Yolov2源码分析(一)
在阅读《YOLO9000: Better, Faster, Stronger》中,很多实现细节都没有在文中体现出来,所以看得也是云里雾里。从网上github上找源码,抽了两天时间看了一遍,一步步分析源码,同时针对个人的情况做出了一些修改。
Yolo官网:https://pjreddie.com/darknet/yolo/
Yolo源码:https://github.com/allanzelener/YAD2K
一、Loss function
在yolov2中并没有详细给出loss 函数,相对于yolov1,新的yolov2的loss函数有不小的改动,而这又是理解源代码的关键,先贴上之前yolov1的loss函数。
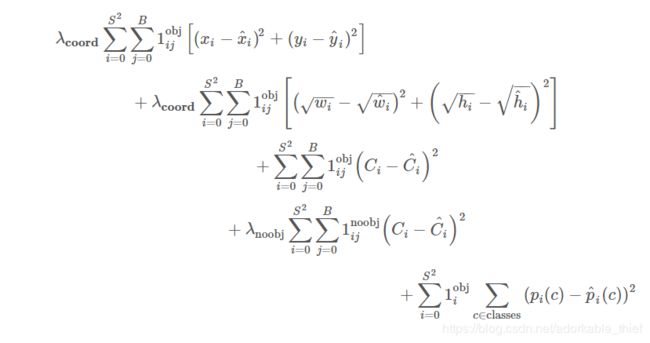
如yolov1一样,yolov2的误差分为置信度误差,分类误差,坐标误差:
置信度误差:关于置信度误差又分为object loss和no object loss,这里直接从源代码角度入手:
no_object_weights = (no_object_scale * (1 - object_detections) * (1 - detectors_mask))
no_objects_loss = no_object_weights * K.square(-pred_confidence)上述这段代码就是计算no object loss,每个grid cell内的bbox与ground truth的IOU 小于0.6的和ground truth落在某个grid cell内,除了该grid cell内的与ground truth IOU最大的anchor box,其他的都负责预测background。
接下来就是计算object loss:
if rescore_confidence:
objects_loss = (object_scale * detectors_mask *
K.square(best_ious - pred_confidence))
else:
objects_loss = (object_scale * detectors_mask *
K.square(1 - pred_confidence))这段代码很有意思,rescore_confidence决定了以何种方式去计算object loss,这里best_ious 是每个grid cell中的bbox与ground truth的iou值中最大的一个(注意这里是相对于整张图片的比例),当rescore_confidence为假的时候,执行第二种计算方式,这比较明显。但当rescore_confidence为真的时候,一直想不明白,如果有知道的朋友还请告知一些。
分类误差:
matching_classes = K.cast(matching_true_boxes[..., 4], 'int32')
matching_classes = K.one_hot(matching_classes, num_classes)
classification_loss = (class_scale * detectors_mask *
K.square(matching_classes - pred_class_prob))这里的matching_true_boxes与前面的detectors_mask一样,只不过这里是记录坐标和类别信息,没什么好说的,比较容易。唯一要说的是这里计算的是ground truth落在某个grid cell内,该grid cell内的与ground truth 的IOU最大的anchor box负责计算分类误差。
坐标误差
matching_boxes = matching_true_boxes[..., 0:4]
coordinates_loss = (coordinates_scale * detectors_mask *
K.square(matching_boxes - pred_boxes))注意下,此处的pred_boxes是相对单个grid cell的offset。这里计算anchor box 与 ground truth的坐标误差,在yolov1中,为了降低对大物体预测损失,通过对height和width取平方根法来缩小与小物体的差距,在这里文章是通过取对数,这在后面要说的preprocess_true_boxes函数中会有说明。
因此给出整个loss代码,具体的说明在代码中已有注释
def yolo_loss(args, anchors, num_classes, rescore_confidence = False, print_loss = False):
'''
describe:
实现损失函数部分
parameters:
args : (yolo_output, true_boxes, detectors_mask, matching_true_boxes)
yolo_output : 网络输出的特征向量,[batch,13,13,125]
true_boxes : ground truth, shape = [batch, num_true_boxes, 5]
detectors_mask : 0/1,标记是哪个候选框, shape = [batch, 13, 13, num_anchor, 1]
maching_true_boxes : shape = [batch, 13, 13, num_anchors, 5]
anchors : anchor boxes for model
'''
