结合实例阐述K近邻算法(含代码)
一.K近邻算法简介
K-近邻算法(KNN)概念
K Nearest Neighbor算法又叫KNN算法
-
定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
-
距离公式
两个样本的距离可以通过如下公式计算,又叫欧氏距离
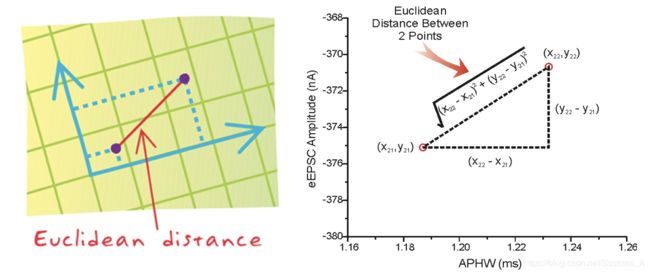
二维平面的点 a ( x 1 , y 1 a(x_1,y_1 a(x1,y1与 b ( x 2 , y 2 ) b(x_2,y_2) b(x2,y2)
d 12 = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 d_{12}=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2} d12=(x1−x2)2+(y1−y2)2
三维空间的点 a ( x 1 , y 1 , z 1 ) a(x_1,y_1,z_1) a(x1,y1,z1)与 b ( x 2 , y 2 , z 2 ) b(x_2,y_2,z_2) b(x2,y2,z2)
d 12 = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 + ( z 1 − z 2 ) 2 d_{12}=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2+(z_1-z_2)^2} d12=(x1−x2)2+(y1−y2)2+(z1−z2)2
n维空间的点 a ( x 1 , x 2 , ⋯ , x n ) a(x_1,x_2,\cdots,x_n) a(x1,x2,⋯,xn)与 b ( y 1 , y 2 , ⋯ , y n ) b(y_1,y_2,\cdots,y_n) b(y1,y2,⋯,yn)
d 12 = ∑ k = 1 n ( x k − y k ) 2 d_{12}=\sqrt{\sum_{k=1}^{n}(x_k-y_k)^2} d12=∑k=1n(xk−yk)2
二.k近邻算法api
机器学习流程:
2.1 Scikit-learn工具
- Scikit-learn包含的内容
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
2.2 K-近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
- n_neighbors:int,可选(默认=5),k_neighbors查询默认使用的是邻居数
2.3案例
- 获取数据集
- 数据基本处理
- 特征工程
- 机器学习
- 模型评估
from sklearn.neighbors import KNeighborsClassifier
# 构造数据集
x = [[0], [1], [2], [3]]
y=[0, 0, 1, 1]
# 模型训练
# 实例化API
estimator = KNeighborsClassifier(n_neighbors=2)
# 使用fit方法进行训练
estimator.fit(x, y)
estimator.predict([[1]])
2.4小结
k近邻算法实现流程
- 计算已知类别数据集中的点与当前点之间的距离
- 按距离递增次序排序
- 选取与当前点距离最小的k个点
- 统计前k个点所在的类别出线的频率
- 返回前k个点出线频率最高的类别作为当前点的预测分类
三.距离度量
3.1欧氏距离
二维平面上的点 a ( x 1 , y 1 ) a(x_1,y_1) a(x1,y1)与 b ( x 2 , y 2 ) b(x_2,y_2) b(x2,y2)
d 12 = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 d_{12}=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2} d12=(x1−x2)2+(y1−y2)2
三维空间上的点 a ( x 1 , y 1 , z 1 ) a(x_1,y_1,z_1) a(x1,y1,z1)与 b ( x 2 , y 2 , z 2 ) b(x_2,y_2,z_2) b(x2,y2,z2)
d 12 = ( x 1 − y 1 ) 2 + ( x 2 − y 2 ) 2 + ( z 1 − z 2 ) 2 d_{12}=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+(z_1-z_2)^2} d12=(x1−y1)2+(x2−y2)2+(z1−z2)2
n维空间上的点 a ( x 1 , x 2 , ⋯ , x n ) a(x_1,x_2,\cdots,x_n) a(x1,x2,⋯,xn)与 b ( y 1 , y 2 , ⋯ , y n ) b(y_1,y_2,\cdots,y_n) b(y1,y2,⋯,yn)
