Flink学习3-API介绍
Flink学习3-API介绍
系列文章目录
- Flink系列1-基础概念
- Flink系列2-安装和启动
- Flink系列3-API介绍
摘要
本文主要是介绍Flink的不同层次(level)API抽象,学习怎么通过API高效处理有状态性的计算无界和有界的数据流。
1 Flink多层API
Flink提供了三个不同层次的API,每种API在简洁和易表达间有自己的权衡,适用于不同的场景:
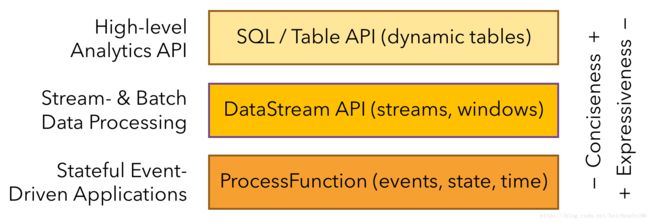
可以看到Flink一共有三个抽象层次的API,目测应该前两个会用的比较多,他们更加简洁但是表达性比较差。下面自底向上分别简要介绍下这三个API。
1.1 ProcessFunctions
看了上面的图我们知道ProcessFunctions最具表现力但是简洁性最差,是最底层的抽象API,他被主要用来处理包含单独事件的一个或两个输入流或者是分组到一个窗口类的事件,所以提供了对时间和状态的细粒度控制。ProcessFunctions可强制修改state、重注册未来某时触发回调函数的timer,所以可以实现复杂事件处理逻辑,这正适合很多有状态的事件驱动应用程序。
因为最近作者调研主要涉及FLink流式SQL API,这里没有详看,想要了解的请参见最后参考文档中给出的连接学习。
1.2 DataStream API
-
DataStream API提供了若干常用的流/批处理操作,如窗口等。
-
有Java和Scala的API可选,都是依赖一些底层的基本方法如map/aggregate等实现的。
下面示例展示session化一个click流然后对每个session中的点击数计数:
// 网站的点击流
DataStream<Click> clicks = ...
DataStream<Tuple2<String, Long>> result = clicks
// 将点击数与userId匹配,每一个点击就加1
.map(
// 定义一个实现了MapFunction接口的方法
new MapFunction<Click, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Click click) {
return Tuple2.of(click.userId, 1L);
}
})
// key by userId (field 0)
.keyBy(0)
// 定义30分钟间隙的session窗口
.window(EventTimeSessionWindows.withGap(Time.minutes(30L)))
// 对每个session点击计数,并定义为lambda函数
.reduce((a, b) -> Tuple2.of(a.f0, a.f1 + b.f1));
1.3 SQL&Table API
见第三章
2 库
Flink对常见的流式处理场景提供了若干内库,他们通常嵌入到API中,并非完全独立。 因此,他们可以从API的所有特性中受益,并与其他库集成:
2.1 Complex Event Processing (CEP)
该内库提供API来指定不同事件的模式,就像正则表达式或是状态机。模式识别是非常常见的事件流处理场景。
CEP库的应用包括网络入侵检测,业务流程监控和欺诈检测。
2.2 DataSet API
DataSet API是Flink的核心API,用来应对批处理应用。
2.3 Gelly
Gelly是一个可扩展的图形处理和分析库,他在DataSet API之上集成实现。
Gelly具有内置算法,如标签传播,三角枚举和页面排名,但也提供了一个简化自定义图算法实现的Graph API。
3 SQL&Table API
3.1 概述
Flink高层API有两种:Table级别和SQL级别。两种API都是统一的处理批和流数据,也就是说对于无界、实时的流或者有界、记录型的流有着同样的处理语义,产生同样的结果。
Table和SQL API采用了Apache Calcite进行语句解析、验证和查询调优。
他们可以和DataStream及DataSet API无缝集成,并支持用户自定义的标量,聚合和表值函数。
Flink的关系型API旨在简化数据分析,数据管道和ETL应用程序。
下面这个示例功能和DataStream API中的相同,也是展示一个SQL查询将一个点击流session化,然后对每个session中的点击数计数:
SELECT userId, COUNT(*)
FROM clicks
GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
这个SQL就是个流式处理SQL,简洁,高效。
3.2 限制
虽然flink 1.9.0支持DDL,但是尚不支持Time相关的元素。
可见:
- FLIP-66: Support Time Attribute in SQL DDL
- JIRA-Support Time Attribute in SQL DDL
3.3 连接外部系统
3.3.1 概述
可参考:
- custom table source/sink
DDL不行,我们可以用Connect to External Systems,直接读写外部数据源流批数据:
-
Table Source
读取外部数据,如数据库、key-value库、MQ、文件系统等。需要注册到Flink,然后可被Table/SQL API访问。