(yolo_output, true_boxes, detectors_mask, matching_true_boxes) = args
num_anchors = len(anchors)
object_scale = 5 # object 置信度误差
no_object_scale = 1 # background 置信度误差
class_scale = 1 # 类别误差系数
coordinates_scale = 1 # 坐标误差系数
pred_xy, pred_wh, pred_confidence, pred_class_prob = yolo_head(yolo_output, anchors, num_classes)
# yolo_out = [batch, 13, 13, 125]
yolo_output_shape = K.shape(yolo_output)
# features = [batch, 13, 13, 5, 25]
features = K.reshape(yolo_output, [-1, yolo_output_shape[1], yolo_output_shape[2], num_anchors, num_classes + 5])
# pred_boxes = [batch, 13, 13, 5, 4]
pred_boxes = K.concatenate((K.sigmoid(features[..., 0:2]), features[..., 2:4]), axis = -1)
# 增加维度方便后面与ground truth的比较,这里增加的是num_true_boxes
# pred_* = [batch, 13, 13, 5, 1, 2]
pred_xy = K.expand_dims(pred_xy, 4)
pred_wh = K.expand_dims(pred_wh, 4)
# 计算预测框的左上角点的坐标和右下角点的坐标
pred_wh_half = pred_wh / 2
pred_mins = pred_xy - pred_wh_half
pred_maxes = pred_xy + pred_wh_half
true_boxes_shape = K.shape(true_boxes)
# true_boxes = [batch, 1,1,1, num_truth_boxes, 5]
true_boxes = K.reshape(true_boxes,[true_boxes_shape[0], 1,1,1,true_boxes_shape[1],true_boxes_shape[2]])
# [batch, 1, 1, 1, num_truth, 2]
true_xy = true_boxes[..., 0:2]
true_wh = true_boxes[..., 2:4]
true_wh_half = true_wh / 2
true_mins = true_xy - true_wh_half
true_maxes = true_xy + true_wh_half
# 计算相交面积
# intersect_areas = [batch, 1, 1, 1, num_true_boxes, 1]
intersect_mins = K.maximum(pred_mins, true_mins)
intersect_maxes = K.minimum(pred_maxes, true_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_areas = intersect_wh[..., 0] * intersect_wh[..., 1]
# 计算相并面积
# union_areas = [batch, 1, 1, 1, num_true_boxes, 1]
pred_areas = pred_wh[..., 0] * pred_wh[..., 1]
true_areas = true_wh[..., 0] * true_wh[..., 1]
union_areas = pred_areas + true_areas - intersect_areas
# 计算IOU
# iou = [batch, 1, 1, 1, num_true_boxes, 1]
iou_scores = intersect_areas / union_areas
# best_ious = [batch, 1, 1, 1, 1, 1]
best_ious = K.max(iou_scores, axis = 4)
best_ious = K.expand_dims(best_ious)
# object_detections = [batch, 1, 1, 1, 1, 1]
object_detections = K.cast(best_ious > 0.6, K.dtype(best_ious))
# 这里计算background置信度误差, 首先如果该grid cell内的anchor box对应的bbox与ground truth的iou<0.6,再加上
# grid cell内没有ground truth落在这
no_object_weights = (no_object_scale * (1 - object_detections) * (1 - detectors_mask))
no_objects_loss = no_object_weights * K.square(- pred_confidence)
# 计算与ground truth相匹配的bbox的误差
if rescore_confidence:
objects_loss = (object_scale * detectors_mask *
K.square(best_ious - pred_confidence))
else:
objects_loss = (object_scale * detectors_mask *
K.square(1 - pred_confidence))
confidence_loss = objects_loss + no_objects_loss
# 计算类别误差
matching_classes = K.cast(matching_true_boxes[..., 4], 'int32')
matching_classes = K.one_hot(matching_classes, num_classes)
classification_loss = (class_scale * detectors_mask *
K.square(matching_classes - pred_class_prob))
matching_boxes = matching_true_boxes[..., 0:4]
# 计算坐标误差
coordinates_loss = (coordinates_scale * detectors_mask *
K.square(matching_boxes - pred_boxes))
confidence_loss_sum = K.sum(confidence_loss)
classification_loss_sum = K.sum(classification_loss)
coordinates_loss_sum = K.sum(coordinates_loss)
total_loss = 0.5 * (
confidence_loss_sum + classification_loss_sum + coordinates_loss_sum)
if print_loss:
total_loss = tf.Print(
total_loss, [
total_loss, confidence_loss_sum, classification_loss_sum,
coordinates_loss_sum
],
message='yolo_loss, conf_loss, class_loss, box_coord_loss:')
return total_loss
二.Darknet19网络结构
# Darknet-19网络结构
def Darknet19(X_input, num_anchors, num_classes):
'''
describe:
Darknet-19 网络结构
parameters:
X_input : 输入变量
num_anchors : anchors的数量
num_classes : class的类别数量
return:
net : 网络输出特征向量
'''
conv1_1 = Conv2D(32, (3,3), padding = 'SAME', name = 'conv1_1')(X_input)
bn1_1 = BatchNormalization(name = 'bn1_1')(conv1_1)
ac1_1 = LeakyReLU(alpha = 0.1)(bn1_1)
pool1_1 = MaxPool2D((2,2), (2,2), padding = 'SAME')(ac1_1)
conv2_1 = Conv2D(64, (3,3), padding = 'SAME', name = 'conv2_1')(pool1_1)
bn2_1 = BatchNormalization(name = 'bn2_1')(conv2_1)
ac2_1 = LeakyReLU(alpha = 0.1)(bn2_1)
pool2_1 = MaxPool2D((2,2), (2,2), padding = 'SAME')(ac2_1)
conv3_1 = Conv2D(128, (3,3), padding = 'SAME', name = 'conv3_1')(pool2_1)
bn3_1 = BatchNormalization(name = 'bn3_1')(conv3_1)
ac3_1 = LeakyReLU(alpha = 0.1)(bn3_1)
conv3_2 = Conv2D(64, (1,1), padding = 'SAME', name = 'conv3_2')(ac3_1)
bn3_2 = BatchNormalization(name = 'bn3_2')(conv3_2)
ac3_2 = LeakyReLU(alpha = 0.1)(bn3_2)
conv3_3 = Conv2D(128, (3,3), padding = 'SAME', name = 'conv3_3')(ac3_2)
bn3_3 = BatchNormalization(name = 'bn3_3')(conv3_3)
ac3_3 = LeakyReLU(alpha = 0.1)(bn3_3)
pool3_3 = MaxPool2D((2,2), (2,2), padding = 'SAME')(ac3_3)
conv4_1 = Conv2D(256, (3,3), padding = 'SAME', name = 'conv4_1')(pool3_3)
bn4_1 = BatchNormalization(name = 'bn4_1')(conv4_1)
ac4_1 = LeakyReLU(alpha = 0.1)(bn4_1)