d 12 = ∑ k = 1 n ( x k − y k ) 2 d_{12}=\sqrt{\sum_{k=1}^{n}(x_k-y_k)^2} d12=∑k=1n(xk−yk)2
3.2曼哈顿距离
二维平面两点 a ( x 1 , y 1 ) a(x_1,y_1) a(x1,y1)与 b ( x 2 , y 2 ) b(x_2,y_2) b(x2,y2)的曼哈顿距离
d 12 = ∣ x 1 − y 1 ∣ + ∣ x 2 − y 2 ∣ d_{12}=|x_1-y_1|+|x_2-y_2| d12=∣x1−y1∣+∣x2−y2∣
n维空间的两点 a ( x 1 , x 2 , ⋯ , x n ) a(x_1,x_2,\cdots,x_n) a(x1,x2,⋯,xn)与 b ( y 1 , y 2 , ⋯ , y n ) b(y_1,y_2,\cdots,y_n) b(y1,y2,⋯,yn)的曼哈顿距离
d 12 = ∑ k = 1 n ∣ x k − y k ∣ d_{12}=\sum_{k=1}^{n}|x_k-y_k| d12=∑k=1n∣xk−yk∣
3.3切比雪夫距离
国际象棋中,国王可以横行、直行、斜行,国王从一个格子走到另一个格子的最短距离就叫切比雪夫距离。
二维平面两点 a ( x 1 , y 1 ) a(x_1,y_1) a(x1,y1)与 b ( x 2 , y 2 ) b(x_2,y_2) b(x2,y2)间的切比雪夫距离
d 12 = m a x ( ∣ x 1 − x 2 ∣ , ∣ y 1 − y 2 ∣ ) d_{12}=max(|x_1-x_2|,|y_1-y_2|) d12=max(∣x1−x2∣,∣y1−y2∣)
n维度空间点 a ( x 1 , x 2 , ⋯ , x n ) a(x_1,x_2,\cdots,x_n) a(x1,x2,⋯,xn)与 b ( y 1 , y 2 , ⋯ , y n ) b(y_1,y_2,\cdots,y_n) b(y1,y2,⋯,yn)
d 12 = m a x ( ∣ x i − y i ∣ ) d_{12}=max(|x_i-y_i|) d12=max(∣xi−yi∣)
3.4闵可夫斯基距离
闵式距离不是一种距离,而是一组距离的定义,是多个距离公式的概括性的表述。
两个n维变量 a ( x 1 , x 2 , ⋯ , x n ) a(x_1,x_2,\cdots,x_n) a(x1,x2,⋯,xn)与 b ( y 1 , y 2 , ⋯ , y n ) b(y_1,y_2,\cdots,y_n) b(y1,y2,⋯,yn)间的闵可夫斯基距离定义为:
d 12 = ∑ k = 1 n ∣ x k − y k ∣ p p d_{12}=\sqrt[p]{\sum_{k=1}^n|x_k-y_k|^p} d12=p∑k=1n∣xk−yk∣p
闵可夫斯基距离的缺点:
- 将各个变量的量纲,也就是“单位”相同的看待了
- 未考虑各个变量的分布(期望、方差等)可能是不同的
3.5标准化欧氏距离
是对欧氏距离的缺点而做的一种改进
思路:既然数据各维分量的分布不一样,那先将各分量都“标准化”到均值、方差相等。假设样本集X的均值(mean)为m,标准差为s,X的“标准化变量”表示为:
n维空间点 a ( x 1 , x 2 , ⋯ , x n ) a(x_1,x_2,\cdots,x_n) a(x1,x2,⋯,xn)与点 b ( y 1 . y 2 , ⋯ , y n ) b(y_1.y_2,\cdots,y_n) b(y1.y2,⋯,yn)的标准化欧式距离公式:
d 12 = ∑ k = 1 n ( x k − y k S k ) 2 d_{12}=\sqrt{\sum_{k=1}^n(\frac{x_k-y_k}{S_k})^2} d12=∑k=1n(Skxk−yk)2
其中 S k S_k Sk为第 k k k维度的标准差:
S k = ∑ i = 1 n ( x k i − M k i ) 2 n S_k=\sqrt{\frac{\sum_{i=1}^n(x_{ki}-M_{ki})^2}{n}} Sk=n∑i=1n(xki−Mki)2
说明: x k i x_{ki} xki为第 k k k维度,第 i i i个样本
其中 M k M_k Mk为第 k k k维度的均值
M k = ∑ i = 1 n x k i n M_k=\frac{\sum_{i=1}^nx_{ki}}{n} Mk=n∑i=1nxki
如果将方差的倒数看成一个权重,也可称之为加权欧氏距离
3.6余弦距离
几何中,夹角余弦可用来衡量两个向量方向的差异,机器学习中,借用这一概念,来衡量样本向量之间的差异。
-
二维空间中向量 A ( x i , x 2 ) A(x_i,x_2) A(xi,x2)与 B ( y 1 , y 2 ) B(y_1,y_2) B(y1,y2)的夹角余弦公式:
c o s ( θ ) = x 1 y 1 + x 2 y 2 x 1 2 + x 2 2 + y 1 2 + y 2 2 cos(\theta)=\frac{x_1y_1+x_2y_2}{\sqrt{x_1^2+x_2^2}+\sqrt{y_1^2+y_2^2}} cos(θ)=x12+x22+y12+y22x1y1+x2y2
