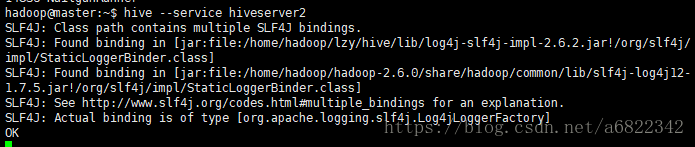
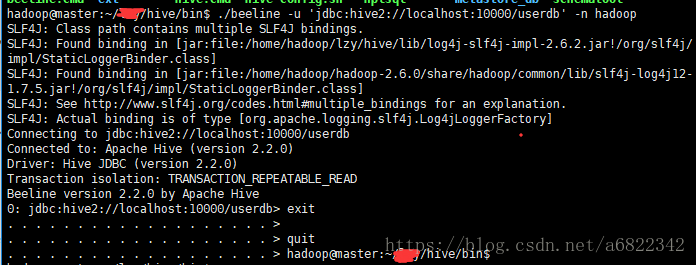
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 浅谈MapReduce
Android路上的人
Hadoop分布式计算mapreduce分布式框架hadoop
从今天开始,本人将会开始对另一项技术的学习,就是当下炙手可热的Hadoop分布式就算技术。目前国内外的诸多公司因为业务发展的需要,都纷纷用了此平台。国内的比如BAT啦,国外的在这方面走的更加的前面,就不一一列举了。但是Hadoop作为Apache的一个开源项目,在下面有非常多的子项目,比如HDFS,HBase,Hive,Pig,等等,要先彻底学习整个Hadoop,仅仅凭借一个的力量,是远远不够的。
- Presto【基础 01】简介+架构+数据源+数据模型
2401_84254343
程序员架构
一个Catalog包含Schema和Connector。例如,配置JMX的Catalog,通过JXMConnector访问JXM信息。当执行一条SQL语句时,可以同时运行在多个Catalog。Presto处理table时,是通过表的完全限定(fully-qualified)名来找到Catalog。例如,一个表的权限定名是hive.test_data.test,则test是表名,test_data是
- 大数据毕业设计hadoop+spark+hive知识图谱租房数据分析可视化大屏 租房推荐系统 58同城租房爬虫 房源推荐系统 房价预测系统 计算机毕业设计 机器学习 深度学习 人工智能
2401_84572577
程序员大数据hadoop人工智能
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。(1)Python所有方向的学习路线(
- 大数据之flink与hive
星辰_mya
大数据flinkhive
其实吧我不太想写flink,因为线上经验确实不多,这也是我需要补的地方,没有条件创造条件,先来一篇吧flink:高性能低延迟流批一体的分布式计算框架基于事件时间对实时数据精准处理快速响应支持批处理,高效离线分析和数据挖掘数据仓库的引擎丰富数据源/接收器,集成多种数据存储格式和源,比较常见就是咱们今天的主题hive了checkpoint恢复机制,故障恢复快速恢复计算任务分布式弹性扩展,据业务灵活增加
- hive血缘关系之输入表与目标表的解析
zxfBdd
hive大数据治理大数据
接了一个新需求:需要做数据仓库的血缘关系。正所谓兵来将挡水来土掩,那咱就动手吧。血缘关系是数据治理的一块,其实有专门的第三方数据治理框架,但考虑到目前的线上环境已经趋于稳定,引入新的框架无疑是劳民伤财,伤筋动骨,所以就想以最小的代价把这个事情给做了。目前我们考虑做的血缘关系呢只是做输入表和输出表,最后会形成一张表与表之间的链路图。这个东西的好处就是有助于仓库人员梳理业务,后面可能还会做字段之间的血
- 初级练习[3]:Hive SQL子查询应用
大数据深度洞察
Hivehivesqlhadoop数据仓库大数据数据库
目录环境准备看如下链接子查询查询所有课程成绩均小于60分的学生的学号、姓名查询没有学全所有课的学生的学号、姓名解释:没有学全所有课,也就是该学生选修的课程数<总的课程数。查询出只选修了三门课程的全部学生的学号和姓名环境准备看如下链接环境准备https://blog.csdn.net/qq_45115959/article/details/142057624?spm=1001.2014.3001.5