conv4_2 = Conv2D(128, (1,1), padding = 'SAME', name = 'conv4_2')(ac4_1)
bn4_2 = BatchNormalization(name = 'bn4_2')(conv4_2)
ac4_2 = LeakyReLU(alpha = 0.1)(bn4_2)
conv4_3 = Conv2D(256, (3,3), padding = 'SAME', name = 'conv4_3')(ac4_2)
bn4_3 = BatchNormalization(name = 'bn4_3')(conv4_3)
ac4_3 = LeakyReLU(alpha = 0.1)(bn4_3)
pool4_3 = MaxPool2D((2,2), (2,2), padding = 'SAME')(ac4_3)
conv5_1 = Conv2D(512, (3,3), padding = 'SAME', name = 'conv5_1')(pool4_3)
bn5_1 = BatchNormalization(name = 'bn5_1')(conv5_1)
ac5_1 = LeakyReLU(alpha = 0.1)(bn5_1)
conv5_2 = Conv2D(256, (1,1), padding = 'SAME', name = 'conv5_2')(ac5_1)
bn5_2 = BatchNormalization(name = 'bn5_2')(conv5_2)
ac5_2 = LeakyReLU(alpha = 0.1)(bn5_2)
conv5_3 = Conv2D(512, (3,3), padding = 'SAME', name = 'conv5_3')(ac5_2)
bn5_3 = BatchNormalization(name = 'bn5_3')(conv5_3)
ac5_3 = LeakyReLU(alpha = 0.1)(bn5_3)
conv5_4 = Conv2D(256, (1,1), padding = 'SAME', name = 'conv5_4')(ac5_3)
bn5_4 = BatchNormalization(name = 'bn5_3')(conv5_4)
ac5_4 = LeakyReLU(alpha = 0.1)(bn5_4)
conv5_5 = Conv2D(512, (3,3), padding = 'SAME', name = 'conv5_5')(ac5_4)
bn5_5 = BatchNormalization(name = 'bn5_5')(conv5_5)
ac5_5 = LeakyReLU(alpha = 0.1)(bn5_5)
pool5_5 = MaxPool2D((2,2), (2,2), padding = 'SAME')(ac5_5)
conv6_1 = Conv2D(1024, (3,3), padding = 'SAME', name = 'conv6_1')(pool5_5)
bn6_1 = BatchNormalization(name = 'bn6_1')(conv6_1)
ac6_1 = LeakyReLU(alpha = 0.1)(bn6_1)
conv6_2 = Conv2D(512, (1,1), padding = 'SAME', name = 'conv6_2')(ac6_1)
bn6_2 = BatchNormalization(name = 'bn6_2')(conv6_2)
ac6_2 = LeakyReLU(alpha = 0.1)(bn6_2)
conv6_3 = Conv2D(1024, (3,3), padding = 'SAME', name = 'conv6_3')(ac6_2)
bn6_3 = BatchNormalization(name = 'bn6_3')(conv6_3)
ac6_3 = LeakyReLU(alpha = 0.1)(bn6_3)
conv6_4 = Conv2D(512, (1,1), padding = 'SAME', name = 'conv6_4')(ac6_3)
bn6_4 = BatchNormalization(name = 'bn6_4')(conv6_4)
ac6_4 = LeakyReLU(alpha = 0.1)(bn6_4)
conv6_5 = Conv2D(1024, (3,3), padding = 'SAME', name = 'conv6_5')(ac6_4)
bn6_5 = BatchNormalization(name = 'bn6_5')(conv6_5)
ac6_5 = LeakyReLU(alpha = 0.1)(bn6_5)
conv6_6 = Conv2D(1024, (3,3), padding = 'SAME', name = 'conv6_6')(ac6_5)
bn6_6 = BatchNormalization(name = 'bn6_6')(conv6_6)
ac6_6 = LeakyReLU(alpha = 0.1)(bn6_6)
conv6_7 = Conv2D(1024, (3,3), padding = 'SAME', name = 'conv6_7')(ac6_6)
bn6_7 = BatchNormalization(name = 'bn6_7')(conv6_7)
ac6_7 = LeakyReLU(alpha = 0.1)(bn6_7)
conv7_1 = Conv2D(1024, (3,3), padding = 'SAME', name = 'conv7_1')(ac6_7)