-
两个n维样本点 a ( x 1 , x 2 , ⋯ , x n ) a(x_1,x_2,\cdots,x_n) a(x1,x2,⋯,xn)与 b ( y 1 , y 2 , ⋯ , y n ) b(y_1,y_2,\cdots,y_n) b(y1,y2,⋯,yn)的夹角余弦公式:
c o s ( θ ) = a ⋅ b ∣ a ∣ ⋅ ∣ b ∣ cos(\theta)=\frac{a\cdot b}{|a|\cdot|b|} cos(θ)=∣a∣⋅∣b∣a⋅b
其中:
a ⋅ b a\cdot b a⋅b为向量 a a a与 b b b的点乘(内积)
∣ a ∣ |a| ∣a∣, ∣ b ∣ |b| ∣b∣分别为两个向量的模
即:
c o s ( θ ) = ∑ k = 1 n x k y k ∑ k = 1 n x k 2 ∑ k = 1 n y k 2 cos(\theta)=\frac{\sum_{k=1}^nx_ky_k}{\sqrt{\sum_{k=1}^nx_k^2}\sqrt{\sum_{k=1}^ny_k^2}} cos(θ)=∑k=1nxk2∑k=1nyk2∑k=1nxkyk
夹角余弦取值范围为[-1,1]。余弦越大表示两个向量的夹角越小,余弦越小表示两个向量的夹角越大。当两个向量的方向重合时余弦取最大值1,当两个向量的方向完全相反时余弦取最小值-1
3.7汉明距离
两个等长字符串s1与s2的汉明距离为:将其中一个变为另外一个所需要做的最小字符替换次数
3.8杰卡德距离
杰卡德相似系数:两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示:
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B)=\frac{|A\cap B|}{|A\cup B|} J(A,B)=∣A∪B∣∣A∩B∣
杰卡德距离:与杰卡德相似系数相反,用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度:
J δ ( A , B ) = 1 − J ( A , B ) = ∣ A ∪ B ∣ − ∣ A ∩ B ∣ ∣ A ∪ B ∣ J_{\delta}(A,B)=1-J(A,B)=\frac{|A\cup B|-|A\cap B|}{|A\cup B|} Jδ(A,B)=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣
3.9马氏距离
- 相对于分散性的距离判断就是马氏距离
四.K值的选择
K值过小
容易受到异常点的影响
K值过大
受到样本均衡的问题
K值选择问题
- 选择较小的k值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测起作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单;
- K=N(N为训练样本数),则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用的信息。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是把训练数据再分成两组:训练集和验证集)来选择最优的K值。对这个简单的分类器进行泛化,用核方法把这个线性模型扩展到非线性的情况,具体方法是把低维数据集映射到高维特征空间。
近似误差:对现有训练集的训练误差,关注训练集,如果近似误差过小可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。模型本身不是最接近最佳的模型。
估计误差:可以理解为对测试集的测试误差,关注测试集,估计误差小说明对未知数据的预测能力好,模型本身最接近最佳模型。
五.kd树
为了提高KNN搜索的效率,可以考虑用特殊的结构存储训练数据,以减少计算距离的次数
5.1kd树简介
5.1.1什么是kd树
根据KNN每次需要预测一个点时,我们都需要计算训练数据集里每个点到这个点的距离,然后选出距离最近的k个点进行投票。当数据集很大时,这个计算成本非常高,针对N个样本,D个特征的数据集,其算法复杂度为 O ( D N 2 ) O(DN^2) O(DN2)。
kd树:为了避免每次都重新计算一遍距离,算法会把距离信息保存在一棵树中,这样在计算之前从树里查询距离信息,尽量避免重新计算。其基本原理是,**如果A和B距离很远,B和C距离很近,那么A和C的距离也很远。**有了这个信息,就可以在合适的时候跳过距离远的点。这样优化后算法复杂度可下降到 O ( D N l o g N ) O(DNlogN) O(DNlogN)。
5.1.2原理
-
建立
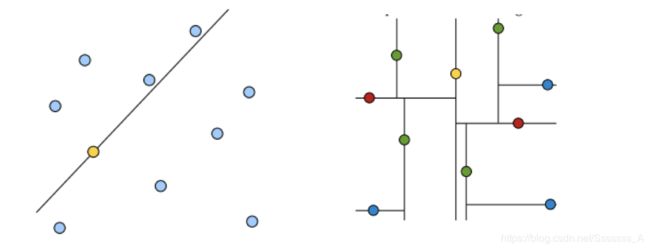
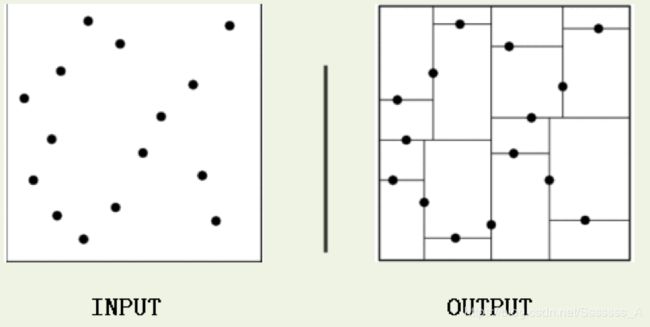
黄色的点作为根节点,上面的点归左子树,下面的点归右子树,接下来再不断地划分,分割的那条线叫做分割超平面,在一维中是一个点,二维中是线,三维中是一个面。