- Linux下载压缩包:tar.gz、zip、tar.bz2格式全攻略
promise524
Linuxlinux运维服务器后端bashshell
在Linux中,下载各种格式的压缩包(如.tar.gz、.zip、.tar.bz2等)通常使用命令行工具如wget和curl。1.使用wget下载压缩包wget是Linux中最常用的文件下载工具,支持HTTP、HTTPS、FTP等协议,可以直接从命令行下载文件。基本命令:wget[URL]下载.tar.gz文件wgethttps://test.com/archive.tar.gz此命令将从指定的U
- Anaconda版本和Python版本对应关系
纬领网络
pythonanaconda3
官网下载地址:https://repo.anaconda.com/archive/下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/anaconda3版本基础python版本Anaconda3-2024.06-1Python3.12.4Anaconda3-2024.02-1Python3.11.7Anaconda3-2023.09
- R语言包AMORE安装报错问题以及RStudio与Rtools环境配置
卡卡_R-Python
R语言数据分析与可视化r语言开发语言
在使用R语言进行AMORE安装时会遇到报错,这时候需要采用解决办法:'''AMORE包安装,需要离线官网下载安装包:Indexof/src/contrib/Archive/AMORE(r-project.org)https://cran.r-project.org/src/contrib/Archive/AMORE/一、出现的问题最近开始学习R语言,安装了最新版的R4.4.1和RStudio,但安
- 中级练习[3]:Hive SQL用户行为与商品销售数据分析
大数据深度洞察
Hivehive数据仓库大数据sql
目录1.用户累计消费金额及VIP等级查询1.1题目需求1.2代码实现2.首次下单后第二天连续下单的用户比率查询2.1题目需求2.2代码实现3.每个商品销售首年的年份、销售数量和销售金额统计3.1题目需求3.2代码实现1.用户累计消费金额及VIP等级查询1.1题目需求从订单信息表(order_info)中统计每个用户截止其每个下单日期的累积消费金额,以及每个用户在其每个下单日期的VIP等级。VIP等
- Python基础知识进阶之正则表达式_头歌python正则表达式进阶
前端陈萨龙
程序员python学习面试
最后硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是
- 编程常用命令总结
Yellow0523
LinuxBigData大数据
编程命令大全1.软件环境变量的配置JavaScalaSparkHadoopHive2.大数据软件常用命令Spark基本命令Spark-SQL命令Hive命令HDFS命令YARN命令Zookeeper命令kafka命令Hibench命令MySQL命令3.Linux常用命令Git命令conda命令pip命令查看Linux系统的详细信息查看Linux系统架构(X86还是ARM,两种方法都可)端口号命令L
- 博客园怎么了?
YYH1992
新年好,给大家拜个早年!今年来到安徽过年,无聊中,不知不觉中又来到博客园了(忠实粉丝哦),却发现一件奇怪的事情,请看截图难道博客园被挂马了?抑或其它问题?如果真有问题,还请dudu抓紧时间修正,免得影响我们园子的声誉!我要下线了,出去买回家的车票了,只能年后回家了。。。转载于:https://www.cnblogs.com/HollisYao/archive/2008/02/06/1065351.