bn7_1 = BatchNormalization(name = 'bn7_1')(conv7_1)
ac7_1 = LeakyReLU(alpha = 0.1)(bn7_1)
num_feactures = num_anchors * (num_classes + 5)
net = Conv2D(num_feactures, (1,1), padding = 'SAME', name = 'conv7_2')(ac7_1)
return net这里为了让网络结构清晰,就自己敲了。这部分没什么好说的,在论文中输入图像的尺寸是416![]() 416
416
三.yolo_head
这个函数主要是处理之前网络的输出特征向量![]() ,因为特征向量输出的是,所以我们要经过一些计算过程,把输出映射成
,因为特征向量输出的是,所以我们要经过一些计算过程,把输出映射成![]() ,这里与yolov1的思想上,二者基本上没什么差距。
,这里与yolov1的思想上,二者基本上没什么差距。
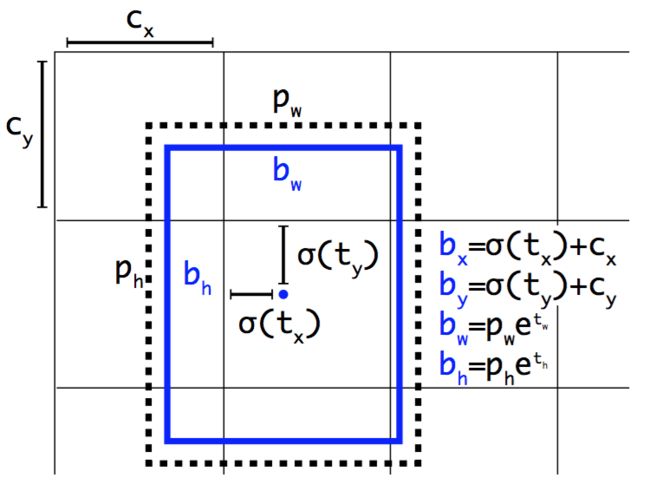
def yolo_head(features, anchors, num_classes):
'''
describe:
对Darknet19网络输出的特征向量进行处理
paramters:
features : shape = [batch, 13, 13, 5 * (20 + 5)], 网络输出的特征向量
anchors : 通常是在数据集上对训练样本进行聚类事先选定好的5个先验框
num_classes : 类别数目
return:
box_confidence : shape = [batch, 13, 13, 5, 1]
box_xy : shape = [batch, 13, 13, 5, 2]
box_wh : shape = [batch, 13, 13, 5, 2]
box_class_probs : shape = [batch, 13, 13, 5, 20]
'''
num_anchors = len(anchors)
# 在论文中指pw和ph
anchors_tensor = K.reshape(K.variable(anchors), [1,1,1,num_anchors, 2])
# [13, 13]
conv_dims = K.shape(features)[1:3]
# 因为features中的x,y相对于当前所属的grid cell内的offset, 因此计算相对整个grid cell的offset
conv_height_index = K.arange(0, stop=conv_dims[0])
conv_width_index = K.arange(0, stop=conv_dims[1])
conv_height_index = K.tile(conv_height_index, [conv_dims[1]])
conv_width_index = K.tile(K.expand_dims(conv_width_index, 0), [conv_dims[0], 1])
conv_width_index = K.flatten(K.transpose(conv_width_index))
conv_index = K.transpose(K.stack([conv_height_index, conv_width_index]))
conv_index = K.reshape(conv_index, [1, conv_dims[0], conv_dims[1], 1, 2])
conv_index = K.cast(conv_index, K.dtype(features))
features = K.reshape(features, [-1, conv_dims[0], conv_dims[1], num_anchors, num_classes + 5])
conv_dims = K.cast(K.reshape(conv_dims, [1,1,1,1,2]), K.dtype(features))
# 计算 (x,y,w,h,confidence,class_probs)
box_xy = K.sigmoid(features[..., 0:2])
box_wh = K.exp(features[..., 2:4])
box_confidence = K.sigmoid(features[..., 4:5])
box_class_probs = K.softmax(features[..., 5:])
# 调整box的坐标相对于整张图片的比例
box_xy = (box_xy + conv_index) / conv_dims
box_wh = box_wh * anchors_tensor / conv_dims
return box_confidence, box_xy, box_wh, box_class_probs代码中间一系列的index矩阵操作,目的就是让(x,y)相对于单个grid cell的,转化成相对整张图片的grid cell,当然比较简单的是可以使用循环实现,不过向量运算相对循环可能要快一点。最后又把坐标信息转化成了相对于整张图片的比例。
四、yolo_boxes_to_corners
def yolo_boxes_to_corners(box_xy, box_wh):
'''
describe:
将之前由box中点offset和width,height转化成候选框四个边角的坐标形式
'''
box_mins = box_xy - (box_wh / 2.)