-
Table Sink
发送表数据到外部系统,如MySQL等需要注册到Flink,然后可被Table/SQL API访问。
-
支持的格式
CSV Parquet ORC等 -
Table Schema
定义表的schema,描述了怎么将Table Source的数据格式映射到Table API的schema,以及Table映射到Sink的方式。可暴露给SQL查询。 -
支持Time属性
可以使用一个或多个字段来提取或插入时间属性到Table Schema。
Flink连接外部系统可通过以下两种方式指定:
- 使用 Table & SQL API,搭配
org.apache.flink.table.descriptors下的内容 - 通过SQL客户端的YAML配置文件声明
一个Table & SQL API中连接外部数据源语句基本结构:
tableEnvironment
// 定义连接外部数据源
.connect(...)
// 定义解析外部数据源中数据格式
.withFormat(...)
// 定义流式数据表的schema
.withSchema(...)
// 定义输出表的更新模式(update modes)
.inAppendMode()
// 注册Source表到flink
.registerTableSource("MyTable")
// 注册Sink表到flink
.registerTableSink
// 使用相同名字注册Source和Sink表
.registerTableSourceAndSink
一个从Kafka中读Avro格式存储的数据的例子:
tableEnvironment
// 定义连接外部Kafka数据源的配置
.connect(
new Kafka()
.version("0.10")
.topic("test-input")
.startFromEarliest()
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092")
)
// 定义解析外部kafka数据源中数据格式
.withFormat(
new Avro()
.avroSchema(
"{" +
" \"namespace\": \"org.myorganization\"," +
" \"type\": \"record\"," +
" \"name\": \"UserMessage\"," +
" \"fields\": [" +
" {\"name\": \"timestamp\", \"type\": \"string\"}," +
" {\"name\": \"user\", \"type\": \"long\"}," +
" {\"name\": \"message\", \"type\": [\"string\", \"null\"]}" +
" ]" +
"}"
)
)
// 定义流式数据表的schema
.withSchema(
new Schema()
.field("rowtime", Types.SQL_TIMESTAMP)
.rowtime(new Rowtime()
.timestampsFromField("timestamp")
.watermarksPeriodicBounded(60000)
)
.field("user", Types.LONG)
.field("message", Types.STRING)
)
// 定义输出表的更新方式为append
.inAppendMode()
// 同时注册source和sink
.registerTableSource("MyUserSourceTable");
//registerTableSink可参考《深入理解flink》243页
.registerTableSink("MyUserSinkTable");
配置的连接属性会被转换为标准化的、基于String的key-value键值对。会基于Java SPI机制搜索唯一匹配的Table Factory来创建Table Source、Table Sink以及相应的format。
3.3.2 Table Connector
3.3.2.1 概述
用来定义外部数据源连接。不是所有都支持流/批,支持批的Connector支持的Update Mode也不尽相同。
3.3.2.2 File System Connector
![]()
可读写本地或分布式文件系统(如HDFS)。注意,File System Connector做流处理目前还是试验阶段。
例子如下:
.connect(
new FileSystem()
.path("file:///path/to/whatever") // required: path to a file or directory
)
3.3.2.3 Kafka Connector
![]()
Kafka Connector使得Flink可从Kafka中消费、写入数据。
-
关于Flink分区和Kafka分区关系
默认情况下,KafkaSink最多可以写入与其自身并行性(parallelism)一样多的Kafka分区,即每个并行的KafkaSink实例都写入一个Kafka分区。 为了将写操作分配到更多分区或自定义每行数据到分区的路由,可以提供自定义接收器分区程序(sinkPartitionerCustom)。循环分区器对于避免不平衡分区很有用, 但是,这将导致所有Flink实例与所有Kafka Broker节点之间的大量网络连接。