- linux下文件的复制、移动与删除
搬砖中年人
一、文件复制命令cp命令格式:cp[-adfilprsu]源文件(source)目标文件(destination)cp[option]source1source2source3...directory参数说明:-a:是指archive的意思,也说是指复制所有的目录-d:若源文件为连接文件(linkfile),则复制连接文件属性而非文件本身-f:强制(force),若有重复或其它疑问时,不会询问用户
- 2024年最全使用Python求解方程_python解方程(1),字节面试官迟到
2401_84569545
程序员python学习面试
最后硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是
- 兼容 Trino Connector,扩展 Apache Doris 数据源接入能力|Lakehouse 使用手册
vvvae1234
apache
ApacheDoris内置支持包括Hive、Iceberg、Hudi、Paimon、LakeSoul、JDBC在内的多种Catalog,并为其提供原生高性能且稳定的访问能力,以满足与数据湖的集成需求。而随着ApacheDoris用户的增加,新的数据源连接需求也随之增加。因此,从3.0版本开始,ApacheDoris引入了TrinoConnector兼容框架。Trino/Presto作为业界较早应用
- SAP HANA
makaitai
BWsap数据库工具报表layer服务器
原文地址:http://LiuAlex.com/archives/1776也是刚刚开始学习HANA的一些知识,一边看书一遍做笔记,说到底无非是用自己的语言来理解标准帮组文档所讲解的意思,肯定有理解失误的地方,毕竟没有参加过标准培训,即使有培训,从老师那边来的知识也不可能是完整的传授过来,中间多少的知识遗漏是正常的,所以多看看HELP的文档,应该可以原汁原味的理解作者的意思。这张图片是从SAPHAN
- Hive SQL查询汇总分析
大数据深度洞察
Hivehivesqlhadoop数据仓库数据库大数据
目录SQL查询汇总分析成绩查询查询编号为“02”的课程的总成绩查询参加考试的学生个数分组查询查询各科成绩最高和最低的分查询每门课程有多少学生参加了考试(有考试成绩)查询男生、女生人数分组结果的条件查询平均成绩大于60分的学生的学号和平均成绩查询至少选修四门课程的学生学号查询同姓(假设每个学生姓名的第一个字为姓)的学生名单并统计同姓人数大于2的姓查询每门课程的平均成绩,结果按平均成绩升序排序,平均成
- RMAN-08137 rman delete archivelog force
jnrjian
数据库oracle
deleteforcearchiveloguntiltime'trunc(sysdate-4)'backedup1timestodevicetypedisk;SymptomsDatabaseAClonedtoDatabaseBonCloneserver.GoldenGateisConfiguredonSourcedatbaseA.DatabaseBwhichisclonedfromSourcedo
- hive表格统计信息不准确
weixin_41956627
hivehivehadoop数据仓库
问题描述有个hive分区表,orc存储格式,有个分区,查询selectcount(1)fromtablewheredt='yyyyMMdd'结果是0,但查询select*fromtablewheredt='yyyyMMdd'又能查到数据,去hdfs对应目录下查看,也能看到有数据文件解决执行如下sqlANALYZETABLEdb.table1PARTITION(dt='20240908')COMPU
- Conda创建环境失败:000和404错误
柚柚柚柚柚
conda
一、首先下载Anaconda1.打开网址Indexof/anaconda/archive/|清华大学开源软件镜像站|TsinghuaOpenSourceMirror,滑到最底部,下载Anaconda3-5.3.1-Linux-x86_64.sh。2.使用winscp拖动本地的Anaconda3-5.3.1-Linux-x86_64.sh到服务器的个人工作目录下。二、安装Anaconda软件,创建虚
- C#中两个问号的含义
weixin_30363981
测试
stringstrParam=Request.Params["param"]??"";取??左边的值,如果??左边的值为null则取右边的值转载于:https://www.cnblogs.com/shadowtale/archive/2012/10/19/2731152.html
- 如何下载各个版本的tomcat-比如tomcat9
耳边轻语999
tomcatjava
1,找到tomcat官网https://tomcat.apache.org/ApacheTomcat®-Welcome!找到tomcat9,或者archives1.1,找到对应版本1.2,找到小版本1.3,找到bin2,Indexof/dist/tomcat/tomcat-9/v9.0.39/bin2.1,下载对应的解压版本或者安装版本
- Percona-toolkit工具详解
小一_d28d
1.pt工具安装[root@master~]#yuminstall-ypercona-toolkit-3.1.0-2.el7.x86_64.rpm2.常用工具使用介绍2.1pt-archiver归档表#重要参数--limit100每次取100行数据用pt-archive处理--txn-size100设置100行为一个事务提交一次,--where'id>/root/db/checksum.logpt
- Ubuntu更换apt-get的下载源