box_maxes = box_xy + (box_wh / 2.)
return K.concatenate([
box_mins[..., 1:2],
box_mins[..., 0:1],
box_maxes[..., 1:2],
box_maxes[..., 0:1]
])因为之前我们得到的都是bbox的x,y,w,h,使用这个函数可以得到bbox的四个边角点,这样同样也能标识一个候选框。
五、preprocess_true_boxes
事先让ground truth 与对训练集进行聚类得到的5个 anchor box,这个函数就是实现对ground truth落在某个grid cell内,然后该grid cell内的5个anchor box 分别于ground truth计算IOU,之后选择最大的IOU的anchor box作为返回结果,结果输出的一个分别是对每个anchor box的选择情况,和对被选上的anchor box坐标类别信息的记录。
from keras.model import Model
import keras.backend as K
import tensorflow as tf
import numpy as np
def preprocess_true_boxes(true_boxes, anchors, image_size):
'''
describe:
针对每一个ground truth, 计算负责预测当前ground truth落在某个grid cell内与anchor box
的IOU值,并返回IOU值最大的anchor box, 这里需要注意是假设anchor box 与ground truth的中
心坐标点在同一个位置
parameters:
true_boxes : ground truth 列表, 每个ground truth 形如x,y,w,h,class, 这里的坐标在[0,1]区间,表示占原图的比例
anchors : anchors 列表, 每个anchor box形如w,h, 这里的坐标在[0,13],相对于整个grid cell的比值
image_size : 图像像素尺寸
returns:
返回负责预测ground_truth的grid cell内某个anchor box
detectors_mask : shape = [13, 13, 5, 1], 这个记录了被选择的anchor box
matching_true_boxes : shape = [13, 13, 5, 5]
'''
height, width = image_size
num_anchors = len(anchors)
# 图像尺寸必须是32的倍数, 论文中有说明,由于此处是412, 所以有每行每列有13个grid cell
assert (height % 32 == 0)
assert (width % 32 == 0)
# 转化成grid cell形式
conv_height = height // 32
conv_width = width // 32
num_box_params = true_boxes.shape[1]
# detectors_mask = [13, 13, 5, 1]
detectors_mask = np.zeros((conv_height, conv_width, num_anchors, 1), dtype = np.float32)
# matching_true_boxes = [13, 13, 5, 5]
matching_true_boxes = np.zeros((conv_height, conv_width,
num_anchors, num_box_params), dtype = np.float32)
# 遍历 ground truth box
for box in true_boxes:
box_class = box[4:5]
# 将 true_box 转化成相对于整个grid cell
box = box[0:4] * np.array([conv_width, conv_height, conv_width, conv_height])
# 记录box在第几行第几列个grid cell
i = np.floor(box[1]).astype('int')
j = np.floor(box[0]).astype('int')
best_iou = 0
best_anchor = 0
# 计算这个cell内5个anchor box与ground truth的Iou值, 选择IOU最大的anchor box
for k, anchor in enumerate(anchors):
box_maxes = box[2:4] / 2.0
box_mins = -box_maxes
anchor_maxes = anchor / 2.0
anchor_mins = -anchor_maxes
intersect_mins = np.maximum(box_mins, anchor_mins)
intersect_maxes = np.minimum(box_maxes, anchor_maxes)
intersect_wh = np.maximum(intersect_maxes - intersect_mins, 0.0)
intersect_area = intersect_wh[0] * intersect_wh[1]