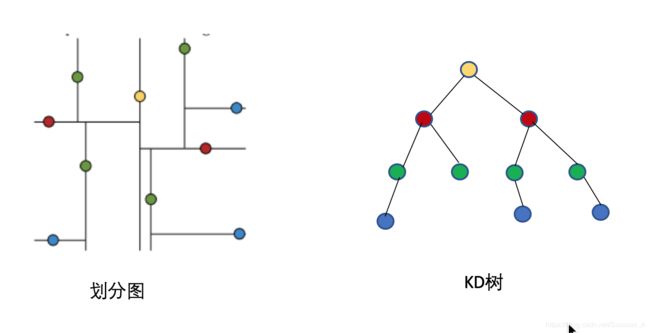
黄色节点就是Root节点,下一层是红色,再下一层是绿色,再下一层是蓝色。
-
最近邻域搜索
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树的每个节点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
5.2构造方法
- 构造根节点,使根节点对应于k维空间中包含所有实例点的超矩形区域;
- 通过递归的方法,不断地对k维空间进行切分,生成子节点。在超矩形区域上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子节点);这时,实例被分到两个子区域。
- 上述过程知道子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。
- 通常,循环的选择坐标轴对空间切分,选择训练实例点在坐标轴上的中位数为切分点,这样得到的kd树是平衡的(平衡二叉树:它是一棵空树,或其左子树和右子树的深度之差的绝对值不超过1,且它的左子树和右子树都是平衡二叉树)。
kd树中每个结点是一个向量,和二叉树按照树的大小划分不同的是,kd树每层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。在构建kd树时,关键需要解决两个问题:
- 选择向量的哪一维进行划分
- 如何划分数据
第一个问题的简单解决办法是随机选择某一维或按顺序选择,但是更好的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差来衡量)。好的划分方法可以使得构建的树更加平衡,可以每次选择中位数来进行划分,这样问题2也迎刃而解。
5.3案例
5.3.1树的建立
给定一个二维空间数据集:T = {(2, 3), (5, 4), (9, 6), (8, 1), (7, 2)},构造一个平衡dk树。
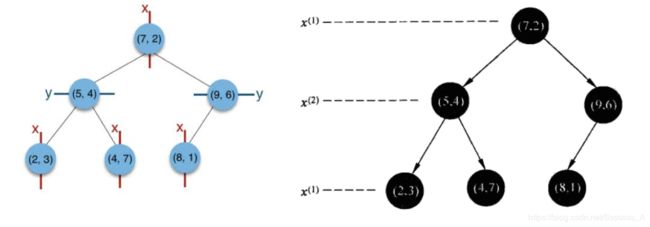
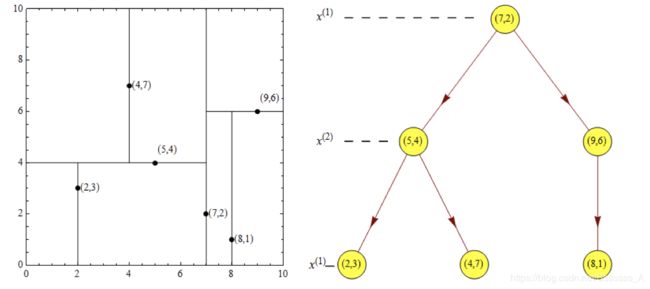
根节点对应包含数据集T的矩形,选择x(1)轴,6个数据点的x(1)坐标中位数是6,这里选最接近的(7, 2)点,以平面x(1)=7将空间分为左、右两个子矩形(子节点);接着左矩形以x(2)=4分为两个子矩形(左矩形中{(2, 3), (5, 4), (4, 7)}点的x(2)坐标中位数正好为4),右矩形以x(2)=6分为两个子矩形,如此递归,最后得到下图所示的特征空间划分和kd树。
5.3.2最近邻域的搜索
假设标记为星星的点是 test point, 绿色的点是找到的近似点,在回溯过程中,需要用到一个队列,存储需要回溯的点,在判断其他子节点空间中是否有可能有距离查询点更近的数据点时,做法是以查询点为圆心,以当前的最近距离为半径画圆,这个圆称为候选超球(candidate hypersphere),如果圆与回溯点的轴相交,则需要将轴另一边的节点都放到回溯队列里面来。
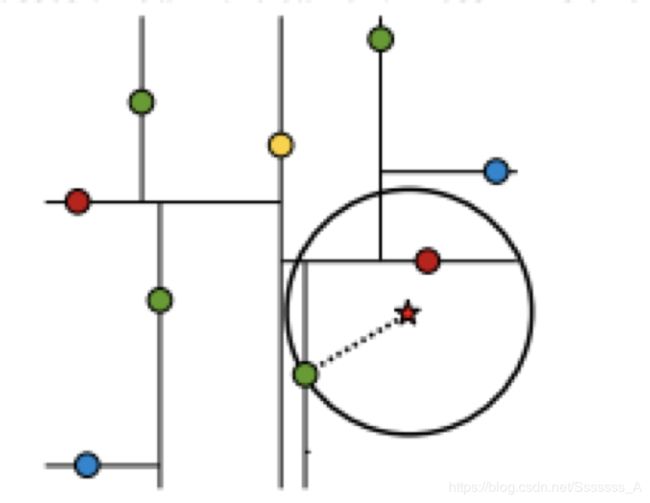
样本集{(2,3),(5,4), (9,6), (4,7), (8,1), (7,2)}
-
查找点(2.1, 3.1)
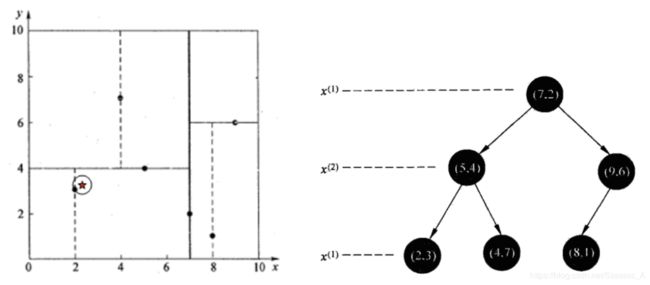
在(7,2)点测试到达(5,4),在(5,4)点测试到达(2,3),然后search_path中的结点为<(7,2),(5,4), (2,3)>,从search_path中取出(2,3)作为当前最佳结点nearest, dist为0.141; 然后回溯至(5,4),以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆,并不和超平面y=4相交,如上图,所以不必跳到结点(5,4)的右子空间去搜索,因为右子空间中不可能有更近样本点了。
于是再回溯至(7,2),同理,以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆并不和超平面x=7相交,所以也不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2.1,3.1)的最近邻点,最近距离为0.141。
-
查找点(2, 4.5)
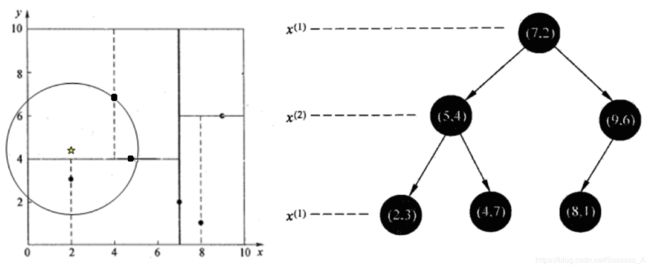
在(7,2)处测试到达(5,4),在(5,4)处测试到达(4,7)【优先选择在本域搜索】,然后search_path中的结点为<(7,2),(5,4), (4,7)>,从search_path中取出(4,7)作为当前最佳结点nearest, dist为3.202; 然后回溯至(5,4),以(2,4.5)为圆心,以dist=3.202为半径画一个圆与超平面y=4相交,所以需要跳到(5,4)的左子空间去搜索。所以要将(2,3)加入到search_path中,现在search_path中的结点为<(7,2),(2, 3)>;另外,(5,4)与(2,4.5)的距离为3.04 < dist = 3.202,所以将(5,4)赋给nearest,并且dist=3.04。