-
一致性保证
默认情况下,如果在启用检查点的时执行Flink,则KafkaSink会将具有至少一次(at least once)保证的数据提取到Kafka中。 -
Kafka 0.10+的Timestamp属性
Kafka0.10开始,数据就带了一个timestamp作为元数据的一部分,该字段含义是数据写入Kafka的时间。该字段可用作Flink rowtime,请参考Java/Scala的timestampsFromSource方法。 -
Kafka 0.11+版本
因为Flink1.7开始,Kafka Connector的定义就应该是独立于硬编码的Kafka version了,所以使用.version("universal")作为Kafka0.11开始的所有版本Kafka的通配符。 -
其他说明
- 在项目中应添加KafkaConnector相关依赖。

- 配置适合的format。
- 在项目中应添加KafkaConnector相关依赖。
例子:
.connect(
new Kafka()
// 必填。版本号("0.8", "0.9", "0.10", "0.11", "universal")
.version("0.11")
// 必填。订阅的topic
.topic("student_info")
// Kafka连接属性
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092")
.property("group.id", "testGroup")
// 可选如下。指定无法找到group对应的offset时,从哪儿开始消费。
.startFromEarliest()
.startFromLatest()
.startFromSpecificOffsets(...)
// 当Flink分区往kafka分区写入数据时需要配置。
// 默认。每个Flink分区最多被分配到一个Kafka分区
.sinkPartitionerFixed()
// 一个Flink分区会以轮询方式发送到Kafka各个分区
.sinkPartitionerRoundRobin()
// 自定义FlinkKafkaPartitioner
.sinkPartitionerCustom(MyCustom.class)
)
3.3.2.4 Elasticsearch Connector
3.3.2.5 HBase Connector
3.3.2.6 JDBC Connector
3.3.3 Table Schema
3.3.3.1 概述
Table Schema定义表的每个列的名字和类型,类似于SQL create table语句那样,用来暴露给SQL查询。此外,还可以指定如何将列与表数据编码schema的字段进行映射。当输入列无序时,Tabel Schema可清晰地定义列名、顺序和来源。Table Schema会和Table Format匹配来在Table数据输入和输出的过程中完成Schema转换。
此外, Table Schema还可指定Time属性提取器。
3.3.3.2 例子
简单例子:
.withSchema(
new Schema()
// 必填。和数据源中列顺序一致来指定Flink数据表的列
.field("MyField1", Types.INT)
.field("MyField2", Types.STRING)
.field("MyField3", Types.BOOLEAN)
)
复杂例子:
.withSchema(
new Schema()
.field("MyField1", Types.SQL_TIMESTAMP)
// 可选的,指定该列为processing-time
.proctime()
.field("MyField2", Types.SQL_TIMESTAMP)
// 可选的,指定该列为event-time(rowtime)
.rowtime(...)
.field("MyField3", Types.BOOLEAN)
// 可选的,指定该列的原始来源列为mf3
.from("mf3")
3.3.3.3 Rowtime
上述的.rowtime(...)本小节详细说下。
rowtime在flink里用来处理事件时间event-time。
采用Rowtime时,总是需要设置timestamp提取策略和watermark策略。
timestamp提取为rowtime例子如下:
.rowtime(
new Rowtime()
// 转换input中的某个LONG或SQL_TIMESTAMP类型的列为rowtime
.timestampsFromField("ts_field")
)
.rowtime(
new Rowtime()
// 使用input数据中的timestamp属性来转为rowtime,需要数据源支持,如Kafka 0.10+版本
.timestampsFromSource()
)
.rowtime(
new Rowtime()
// 为rowtime设置一个自定义的timestamp转换器
// ,该转换器必须实现自 org.apache.flink.table.sources.tsextractors.TimestampExtractor
.timestampsFromExtractor(...)