box_area = box[2] * box[3]
anchor_area = anchor[0] * anchor[1]
iou = intersect_area / (box_area + anchor_area - intersect_area)
if iou > best_iou:
best_iou = iou
best_anchor = k
# 选择最大的IOU值的anchor box并记录在detectors_mask =
if best_iou > 0:
detectors_mask[i, j, best_anchor] = 1
adjusted_box = np.array(
[
box[0] - j, # x
box[1] - i, # y
np.log(box[2] / anchors[best_anchor][0]), # h
np.log(box[3] / anchors[best_anchor][1]), # w
box_class # confidence
],
dtype = np.float32)
matching_true_boxes[i, j, best_anchor] = adjusted_box
return detectors_mask, matching_true_boxes有两点需要注意一下,这里计算anchor box 与 ground truth的IOU值,此处是认为anchor box 与 ground truth在同一个中心点,即有共同的(x,y),因此会有上面代码所示的计算IOU方式。
另外一点就是对应之前说到的loss函数,这里是取log的方式。
六、yolo_filter_boxes, yolo_eval
下面的代码是在真正使用模型去检测图像时使用的,与训练过程没什么关系。
def yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold=.6):
'''通过给定阈值筛选掉一些bbox'''
box_scores = box_confidence * box_class_probs
box_classes = K.argmax(box_scores, axis = 1)
box_class_scores = K.max(box_scores, axis = -1)
prediction_mask = box_class_scores >= threshold
boxes = tf.boolean_mask(boxes, prediction_mask)
scores = tf.boolean_mask(box_class_scores, prediction_mask)
classes = tf.boolean_mask(box_classes, prediction_mask)
return boxes, scores, classesyolo_filter_box主要用来去掉一些低于设定阈值的bbox
def yolo_eval(yolo_outputs, image_shape, max_boxes = 10, score_threshold = 0.6, iou_threshold = 0.5):
box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs
# 将(x,y,h,w)转化成四个边角点的形式
boxes = yolo_boxes_to_corners(box_xy, box_wh)
boxes, scores, classes = yolo_filter_boxes(
box_confidence, boxes, box_class_probs, threshold = score_threshold)
height = image_shape[0]
width = image_shape[1]
# 将四个边角点的形式转化成图片真实像素信息
image_dims = K.stack([height, width, height, width])
image_dims = K.reshape(image_dims, [1,4])
boxes = boxes * image_dims
max_boxes_tensor = K.variable(max_boxes, dtype = 'int32')
K.get_session().run(tf.variables_initializer([max_boxes_tensor]))
# 非极大值抑制
nms_index = tf.image.non_max_suppression(
boxes, scores, max_boxes_tensor, iou_threshold = iou_threshold)
boxes = K.gather(boxes, nms_index)
scores = K.gather(scores, nms_index)
classes = K.gather(classes, nms_index)
return boxes, scores, classes然后通过yolo_eval 对剩下来的bbox进行进一步的筛选。因为对应某区域内可能会有多个bbox,所以采用NMS的方法,具体的算法原理其他博客中都有详细介绍,这里不再详述。
至此,整个yolo的核心部分代码已经讲述完毕,整个系列计划使用三个章节,下一次会具体讲述如何搭建可以自己训练的yolov2模型。同时鉴于个人能力实在有限,后续会逐步改进本篇博客。