回溯至(2,3),(2,3)是叶子节点,直接平判断(2,3)是否离(2,4.5)更近,计算得到距离为1.5,所以nearest更新为(2,3),dist更新为(1.5)
回溯至(7,2),同理,以(2,4.5)为圆心,以dist=1.5为半径画一个圆并不和超平面x=7相交, 所以不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2,4.5)的最近邻点,最近距离为1.5。
5.4总结
首先通过二叉树搜索(比较待查询节点和分裂节点的分裂维的值,小于等于就进入左子树分支,大于就进入右子树分支直到叶子结点),顺着“搜索路径”很快能找到最近邻的近似点,也就是与待查询点处于同一个子空间的叶子结点;
然后再回溯搜索路径,并判断搜索路径上的结点的其他子结点空间中是否可能有距离查询点更近的数据点,如果有可能,则需要跳到其他子结点空间中去搜索(将其他子结点加入到搜索路径)。
重复这个过程直到搜索路径为空。
六.案例:鸢尾花种类预测
6.1 scikit-learn数据集API介绍
- sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取x小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录
6.1.1 sklearn小数据集
-
sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
名称 数量 类别 3 特征 4 样本数量 150 每个类别数量 50
6.1.2 sklearn大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None, subject=‘train’)
- subject:‘train’或者’test’,'all’可选,选择要加载的数据集
- 训练集的“训练”,测试集的“测试”,两者的“全部”
6.2 sklearn数据集返回值介绍
- load和fetch返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据组,是[n_samples * n_features] 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名
6.3查看数据分布
通过创建一些图,以查看不同类别是如何通过特征来区分的。 在理想情况下,标签类将由一个或多个特征对完美分隔。 在现实世界中,这种理想情况很少会发生。
- seaborn介绍
- Seaborn 是基于 Matplotlib 核心库进行了更高级的 API 封装,可以让你轻松地画出更漂亮的图形。而 Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。
- seaborn.lmplot() 是一个非常有用的方法,它会在绘制二维散点图时,自动完成回归拟合
- sns.lmplot() 里的 x, y 分别代表横纵坐标的列名
- data= 是关联到数据集
- hue= 代表按照那个类分类显示
- fit_reg=是否进行线性拟合
6.4数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
数据集划分api
- sklearn.model_selection.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return 训练集特征值值, 测试集特征值 训练标签,测试标签(默认随机取)
七.特征工程-特征预处理
7.1特征预处理
7.1.1特征预处理定义
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
为什么要进行归一化/标准化?
- 特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
7.1.2包含内容(数值型数据的无量纲化)
- 归一化
- 标准化
7.1.3特征预处理API
sklearn.preprocessing
7.2归一化
7.2.1定义
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
7.2.2公式
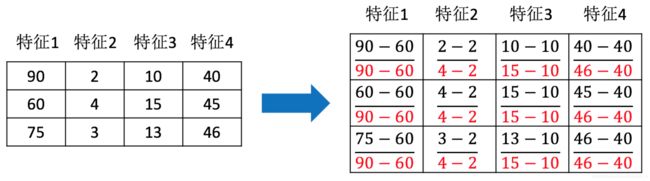
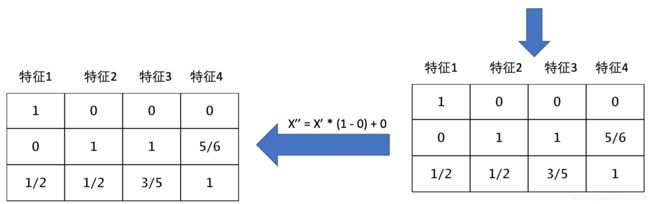
X ′ = x − m i n m a x − m i n X'=\frac{x-min}{max-min} X′=max−minx−min X ′ ′ = X ′ ∗ ( m x − m i ) + m i X''=X'*(mx-mi)+mi X′′=X′∗(mx−mi)+mi