)
水位策略例子:
.rowtime(
new Rowtime()
// 为升序的rowtime设置watermark。
// 发出截止目前观察到的最大timestamp-1的watermark。
// timestamp等于最大timestamp的行不算迟到。
.watermarksPeriodicAscending()
)
.rowtime(
new Rowtime()
// 为rowtime设置一个内嵌的watermark,该rowtime属性在有限的时间间隔内是乱序的
// 发出截止目前观察到的最大timestamp减去指定延迟(毫秒)的watermark。
.watermarksPeriodicBounded(2000)
)
.rowtime(
new Rowtime()
// 设置一个内置水印策略,该策略指示应从DataStream API中保留水印,从而保留数据源中分配的水印。
.watermarksFromSource()
)
3.3.4 Table Formats
3.3.4.1 概述
一些外部数据系统支持不同的Table Formats,比如kafka或文件就支持其内存储的表的行使用CSV、JSON、Avro进行编码,所以需要指定Table Format来阐明外部数据源解析方式。
3.3.4.2 JSON Table Format
JSON格式允许读取和写入与给定的format schema相对应的JSON数据。format schema可用Flink type(SQl-like,映射到对应的SQL数据类型)、 JSON schema(适合复杂的嵌套数据结构)或目标表的schema(适合format schema等于table schema的场景,可自动派生出schema)来定义。
目前支持的JSON schema类型和Flink SQL类型如下:

Missing Field Handling: By default, a missing JSON field is set to null. You can enable strict JSON parsing that will cancel the source (and query) if a field is missing.
Make sure to add the JSON format as a dependency.
需要在项目中添加JSON依赖:
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-jsonartifactId>
<version>${flink.version}version>
dependency>
实例:
.withFormat(
new Json()
// 可选。当某个field缺失的时候,是否导致失败,默认false。
.failOnMissingField(true)
// 可选方式1。使用Flink数据类型定义,然后mapping映射解析为对应的type的类型信息来定义schema
// flink的ROW对应JSON的object结构,String对应VARCHAR等
.schema(Type.ROW(...))
// 可选方式2。使用JSON schema来定义,可支持非常复杂和嵌套的数据结构
.jsonSchema(
"{" +
" type: 'object'," +
" properties: {" +
" lon: {" +
" type: 'number'" +
" }," +
" rideTime: {" +
" type: 'string'," +
// 指定时间格式
" format: 'date-time'" +
" }" +
" }" +
"}"
)
// 可选方式3。可直接使用表的schema来解析
// 适用于Flink Table Schema和JSON Schema一致时
// 此时只需要定义Table Schema,就能确定字段名称、类型、位置顺序等
.deriveSchema()
)
3.3.5 Update Modes
3.3.5.1 概述
流式查询中,需要声明怎么执行动态表和外部Connector之间的转换,有以下模式:
-
Append Mode
仅交互INSERT操作数据 -
Retract Mode
交互ADD(编码了INSERT)和RETRACT(编码了DELETE和UPDATE)操作数据。与Upsert Mode相反,Retract Mode不能定义key。
每个UPDATE操作由两条消息组成,效率较低。
-
Upsert Mode
交互UPSERT(编码了INSERT和UPDATE)和DELETE操作数据。该模式需要一个唯一的key(可能是组合的),使用他来进行传播update。具体来说,外部连接器需要了解该唯一key属性,才能正确应用消息。
与Retract Mode的不同是,对Upsert Mode中的UPDATE变更使用单条消息进行编码,因此更有效率。
3.3.5.2 例子
.connect(...)
.inAppendMode() // otherwise: inUpsertMode() or inRetractMode()
每个connector支持哪些update mode,请参阅具体connector文档。
总结
这篇文章主要讲了一些Flink编程中用到的基本概念和API,为了更加深入理解,还要多学习下Example才行,请点击这里。
更多文档
- Flink-Training 在线学习
- 使用flink Table &Sql api来构建批量和流式应用(1)Table的基本概念
- flink入门实战总结
- Flink中的状态与容错
- flink DataStream API使用及原理
0xFF 参考文档
-
Streaming 101: The world beyond batch
-
Streaming 102: The world beyond batch
-
What is Apache Flink?
-
Flink实时性、容错机制、窗口等介绍
-
Flink事件时间处理和水印