han等人, 2015b)。深压缩达到35x 的模型尺寸压缩比率, 同时仍然保持以往的精度 (Han等, 2015a)。现在, 使用 SqueezeNet网络, 我们实现了减少50X 的模型压缩比率, 同时满足或超过 AlexNet 的 top-1 和 top-5 的准确性。
我们似乎已经超过了目前模型压缩所取得的最新成果: 即使使用未压缩的32位值来表示模型, SqueezeNet 也在保持或超过原本正确率的基础上有一个1.4× 的模型压缩比,这相比于目前模型压缩所取得的最新成果还要好一些。
同时,直到现在, 一个开放的问题是:是易于压缩的小模型, 还是小模型 “需要” 由稠密浮点值提供的所有代表力?为了找出, 我们应用了深压缩 (韩等, 2015a) 表 2: 比较 SqueezeNet 模型压缩方法。通过模型大小, 我们的意思是存储经过培训的模型中所有参数所需的字节数。
SqueezeNet, 使用33% 稀疏[5] 和8位量化. 这将生成一个 0.66 MB 的模型 (363× 小于32位 AlexNet), 并具有与 AlexNet 等效的精度。此外, 在 SqueezeNet 上应用6位量化和33% 稀疏度的深压缩, 我们生成一个0.47MB 模型 (510× 小于32位 AlexNet), 具有等效的精度。我们的小模型确实可以压缩。
此外, 这些结果表明, 深压缩 (韩等, 2015a) 不仅在 CNN 的体系结构具有许多参数 (如 AlexNet 和 VGG), 但它也能够压缩已经紧凑, 完全卷积 SqueezeNet建筑。通过10×压缩 SqueezeNet 的深层压缩, 同时保留基线精度。总而言之: 通过将 CNN 的体系结构创新 (SqueezeNet) 与最先进的压缩技术 (深压缩) 结合在一起, 我们实现了一个 510× 在模型大小上的缩减, 与基线相比, 精确度没有降低。
最后, 请注意, 深压缩 (han等, 2015b) 使用码书作为其方案的一部分, 将 CNN 参数量化为6或8位精度。因此, 在大多数初级商品处理器上, 使用在深压缩中开发的方案, 以8位量化或的速度加速的速度是不是微不足道的. 但是, 韩et。开发的自定义硬件-有效推理引擎 (EIE) -可以更有效地计算码书量化 CNNs (汉族等人, 2016a)。此外, 在我们发布 SqueezeNet 后的几个月中, p Gysel 开发了一个称为Ristretto的策略, 用于线性量化 SqueezeNet 为8位 (Gysel, 2016)。具体地说, Ristretto 在8位中进行计算, 并在8位数据类型中存储参数和激活。在 SqueezeNet 推理中, 使用8位计算的 Ristretto 策略, 在使用8位而不是32位数据类型时, Gysel 观察到精度下降的小于1的百分比。**
5 CNN 微体系结构设计空间探索
到目前为止, 我们已经提出了小模型的结构设计策略, 遵循这些原则来创建 SqueezeNet, 并发现 SqueezeNet 比 AlexNet 小 50x的同时保持了相同的精度。然而, SqueezeNet 甚至是其他模型知识广阔的未探索的 CNN 架构的设计空间里的一种。现在, 在5和6节中, 我们探讨了设计空间的几个方面。我们将此体系结构探索分为两个主要主题: microarchitectural 探测(每个模块层的维度和配置) 和macroarchitectural 探测(模块的高级端到端组织和其他层)。
在本节中, 我们设计并执行实验, 目的是提供关于 microarchitectural 设计空间形状的直觉, 就我们在3.1 节中提出的设计策略而言。请注意, 我们在这里的目标不是在每个实验中实现最大的精确度, 而是要了解 CNN 架构选择对模型大小和准确性的影响。
5.1 CNN 微体系结构参数
在 SqueezeNet 中, 每个Fire模块都有三个超参数, 即我们在3.2 节中定义的: s1x1 , e1x1 和 e3x3 。SqueezeNet 有8个Fire模块, 共24个超参数。为了对 SqueezeNet 体系结构的设计空间进行广泛的遍历, 我们定义了以下一组更高层次的超参数 , 它控制了 CNN 中所有Fire模块的尺寸。
这里论文描述得有点繁琐,精简如下:
我们定义 basee b a s e e 作为 CNN 中第一个Fire模块中expand层卷积的数目。在之后的每个Fire模块( freq f r e q ), 我们我们通过 incre i n c r e 来增加expand层的数量。换句话说,我们对于第i层的FIre模块,expand层的卷积数目通过公式: ei=basee+(incre∗|ifreq|) e i = b a s e e + ( i n c r e ∗ | i f r e q | ) 来确定,同时,在每一层的 ei,1x1+ei,3x3 e i , 1 x 1 + e i , 3 x 3 的选择上,我们定义“ pct3x3 p c t 3 x 3 ”(相当于 3x3 3 x 3 在整个expand所占的概率)这个参数,通过 ei,3x3=ei∗pct3x3 e i , 3 x 3 = e i ∗ p c t 3 x 3 和 ei,1x1=ei∗(1−pct3x3) e i , 1 x 1 = e i ∗ ( 1 − p c t 3 x 3 ) 来确定。
最后,对于squeeze层,定义“squeeze ratio(SR)”参数,通过 si,1x1=SR∗ei s i , 1 x 1 = S R ∗ e i 来确定。
比如说,对于表1来说, SqueezeNet 具有以下超参数 (metaparameters): basee=128,incre=128,pct3x3=0.5,freq=2,SR=0.125 b a s e e = 128 , i n c r e = 128 , p c t 3 x 3 = 0.5 , f r e q = 2 , S R = 0.125 .