愤愤的有痣青年
将以下内容替换/etc/apt/sources.list中的内容deb-srchttp://archive.ubuntu.com/ubuntuxenialmainrestricted#Addedbysoftware-propertiesdebhttp://mirrors.aliyun.com/ubuntu/xenialmainrestricteddeb-srchttp://mirrors.aliy
- apt 下载指定架构的包及离线安装的方法
错误重复学习记录
linux
#设置系统架构sudodpkg--add-architectureamd64#安装apt-rdependssudoaptinstallapt-rdepends#创建单独的目录mkdir-p/home/apt/postgresql-client-common#仅下载安装包sudoapt-getinstall--download-onlysudomv/var/cache/apt/archives/*/
- 游戏运营环节的一些关键转化率
turtle081025
数据分析游戏网络游戏运营
转载于http://www.gamedatas.com/archives/134转化率这个指标在各行各业的数据分析中运用的非常之广泛,例如:电商中就会存在,点击到订单生成的一系列转化率,传统的销售行业也会在做广告的时候考虑该广告能够转化多少订单,而在游戏行业,转化率同样是一个不容忽视的指标。一般来说,游戏运营的过程中主要会关注到这些转化率:1.下载-安装(激活)转化率;2.安装(激活)-注册转化率
- Python API操作RocketMQ
京城小筑
#Python编程python
背景:开发背景:公司相关报表需求需要将订单业务数据同步至RocketMQ中,由于需要保证开发的一致性(多个部门协同开发),所以采用读取Hive离线数据的方式通过PythonAPI写入RocketMQ中,便于其他开发同事调用~开发环境:本地调试系统MacPython3.7.5rocketmq0.4.4(Python模块)rocketmq-client-python2.0.0(Python模块)服务器
- hive搭建 -----内嵌模式和本地模式
lzhlizihang
hivehadoop
文章目录一、内嵌模式(使用较少)1、上传、解压、重命名2、配置环境变量3、配置conf下的hive-env.sh4、修改conf下的hive-site.xml5、启动hadoop集群6、给hdfs创建文件夹7、修改hive-site.xml中的非法字符8、初始化元数据9、测试是否成功10、内嵌模式的缺点二、本地模式(最常用)1、检查mysql是否正常2、上传、解压、重命名3、配置环境变量4、修改c
- Nginx负载均衡
510888780
nginx应用服务器
Nginx负载均衡一些基础知识:
nginx 的 upstream目前支持 4 种方式的分配
1)、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
2)、weight
指定轮询几率,weight和访问比率成正比
- RedHat 6.4 安装 rabbitmq
bylijinnan
erlangrabbitmqredhat
在 linux 下安装软件就是折腾,首先是测试机不能上外网要找运维开通,开通后发现测试机的 yum 不能使用于是又要配置 yum 源,最后安装 rabbitmq 时也尝试了两种方法最后才安装成功
机器版本:
[root@redhat1 rabbitmq]# lsb_release
LSB Version: :base-4.0-amd64:base-4.0-noarch:core
- FilenameUtils工具类
eksliang
FilenameUtilscommon-io
转载请出自出处:http://eksliang.iteye.com/blog/2217081 一、概述
这是一个Java操作文件的常用库,是Apache对java的IO包的封装,这里面有两个非常核心的类FilenameUtils跟FileUtils,其中FilenameUtils是对文件名操作的封装;FileUtils是文件封装,开发中对文件的操作,几乎都可以在这个框架里面找到。 非常的好用。
- xml文件解析SAX
不懂事的小屁孩
xml
xml文件解析:xml文件解析有四种方式,
1.DOM生成和解析XML文档(SAX是基于事件流的解析)
2.SAX生成和解析XML文档(基于XML文档树结构的解析)
3.DOM4J生成和解析XML文档
4.JDOM生成和解析XML
本文章用第一种方法进行解析,使用android常用的DefaultHandler
import org.xml.sax.Attributes;
- 通过定时任务执行mysql的定期删除和新建分区,此处是按日分区
酷的飞上天空
mysql
使用python脚本作为命令脚本,linux的定时任务来每天定时执行
#!/usr/bin/python
# -*- coding: utf8 -*-
import pymysql
import datetime
import calendar
#要分区的表
table_name = 'my_table'
#连接数据库的信息
host,user,passwd,db =
- 如何搭建数据湖架构?听听专家的意见
蓝儿唯美
架构
Edo Interactive在几年前遇到一个大问题:公司使用交易数据来帮助零售商和餐馆进行个性化促销,但其数据仓库没有足够时间去处理所有的信用卡和借记卡交易数据
“我们要花费27小时来处理每日的数据量,”Edo主管基础设施和信息系统的高级副总裁Tim Garnto说道:“所以在2013年,我们放弃了现有的基于PostgreSQL的关系型数据库系统,使用了Hadoop集群作为公司的数
