Self-Attention Generative Adversarial Networks读书笔试
这是罗格斯大学和google brain的文章,是big-gan之前生成模型中的state of the art,而且big gan也是用了这个模型的结构。这篇文章逻辑十分严密,介绍也很详细,实验部分安排得相当不错,给出了很多可视化的结果用于分析。
文章的主要贡献有以下三点:
(1)提出了一个新的self-attention,解决了卷积层中中关注近邻信息的问题,并用可视化结果予以证明。
(2)在判别器和生成器中同时使用spectral normalization。
(3)对于判别器,使用较高的学习率,从而可以保证生成器和判别器可以更新比例为1:1,避免判别器更新比例大于生成器,从而影响训练的效率,我们最主要的目的是训练好的生成器,所以希望生成器迭代的次数尽可能高。
一、self-attention
现有的生成模型虽然可以产生逼真的图片,但是仍然存在一些不足。作者指出,现有的生成模型在生成具有更多纹理上面的效果好于生成具有更多结构的效果。比如:狗狗的皮肤的纹理会生成更加真实,而它的四肢这种结构生成效果则略显不如。作者提出了可能的原因:模型严重依赖卷积操作来学习不同区域之间的相关性信息,而卷积层具有局部感受野的特点阻碍了不同区域信息在很深的卷积层之间传播。对于小的卷积核,这种影响更为明显;对于大的卷积核,虽然可以减轻这种影响,其则会带来计算的大量增加,从而降低模型的效率。所以作者提出了self-attention的方法来解决这一问题,则一方面可以得到长范围的相关信息,同时避免了巨大的计算量增加。下面介绍self-attention的架构
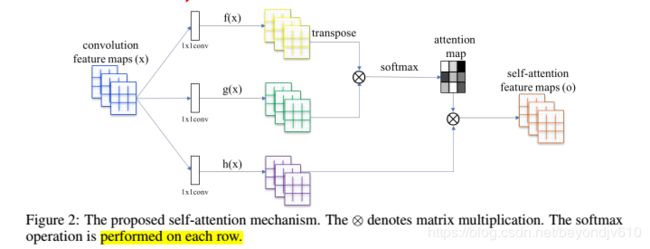
如Figure2所示,对于某一层得到的feature map,其通过三个1*1的卷积核W来降低通道数,其中f(x) = Wf * x,g(x) = Wg * x,其中Wf和Wg都是c*C,实验中c = C/8,这里的c和C都是代表通道数,c*C中第一个代表输出的通道数,第二个代表输入的通道数。然后,我们通过f(x)T*g(x)得到我们的attention map。对于下面部分,直接用一个C*C的卷积核得到h(x),将上面和下面的结果进行element-wise的相乘得到最后的输出o。
![]()
接下来,我们采用类似resnet的结构来得到最后的结果。(3)中o是我们attention得到的输出,前面的系数代表一个权重,x是attention结构的输入,这样我们采用类似resnet的结构来引入self-attention。
具体细节参见以下代码:
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)(X mean multiply)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)【0,2,1】进行了转置
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check【对每个通道的矩阵进行相乘然后再concate在一起】
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + xhttps://github.com/heykeetae/Self-Attention-GAN
对于o前面的参数lambda,我们初始化为0,相当于我们一开始不使用self-attention这个结构,作者解释这么做的原因是一开始我们只是学习一些简单的结构,所以不需要用到self-attention,后面再学习一些复杂的结构。在生成器和判别器中,作者搜引入了attention的结构。作者使用hinge version的函数。

二、稳定高效训练gan的方法
1.在生成器和判别器中同时使用spectral normalization的方法,该方法不引入新的超参数,同时计算的复杂度较低。spectral normalization同时在生成器和判别器中使用可以降低判别器更新次数与生成器更新次数之间的比,从而提高训练的效率,并且使得训练的过程更加稳定。
2.我们使用对于生成器和判别器使用不同的学习率,从而可以对于每一次判别器的迭代,使用更少的生成器的迭代。
三、评价指标
1.Inception score (IS)计算的是同一类的生成图片和真实图片之间的KL散度,该方法保证了模型生成的图片可以明确地判定为某一类,对于肉眼的相似性以及同个类里面的多样性要求不多。该指标越大说明结果越好。
2.FID计算生成的图片和真实图片在Inception-v3 network中的feature map(具体哪一层需要查看原文)的Wasserstein-2 distance,该评价指标与我们肉眼所看的结果更加契合。
四、实验的细节
图片的大小是128*128,在生成器和判别器中都使用conditional batch normalization。对于优化器,使用Adam,同时判别器的学习率为0.0004,生成器的学习率为0.0001.
五、实验结果
5.1验证模型稳定方法的有效性

从Figure 3可以看出,baseline仅仅在判别器中加上SN的话训练过程很不稳定,而在生成器中加了SN之后训练效果会稳定一些,然而在最后也出现了效果变差的情况,而当我们再加上TTUR(即生成器和判别器使用不同的学习率)则可以使得模型更加稳定,同时我们最终的效果也更好。
5.2 Self-attention机制

从Table1可以看出,我们使用attention会比baseline效果好,作者为了证明这个提升是来自于self-attention而不是来自于模型复杂度的增加,作者补充了一个实验,将self-attention的模块改为residual的模块,证实了self-attention的有效性。进一步地,从表格可以看出,对于大的卷积核使用self-attention效果会优于小的卷积核。

作者不仅从指标上进行比较分析,还对self-attention模块进行可结果的可视化。上图左边第一个图给出三个不同颜色的点代表我们要寻找的目标点,接下来三个点给出的是这三个点每个点对应的attention区域,越亮的部分代表其attention程度越高,而箭头所指的地方则是attention最高的部分。从图中可以看出,attention关注的点不仅仅是在目标点的周围,而是会根据纹理和结构信息选择重要的区域,从而解决了conv的long-range只能关注附近区域的问题。如右1的图,其蓝色的点对应的attention区域是另外一条腿,证明其可以帮助得到连接区域的结构信息。
5.3与state of the art的对比

作者最后将其提出的方法与state of the art的方法进行比较,可以看出其方法相对之前的方法有了明显的提升。
相关知识:
1.spectral normalization T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida. Spectral normalization for generative
adversarial networks. In ICLR, 2018
2.hinge version of the adversarial loss
3.IS T. Salimans, I. J. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved
techniques for training gans. In NIPS, 2016.
4.FID M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two
time-scale update rule converge to a local nash equilibrium. In NIPS, pages 6629–6640, 2017
5.generator里面如何加入attention:A. Odena, J. Buckman, C. Olsson, T. B. Brown, C. Olah, C. Raffel, and I. Goodfellow. Is
generator conditioning causally related to gan performance? In ICML, 2018.
疑惑:
我们使用对于生成器和判别器使用不同的学习率,从而可以对于每一次判别器的迭代,使用更少的生成器的迭代。但是我们使用的判别器的学习率却高过生成器的学习率,这么说应该是减少判别器的迭代才对吧??????