【译者注:简单来说,公式的意义如下:
- 第一个模块中的expand层中包含base个卷积;每隔freq个fire模块,增加incre个卷积。
- expand层中,3×3卷积占expand层中卷积比例为pct。
- squeeze层中卷积数与expand层中卷积数比例为SR。】
5.2 压缩比(SR)
在3.1 节中, 我们建议减少参数的数目, 方法是使用squeez层减少3x3 卷积的输入通道数。我们将压缩比率 (SR)定义为squeeze层中的卷积个数与expand层中的卷积个数之间的比值。我们现在设计了一个实验来研究压缩比对模型尺寸和精确度的影响。
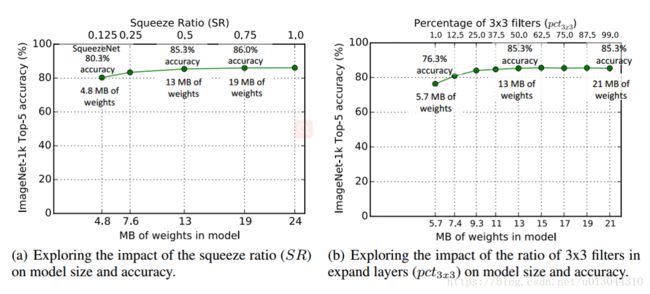
在这些实验中, 我们使用 SqueezeNet (图 2) 作为起点。与 SqueezeNet 中一样, 这些实验使用以下 metaparameters: basee=128,incre=128,pct3x3=0.5,freq=2 b a s e e = 128 , i n c r e = 128 , p c t 3 x 3 = 0.5 , f r e q = 2 。我们培训多个模型, 其中每个模型有一个不同的压缩比 (SR),他们在范围 [0.125, 1.0]内变化。 在图 3 (a) 中, 我们展示了这个实验的结果, 在图上的每个点都是一个独立的模型, 从头开始训练。SqueezeNet 是SR = 0.125的点。 从这个数字我们知道, 在SR= 0.125时增加SR 可以进一步增加 ImageNet top-5 精度(从 80.3% (4.8MB)到86.0% (19MB)) 峰值在86.0% ( SR = 0.75 ,模型大小为19MB ), 并且设置 SR = 1.0 进一步增加了模型的大小,却没有提高准确性。
5.3 训练时关闭1X1和3X3卷积核
在3.1 节中, 我们建议通过用1x1 卷积替换一些3x3 卷积来减少 CNN 的参数数目。一个开放的问题是, CNN 过滤器中的空间分辨率有多重要?
VGG (Simonyan & Zisserman 2014) 体系结构在大多卷积层中都充斥着3x3 的卷积;GoogLeNet (Szegedy 等, 2014) 和NiN (林等, 2013)在某些层里有1x1 的卷积。在 GoogLeNet 和NiN, 作者简单地提出了具体数量的1x1 和3x3 卷积没有进一步的分析。在这里, 我们试图阐明1x1 和3x3 过滤器的比例对模型大小和精度的影响.
我们在本实验中使用以下 metaparameters: basee=128,incre=128,SR=0.5,freq=2 b a s e e = 128 , i n c r e = 128 , S R = 0.5 , f r e q = 2 , 并且我们让 pct3x3 p c t 3 x 3 从1% 到99%变化 。换句话说, 每个Fire模块的expand层有一个预定义的数量的过滤器划分在1x1 和3x3 之间,
在这里,我们把“旋钮”从 “大多数是1x1卷积” 调节到 “大多数是 3x3卷积”。与以前的实验一样, 这些模型有8个FIre模块, 与图2中的层组织相同。我们在图 3 (b) 中显示了这个实验的结果。请注意, 图 3 (a) 和图 3 (b) 中的13MB 模型是相同的体系结构: SR = 0.500 和 pct3x3=50 p c t 3 x 3 = 50 %。我们在图 3 (b) 中看到, 在3x3 卷积占比为50%时,ImageNet数据集上的精度会达到85.6% , 当进一步增加了3x3 卷积的百分比时,只增加了模型的大小, 但没有提高 ImageNet数据集上的准确性。
6 CNN 宏观体系结构设计空间探索
到目前为止, 我们已经探索了微体系结构层面的设计空间, 即CNN网络各个模块的内容。现在, 我们在 macroarchitecture 级别上探讨了有关Fire模块之间高层连接的设计决策。灵感来自 ResNet (He等, 2015b), 我们探索了三种不同的体系结构:
· Vanilla SqueezeNet (按前一节).