- spring学习——控制反转与依赖注入
a-john
spring
控制反转(Inversion of Control,英文缩写为IoC)是一个重要的面向对象编程的法则来削减计算机程序的耦合问题,也是轻量级的Spring框架的核心。 控制反转一般分为两种类型,依赖注入(Dependency Injection,简称DI)和依赖查找(Dependency Lookup)。依赖注入应用比较广泛。
- 用spool+unixshell生成文本文件的方法
aijuans
xshell
例如我们把scott.dept表生成文本文件的语句写成dept.sql,内容如下:
set pages 50000;
set lines 200;
set trims on;
set heading off;
spool /oracle_backup/log/test/dept.lst;
select deptno||','||dname||','||loc
- 1、基础--名词解析(OOA/OOD/OOP)
asia007
学习基础知识
OOA:Object-Oriented Analysis(面向对象分析方法)
是在一个系统的开发过程中进行了系统业务调查以后,按照面向对象的思想来分析问题。OOA与结构化分析有较大的区别。OOA所强调的是在系统调查资料的基础上,针对OO方法所需要的素材进行的归类分析和整理,而不是对管理业务现状和方法的分析。
OOA(面向对象的分析)模型由5个层次(主题层、对象类层、结构层、属性层和服务层)
- 浅谈java转成json编码格式技术
百合不是茶
json编码java转成json编码
json编码;是一个轻量级的数据存储和传输的语言
在java中需要引入json相关的包,引包方式在工程的lib下就可以了
JSON与JAVA数据的转换(JSON 即 JavaScript Object Natation,它是一种轻量级的数据交换格式,非
常适合于服务器与 JavaScript 之间的数据的交
- web.xml之Spring配置(基于Spring+Struts+Ibatis)
bijian1013
javaweb.xmlSSIspring配置
指定Spring配置文件位置
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
/WEB-INF/spring-dao-bean.xml,/WEB-INF/spring-resources.xml,
/WEB-INF/
- Installing SonarQube(Fail to download libraries from server)
sunjing
InstallSonar
1. Download and unzip the SonarQube distribution
2. Starting the Web Server
The default port is "9000" and the context path is "/". These values can be changed in &l
- 【MongoDB学习笔记十一】Mongo副本集基本的增删查
bit1129
mongodb
一、创建复本集
假设mongod,mongo已经配置在系统路径变量上,启动三个命令行窗口,分别执行如下命令:
mongod --port 27017 --dbpath data1 --replSet rs0
mongod --port 27018 --dbpath data2 --replSet rs0
mongod --port 27019 -
- Anychart图表系列二之执行Flash和HTML5渲染
白糖_
Flash
今天介绍Anychart的Flash和HTML5渲染功能
HTML5
Anychart从6.0第一个版本起,已经逐渐开始支持各种图的HTML5渲染效果了,也就是说即使你没有安装Flash插件,只要浏览器支持HTML5,也能看到Anychart的图形(不过这些是需要做一些配置的)。
这里要提醒下大家,Anychart6.0版本对HTML5的支持还不算很成熟,目前还处于
- Laravel版本更新异常4.2.8-> 4.2.9 Declaration of ... CompilerEngine ... should be compa
bozch
laravel
昨天在为了把laravel升级到最新的版本,突然之间就出现了如下错误:
ErrorException thrown with message "Declaration of Illuminate\View\Engines\CompilerEngine::handleViewException() should be compatible with Illuminate\View\Eng
- 编程之美-NIM游戏分析-石头总数为奇数时如何保证先动手者必胜
bylijinnan
编程之美
import java.util.Arrays;
import java.util.Random;
public class Nim {
/**编程之美 NIM游戏分析
问题:
有N块石头和两个玩家A和B,玩家A先将石头随机分成若干堆,然后按照BABA...的顺序不断轮流取石头,
能将剩下的石头一次取光的玩家获胜,每次取石头时,每个玩家只能从若干堆石头中任选一堆,
- lunce创建索引及简单查询
chengxuyuancsdn
查询创建索引lunce
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Docume
- [IT与投资]坚持独立自主的研究核心技术
comsci
it
和别人合作开发某项产品....如果互相之间的技术水平不同,那么这种合作很难进行,一般都会成为强者控制弱者的方法和手段.....
