最小生成树,Prim,Kruskal算法主要思想,证明及C++实现
最小生成树:
任何只由G的边构成,并包含G的所有顶点的树称为G的生成树(G连通).加权无向图G的生成树的代价是该生成树的所有边的代码(权)的和.最小代价生成树是其所有生成树中代价最小的生成树。
实现最小生成树的算法常用的是Prim,Kruskal学校数据结构的书上讲解了这两大算法的思路及用C++实现,但关于其合理性的证明却略过去了,这里主要加上我自己的一些总结,证明一下,最后写个模版用。
Prim
基本思想:
1.在图G=(V, E)(V表示顶点,E表示边)中,从集合V中任取一个顶点(例如取顶点v0)放入集合 U中,这时 U={v0},集合T(E)为空。
2. 从v0出发寻找与U中顶点相邻(另一顶点在V中)权值最小的边的另一顶点v1,并使v1加入U。即U={v0,v1 },同时将该边加入集合T(E)中。
3. 重复2,直到U=V为止。
这时T(E)中有n-1条边,T = (U, T(E))就是一棵最小生成树。
用书上的图来举例...懒得画直接拍了
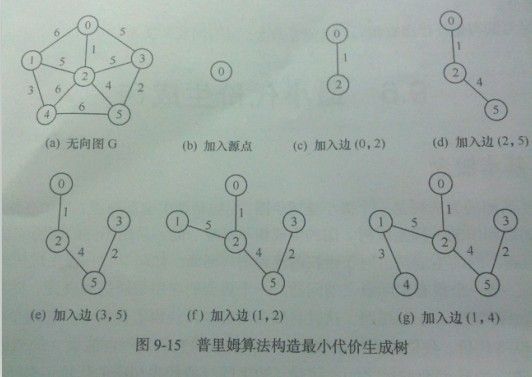
关键是每一步选取的边起点是已加入集合U中的点,终点是未加入集合U中的点,在所有这样的点中选取权值最小的一条,把未加入U的点加入U,这一条边加入树T上.
对于这一贪心策略的证明:
首先,一定有一个最优解包含了权值最小的边e_0(prim的第一步),因为如果不是这样,那么最优的解不包含e_0,把e_0加进去会形成一个环,任意去掉环里比e_0权值大的一条边,这样就构造了更优的一个解,矛盾.
用归纳法,假设prim的前k步选出来的边e_0,…, e_k-1是最优解的一部分,用类似的方法证明prim的方法选出的e_k一定也能构造出最优解。
C++实现:
朴素的邻接矩阵...
int N,dis[MAX+10][MAX+10];//点的个数及每两个点之间的距离
int prim()
{
int s=1;//源点,最开始为第一个
int num=1;//已加入MST的点的个数,用于判断循环是否结束
int sum_w=0;//MST的权值和
int min_w;//每次加入MST的边的权值
int flag;//与MST中点形成符合prim规则的不在MST中的点的序号
int low_dis[MAX+5];//每个源点到其他味加入MST的点的最短距离
bool uni[MAX+5];//标记点是否已经加入MST
memset(uni,false;sizeof(uni));
memset(low_dis;INF;sizeof(low_dis));
uni[s]=true;
while(1)
{
if(num==N) break;
min_w=INF;
for(int i=2;i<=N;i++)
{
if(!uni[i]&&dis[i][s]
#include
using namespace std;
const int MAXV = 10001, MAXE = 100001, INF = (~0u)>>2;
struct edge{
int t, w, next;
}es[MAXE * 2];
int h[MAXV], cnt, n, m, heap[MAXV], size, pos[MAXV], dist[MAXV];
void addedge(int x, int y, int z)
{
es[++cnt].t = y;
es[cnt].next = h[x];
es[cnt].w = z;
h[x] = cnt;
}
void heapup(int k)
{
while(k > 1){
if(dist[heap[k>>1]] > dist[heap[k]]){
swap(pos[heap[k>>1]], pos[heap[k]]);
swap(heap[k>>1], heap[k]);
k>>=1;
}else
break;
}
}
void heapdown(int k)
{
while((k<<1) <= size){
int j;
if((k<<1) == size || dist[heap[(k<<1)]] < dist[heap[(k<<1)+1]])
j = (k<<1);
else
j = (k<<1) + 1;
if(dist[heap[k]] > dist[heap[j]]){
swap(pos[heap[k]], pos[heap[j]]);
swap(heap[k], heap[j]);
k=j;
}else
break;
}
}
void push(int v, int d)
{
dist[v] = d;
heap[++size] = v;
pos[v] = size;
heapup(size);
}
int pop()
{
int ret = heap[1];
swap(pos[heap[size]], pos[heap[1]]);
swap(heap[size], heap[1]);
size--;
heapdown(1);
return ret;
}
int prim()
{
int mst = 0, i, p;
push(1, 0);
for(i=2; i<=n; i++)
push(i, INF);
for(i=1; i<=n; i++){
int t = pop();
mst += dist[t];
pos[t] = -1;
for(p = h[t]; p; p = es[p].next){
int dst = es[p].t;
if(pos[dst] != -1 && dist[dst] > es[p].w){
dist[dst] = es[p].w;
heapup(pos[dst]);
heapdown(pos[dst]);
}
}
}
return mst;
}
int main()
{
cin>>n>>m;
for(int i=1; i<=m; i++){
int x, y, z;
cin>>x>>y>>z;
addedge(x, y, z);
addedge(y, x, z);
}
cout< 算法分析:
使用邻接矩阵来保存图的话,时间复杂度是O(N^2),观察代码很容易发现,时间主要浪费在每次都要遍历所有点找一个最小距离的顶点,对于这个操作,我们很容易想到用堆来优化,使得每次可以在log级别的时间找到距离最小的点。下面的代码是一个使用二叉堆实现的堆优化Prim算法,代码使用邻接表来保存图。另外,需要说明的是,为了松弛操作的方便, 堆里面保存的顶点的标号,而不是到顶点的距离,所以我们还需要维护一个映射pos[x]表示顶点x在堆里面的位置。
使用二叉堆优化Prim算法的时间复杂度为O((V + E) log(V)) = O(E log(V)),对于稀疏图相对于朴素算法的优化是巨大的,然而100行左右的二叉堆优化Prim相对于40行左右的并查集优化Kruskal,无论是在效率上,还是编程复杂度上并不具备多大的优势。另外,我们还可以用更高级的堆来进一步优化时间界,比如使用斐波那契堆优化后的时间界为O(E + V log(V)),但编程复杂度也会变得更高。
Kruskal
基本思想:
假设WN=(V,{E})是一个含有n个顶点的连通网,则按照克鲁斯卡尔算法构造最小生成树的过程为:先构造一个只含n个顶点,而边集为空的子图,若将该子图中各个顶点看成是各棵树上的根结点,则它是一个含有n棵树的一个森林。之后,从网的边集E中选取一条权值最小的边,若该条边的两个顶点分属不同的树,则将其加入子图,也就是说,将这两个顶点分别所在的两棵树合成一棵树;反之,若该条边的两个顶点已落在同一棵树上,则不可取,而应该取下一条权值最小的边再试之。依次类推,直至森林中只有一棵树,也即子图中含有n-1条边为止。
同样用书上的图...

贪心策略的证明:
如果按Kruskal算法加入的边(u,v)在某一最优解T中不包含,那么T+(u,v)一定有且只有一个环,而且至少有一条边(u'.v')的权值大于等于(u,v).删除该边后,得到新树T'=T+(u,v)-(u',v')不会比T差,所以按Kruskal算法加入的边是最优的.