作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值,默认mx为1, mi为0
可以通过下图来理解这一过程:
7.2.3API
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
- feature_range 映射到的区间, 默认0~1
- MinMaxScalar.fit_transform(X)
- X:numpy array格式的数据[n_samples, n_features]
- 返回值:转换后的形状相同的array
7.2.4数据计算
我们对以下数据进行运算,在dating.txt中。保存的就是之前的约会对象数据
# dating.txt
milage,Liters,Consumtime,target
40920, 8.326976, 0.953952, 3
14488, 7.153469, 1.673904, 2
26052, 1.441871, 0.805124, 1
75136, 13.147394, 0.428964,1
38344, 1.669788, 0.134296, 1
-
实例化MinMaxScalar
-
通过fit_transform转换
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
data = pd.read_csv("dating.txt")
print(data)
# 1、实例化一个转换器类
transfer = MinMaxScaler(feature_range=(2, 3))
# 2、调用fit_transform
data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])
print("最小值最大值归一化处理的结果:\n", data)
return None
返回结果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
4 38344 1.669788 0.134296 1
最小值最大值归一化处理的结果:
[[2.43582641 2.58819286 2.53237967]
[2. 2.48794044 3. ]
[2.19067405 2. 2.43571351]
[3. 3. 2.19139157]
[2.3933518 2.01947089 2. ]]
7.2.5归一化总结
最大最小值是变化的,另外,最大最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
7.3标准化
7.3.1定义
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
7.3.2公式
X ′ = x − m e a n σ X'=\frac{x-mean}{\sigma} X′=σx−mean
作用于每一列,mean为平均值,σ为标准差
- 对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
- 对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
7.3.3 API
- sklearn.preprocessing.StandardScaler( )
- 处理之后每列来说所有数据都聚集在均值0附近标准差差为1
- StandardScaler.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
7.3.4数据计算
同样对上面数据进行计算
- 实例化StandardScalar
- 通过fit_transform转换
def stand_demo():
data = pd.read_csv("dating.txt")
print(data)
# 1、实例化一个转换器类
transfer = StandardScaler()
# 2、调用fit_transform
data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])
print("标准化的结果:\n", data)
print("每一列特征的平均值:\n", transfer.mean_)
print("每一列特征的方差:\n", transfer.var_)
return None
返回结果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
4 38344 1.669788 0.134296 1
标准化的结果:
[[ 0.0947602 0.44990013 0.29573441]
[-1.20166916 0.18312874 1.67200507]
[-0.63448132 -1.11527928 0.01123265]
[ 1.77297701 1.54571769 -0.70784025]
[-0.03158673 -1.06346729 -1.27113187]]
每一列特征的平均值:
[3.8988000e+04 6.3478996e+00 7.9924800e-01]
每一列特征的方差:
[4.15683072e+08 1.93505309e+01 2.73652475e-01]
7.3.5标准化总结
在已有足够样本足够多的情况下比较稳定,适合现代嘈杂大数据场景
八.鸢尾花种类预测流程实现
8.1再识K近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’, metric=‘minkowski’, p=2)
- n_neighbors:
- int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}
- 快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索
- brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时
- kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高
- ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体
- 快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索
- metric :
- 距离度量, 一般来说默认的欧式距离(即p=2的闵可夫斯基距离)
- p: 距离度量参数 metric 附属参数,只用于闵可夫斯基距离和带权重闵可夫斯基距离中p值的选择,p=1为曼哈顿距离, p=2为欧式距离。默认为2
- n_neighbors:
8.2案例:鸢尾花种类预测
-
导入模块
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier -
先从sklearn当中获取数据集,然后进行数据集的分割
# 获取数据集 iris = load_iris() # 数据基本处理 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22) -
进行数据标准化
- 特征值的标准化
# 特征工程:标准化 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.fit_transform(x_test) -
模型进行训练预测
# 机器学习:模型训练 estimator = KNeighborsClassifier(n_neighbors=9) estimator.fit(x_train, y_train) # 模型评估 # 方法一:比对真实值和预测值 y_predict = estimator.predict(x_test) print("预测结果为:\n", y_predict) print("比对真实值和预测值:\n", y_predict == y_test) # 方法二:直接计算准确率 score = estimator.score(x_test, y_test) print("准确率为:\n", score)
九.交叉验证,网格搜索
9.1交叉验证
9.1.1为什么要需要交叉验证
为了让被评估的模型更加准确可信
9.1.2什么是交叉验证
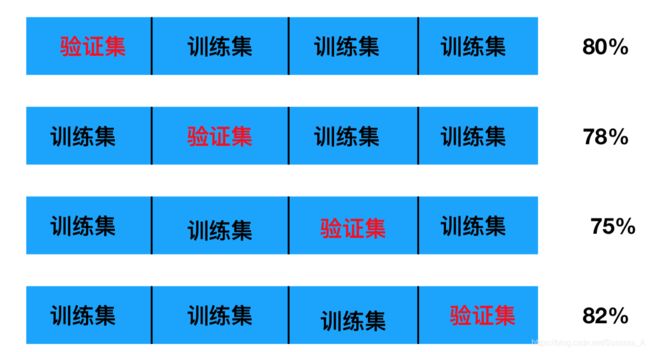
交叉验证:将拿到的训练数据,分为训练和验证集。比如:将数据分成四份,其中一份作为验证集,然后经过四组测试,每次都更换不同的验证集。即得到四组模型的结果,取平均值作为结果,又称四折交叉验证。
- 训练集:训练集+验证集
- 测试集:测试集
9.2网格搜索
通常情况下,有很多参数需要手动指定的(比如k-近邻算法中的k值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型
9.3相关API
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
- 结果分析:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
9.4鸢尾花案例增加k值调优
-
使用GridSearchCV构建估计器
# 获取数据集 iris = load_iris() # 数据集基本处理--划分数据集 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22) # 特征工程:标准化 # 实例化一个转换器 transfer = StandardScaler() # 调用fit_transform x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # KNN预估器流程 # 实例化预估器类 estimator = KNeighborsClassifier() # 模型选择与调优--网格搜索和交叉验证 # 准备要调的超参数 param_dict = {"n_neighbors": [1, 3, 5]} estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3) # fit数据进行训练 estimator.fit(x_train, y_train) # 评估模型效果 # 方法1:比对预测结果和真实值 y_predict = estimator.predict(x_test) print("比对预测结果和真实值:\n", y_predict == y_test) # 方法2:直接计算准确率 score = estimator.score(x_test, y_test)
十.预测facebook签到位置