所以弱者,在遇到技术难题的时候,最好不要一开始就去寻求强者的帮助,因为在我们这颗星球上,生物都有一种控制其
- flashback transaction闪回事务查询
daizj
oraclesql闪回事务
闪回事务查询有别于闪回查询的特点有以下3个:
(1)其正常工作不但需要利用撤销数据,还需要事先启用最小补充日志。
(2)返回的结果不是以前的“旧”数据,而是能够将当前数据修改为以前的样子的撤销SQL(Undo SQL)语句。
(3)集中地在名为flashback_transaction_query表上查询,而不是在各个表上通过“as of”或“vers
- Java I/O之FilenameFilter类列举出指定路径下某个扩展名的文件
游其是你
FilenameFilter
这是一个FilenameFilter类用法的例子,实现的列举出“c:\\folder“路径下所有以“.jpg”扩展名的文件。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
- C语言学习五函数,函数的前置声明以及如何在软件开发中合理的设计函数来解决实际问题
dcj3sjt126com
c
# include <stdio.h>
int f(void) //括号中的void表示该函数不能接受数据,int表示返回的类型为int类型
{
return 10; //向主调函数返回10
}
void g(void) //函数名前面的void表示该函数没有返回值
{
//return 10; //error 与第8行行首的void相矛盾
}
in
- 今天在测试环境使用yum安装,遇到一个问题: Error: Cannot retrieve metalink for repository: epel. Pl
dcj3sjt126com
centos
今天在测试环境使用yum安装,遇到一个问题:
Error: Cannot retrieve metalink for repository: epel. Please verify its path and try again
处理很简单,修改文件“/etc/yum.repos.d/epel.repo”, 将baseurl的注释取消, mirrorlist注释掉。即可。
&n
- 单例模式
shuizhaosi888
单例模式
单例模式 懒汉式
public class RunMain {
/**
* 私有构造
*/
private RunMain() {
}
/**
* 内部类,用于占位,只有
*/
private static class SingletonRunMain {
priv
- Spring Security(09)——Filter
234390216
Spring Security
Filter
目录
1.1 Filter顺序
1.2 添加Filter到FilterChain
1.3 DelegatingFilterProxy
1.4 FilterChainProxy
1.5
- 公司项目NODEJS实践0.1
逐行分析JS源代码
mongodbnginxubuntunodejs
一、前言
前端如何独立用nodeJs实现一个简单的注册、登录功能,是不是只用nodejs+sql就可以了?其实是可以实现,但离实际应用还有距离,那要怎么做才是实际可用的。
网上有很多nod
- java.lang.Math
liuhaibo_ljf
javaMathlang
System.out.println(Math.PI);
System.out.println(Math.abs(1.2));
System.out.println(Math.abs(1.2));
System.out.println(Math.abs(1));
System.out.println(Math.abs(111111111));
System.out.println(Mat
- linux下时间同步
nonobaba
ntp
今天在linux下做hbase集群的时候,发现hmaster启动成功了,但是用hbase命令进入shell的时候报了一个错误 PleaseHoldException: Master is initializing,查看了日志,大致意思是说master和slave时间不同步,没办法,只好找一种手动同步一下,后来发现一共部署了10来台机器,手动同步偏差又比较大,所以还是从网上找现成的解决方
- ZooKeeper3.4.6的集群部署
roadrunners
zookeeper集群部署
ZooKeeper是Apache的一个开源项目,在分布式服务中应用比较广泛。它主要用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步、集群管理、配置文件管理、同步锁、队列等。这里主要讲集群中ZooKeeper的部署。
1、准备工作
我们准备3台机器做ZooKeeper集群,分别在3台机器上创建ZooKeeper需要的目录。
数据存储目录
- Java高效读取大文件
tomcat_oracle
java
读取文件行的标准方式是在内存中读取,Guava 和Apache Commons IO都提供了如下所示快速读取文件行的方法: Files.readLines(new File(path), Charsets.UTF_8); FileUtils.readLines(new File(path)); 这种方法带来的问题是文件的所有行都被存放在内存中,当文件足够大时很快就会导致
- 微信支付api返回的xml转换为Map的方法
xu3508620
xmlmap微信api
举例如下:
<xml>
<return_code><![CDATA[SUCCESS]]></return_code>
<return_msg><![CDATA[OK]]></return_msg>
<appid><