· SqueezeNet 在某些Fire模块之间进行简单的旁路连接。
· SqueezeNet 在Fire模块之间使用复杂的旁路连接。
我们在图2中画出了这三种 SqueezeNet 的变体。
我们的简单旁路体系结构在3、5、7和9的Fire模块附近添加旁路连接, 要求这些模块在输入和输出之间学习残差函数。与 ResNet 一样, 要实现围绕 Fire3 的旁路连接, 我们将输入设置为 Fire4 等于 (Fire2 + 输出 Fire3 的输出), 其中 + 运算符为数组加法。这改变了正规化应用于这些消防Fire模块的参数, 并且, 根据 ResNet, 可以提高最终的准确度。
一个限制是, 在简单的情况下, 输入通道的数量和输出通道的数量必须相同;因此, 只有一半的Fire模块可以有简单的旁路连接, 如图2的中间图所示。当无法满足 “相同数量的通道” 要求时, 我们使用复杂旁路连接, 如图2的右侧所示。虽然一个简单的旁路是 “只是一个导线,” 我们定义一个复杂的旁路作为旁路, 包括一个1x1 卷积层与数量的过滤器设置等于数量的输出通道。需要注意的是, 复杂的旁路连接会向模型中添加额外的参数, 而简单旁路连接则不会。
除了改变正规化我, 我们还可以比较直观地看到: 增加旁路连接将有助于减轻squeeze层引入的瓶颈。例如:在 SqueezeNet中, 挤压比 (SR) 是 0.125, 这意味着每个squeeze层的输出通道比expand层少8倍。由于这种严重的通道数减少, 只有很少的信息可以通过expand层。但是, 通过将旁路连接添加到 SqueezeNet网络中, 我们打开了信息的通道, 使信息可以在不同的squeeze层之间传输。
我们按照图2中的三种结构训练了 SqueezeNet网络, 并比较了表3中的精度和模型大小。我们修正了微体系结构以匹配 SqueezeNet, 如表1在整个探索中所述。复杂和简单的旁路连接相比于基础的SqueezeNet结构,准确性得以改善。有趣的是, 简单的旁路使得精确度的提高比复杂的旁路更高。
7 总结
本文对卷积神经网络的设计空间探索提出了更严格的方法。针对这个目标, 我们提出了 SqueezeNet——一个 CNN 体系结构, 它的参数比 AlexNet少50×, 并且在 ImageNet 上保持 AlexNet 级别的准确性。我们还将 SqueezeNet 压缩到小于 0.5MB, 或比不进行任何压缩的 AlexNet小510倍。自从我们在2016年发布这篇论文作为一份技术报告以来, Song han和他的合作者对 SqueezeNet 和模型压缩进行了进一步的实验。使用一种新的方法, 称为Dense-Sparse-Dense (DSD) (Han等, 2016b), han et al.在训练过程中使用模型压缩作为 regularizer, 以进一步提高准确性, 在 ImageNet-1k 上生成一组压缩的 SqueezeNet 参数, 其精度是1.2 百分点, 而且还产生一组未压缩的 SqueezeNet 参数与表2中的结果相比。我们在本文的开头提到, 小模型更适于 fpga 上的芯片实现。自从我们发布了 SqueezeNet 模型后, Gschwend 开发了 SqueezeNet 的变体, 并在 FPGA 上实现了它 (Gschwend, 2016)。正如我们所预料的那样, Gschwend 能够完全在 FPGA 内存储 SqueezeNet 样模型的参数, 并消除了对负载模型参数的非芯片内存访问的需要。
在本文的背景下, 我们将 ImageNet 作为目标数据集。然而, 将 ImageNet 训练的 CNN 表示法应用于各种应用, 如细粒度对象识别, 图像标识 (Iandola 等, 2015), 并生成关于图像语义 (方等, 2015)。ImageNettrained CNNs 也适用于一些有关自主驾驶的应用, 包括在图像中的行人和车辆检测 (Iandola 等, 2014;Girshick 等, 2015;阿什拉夫等, 2016) 和视频 (陈等, 2015b), 以及分割道路的形状 (Badrinarayanan 等, 2015)。我们认为 SqueezeNet 将是一个很好的候选人 CNN 架构的各种应用, 特别是那些小模型的大小是重要的。
SqueezeNet 是我们在广泛探索 CNN 体系结构设计空间时发现的几种新 CNNs 之一。我们希望 SqueezeNet 能激励读者考虑和探索 CNN 架构设计空间中广泛的可能性, 并以更系统的方式进行探索。
关于本论文的几点思考:
在项目中用过这个模型,确实很给力,在准确度不怎么变化的情况下可以使模型的参数减少很多。以往的压缩模型设计思路,都是在现有模型的基础上进行一些有损压缩,修修补补,但作者在这里另辟蹊径,直接根据他制定的三种可以使模型参数减少的策略设计了一种全新的模型,而且效果还不错。
对于大多数人来说,只要使用这个模型就够了,但是论文中作者花大量篇幅介绍的压缩模型的设计思路还是值得设计模型的研究员们借鉴的。