10.1项目描述
facebook创建一个10公里*10公里的100平方公里的人造世界, 这个世界约10万个地方
人们在这里生活, 他们每进入一个地方就会使用移动设备进行签到,
现在有10天的签到数据, 预测未来某个时间人们会在哪些地方签到.
10.2数据集介绍
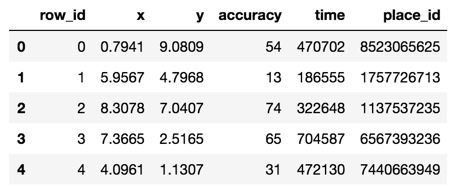
文件说明 train.csv, test.csv
row id:签入事件的id
x y:坐标
accuracy: 准确度,定位精度
time: 时间戳
place_id: 签到的位置,这也是你需要预测的内容
10.3步骤分析
- 对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
- 1 缩小数据集范围 DataFrame.query()
- 2 选取有用的时间特征
- 3 将签到位置少于n个用户的删除
- 分割数据集
- 标准化处理
- k-近邻预测
具体步骤:
# 1.获取数据集
# 2.基本数据处理
# 2.1 缩小数据范围
# 2.2 选择时间特征
# 2.3 去掉签到较少的地方
# 2.4 确定特征值和目标值
# 2.5 分割数据集
# 3.特征工程 -- 特征预处理(标准化)
# 4.机器学习 -- knn+cv
# 5.模型评估
10.4代码实现
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
# 获取数据集
facebook = pd.read_csv("./data/FBlocation/train.csv")
# 基本数据处理
# 缩小数据范围
facebook_data = facebook.query("x>2.0 & x<2.5 & y>2.0 & y<2.5")
# 选择时间特征
time = pd.to_datetime(facebook_data["time"], unit="s")
time = pd.DatetimeIndex(time)
facebook_data["day"] = time.day
facebook_data["hour"] = time.hour
facebook_data["weekday"] = time.weekday
# 去掉签到少的地方
place_count = facebook_data.groupby("place_id").count()
place_count = place_count[place_count["row_id"] > 3]
facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
# 确定特征值和目标值
x = facebook_data[["x", "y", "accuracy", "day", "hour", "weekday"]]
y = facebook_data["place_id"]
# 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 特征工程--特征预处理(标准化)
# 实例一个转化器
transfer = StandardScaler()
# 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 机器学习--knn+cv
# 实例化一个估计器
estimator = KNeighborsClassifier()
# 调用gridsearchCV
param_grid = {"n_neighbors": [1, 3, 5, 7, 9]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
# 模型训练
estimator.fit(x_train, y_train)
# 模型评估
# 基本评估方式
score = estimator.score(x_test, y_test)
print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test)
print("最后的预测值为:\n", y_predict)
print("预测值和真实值的对比情况:\n", y_predict == y_test)
# 使用交叉验证后的评估方式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n", estimator.cv_results_)